Hongzheng Chen Blog
缘生Halide
Feb 9th, 2019 0这篇文章主要谈谈由Halide这门图像处理领域专用语言(Domain Specific Language, DSL)中衍生出来的故事。 关于DSL的内容则请见领域特定语言。
Halide 1
一些概念
- 核(kernel):可以简单理解为循环体的主体部分
- 蒙版(stencil2):一种依据特定规则(pattern)更新的迭代核,难点在于复杂的依赖关系
- 应用:计算流体力学、PDE、雅可比核、Gauss-Seidel、图像处理、元胞自动机
- 流(stream):在时间上连续的一系列潜在无限的数据(potentially unlimited -> co-data)
- 流水线(pipeline):前者的输出是后者的输入
简介
图像处理结合了蒙版计算和流应用的挑战 – 多蒙版多阶段,但同一模板只用一次。
- 一个naive的实现和一个强优化过的实现往往能够差一个(或以上)数量级的性能。
- 通常通过专家手写优化来达到最高性能,但这样导致简单的流水变得非常复杂(C/cuda/intrinsics/汇编交织)。
- 而且结果是可移植性低(无法针对不同硬件架构),且无法与其他算法组合(composable)
- 库(library)和子程序(subroutine)也无法解决这个问题,因为很多重要的优化牵涉到跨阶段的融合(fusion for producer-consumer locality across stages)
现状是
- 大多流应用的优化只关注于1D的流,而图像处理中常见的2D、3D往往被忽视
- 针对流水线,传统的循环融合无法解决蒙版,需要复杂的局部性tradeoff
- 涉及到每个阶段的交替分配、执行、通信,因而称为流水线的调度(schedule) – 值when & where被计算
解决方案:
- 提升抽象层次
- 将算法定义(what)与执行策略(how)分离,提升便携性与可组合性
- 有效抽象+自动优化
动机
最简单的两阶段流水
alloc blurx[2048][3072]
for each y in 0..2048:
for each x in 0..3072:
blurx[y][x] = In[y][x-1] + In[y][x] + In[y][x+1]
alloc out[2046][3072]
for each y in 1..2047:
for each x in 0..3072:
out[y][x]=blurx[y-1][x] + blurx[y][x] + blurx[y+1][x]
交织不存储中间值,局部性好但是由于共享的blurx没有被重用,因此有冗余计算
alloc out[2046][3072]
for each y in 1..2047:
for each x in 0..3072:
alloc blurx[-1..1]
for each i in -1..1:
blurx[i]= In[y-1+i][x-1]+In[y-1+i][x]+In[y-1+i][x+1]
out[y][x] = blurx[0] + blurx[1] + blurx[2]
滑动窗口(sliding window),只计算每个blurx一次并存储;引入条件依赖,牺牲并行性
alloc out[2046][3072]
alloc blurx[3][3072]
for each y in -1..2047:
for each x in 0..3072:
blurx[(y+1)%3][x]=In[y+1][x-1]+In[y+1][x]+In[y+1][x+1]
if y < 1: continue
out[y][x] = blurx[(y-1)%3][x]
+ blurx[ y % 3 ][x]
+ blurx[(y+1)%3][x]
上述的策略存在的问题:
- 缺失局部性
- 冗余工作
- 有限并行性
一个更好的方式是在铺砖(tile)层面达到平衡
alloc out[2046][3072]
for each ty in 0..2048/32:
for each tx in 0..3072/32:
alloc blurx[-1..33][32]
for y in -1..33:
for x in 0..32:
blurx[y][x] = In[ty*32+y][tx*32+x-1]
+ In[ty*32+y][tx*32+x]
+ In[ty*32+y][tx*32+x+1]
for y in 0..32:
for x in 0..32:
out[ty*32+y][tx*32+x] = blurx[y-1][x]
+ blurx[y ][x]
+ blurx[y+1][x]
调度模型(Scheduling Choice Space)
Domain Order
- 每一个维度sequentially/parallel
- 常量维度unrolled/vectorized
- 维度能够被reordered (column-/row- major)
- 维度可以被split (\(outer\times factor+inner\)) 区间分析(interval analysis)比多面体分析(polyhedral analysis)要简单,大多图像处理的函数也只是应用在垂直式(rectilinear)区域
Call Schedule
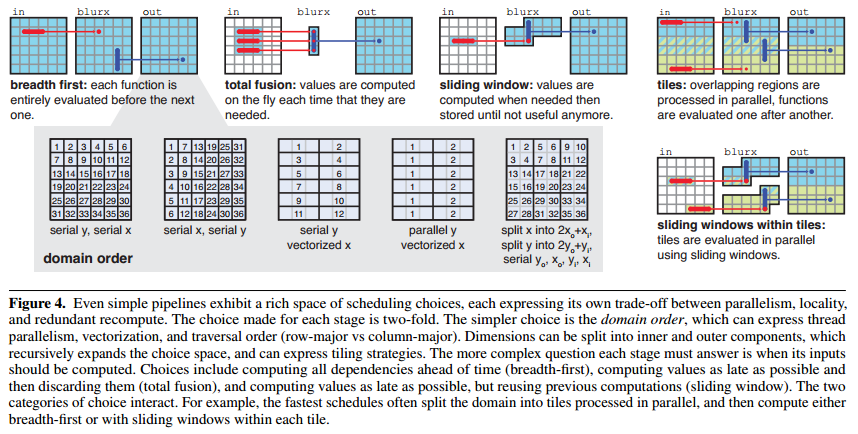
- 宽度优先在最粗粒度存算(root level–在其他循环之外)
- 全融合在最细粒度存算(一被产生立即被计算,每次循环都要重新分配计算)
- 滑动窗口在粗粒度存,在细粒度算 注意:存的粒度一定要比算的粒度粗/相等
例子
注意:Halide以C++作为宿主语言,后端用llvm(+自己SIMD优化)直接编译为汇编
Func blur_3x3(Func input) {
Func blur_x, blur_y;
Var x, y, xi, yi;
// The algorithm - no storage or order
blur_x(x, y) = (input(x-1, y) + input(x, y) + input(x+1, y))/3;
blur_y(x, y) = (blur_x(x, y-1) + blur_x(x, y) + blur_x(x, y+1))/3;
// The schedule - defines order, locality; implies storage
blur_y.tile(x, y, xi, yi, 256, 32)
.vectorize(xi, 8).parallel(y);
blur_x.compute_at(blur_y, x).vectorize(x, 8);
return blur_y;
}
编译器
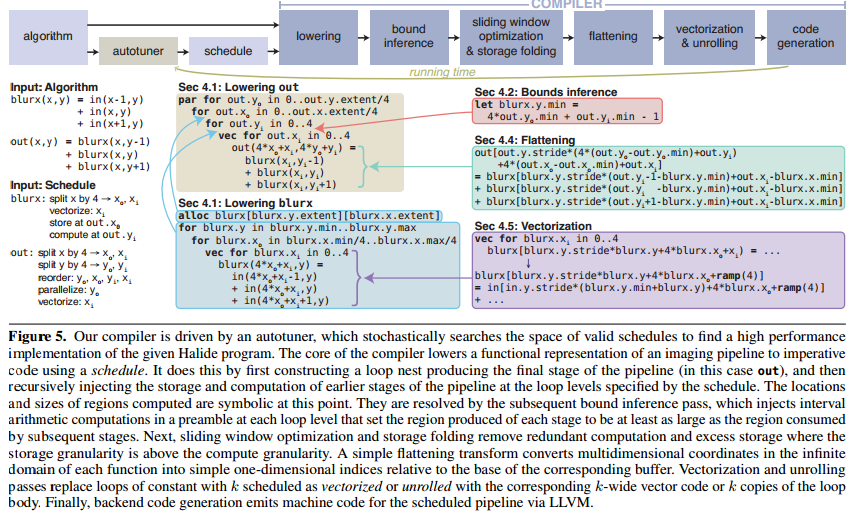
自动调参
搜索空间巨大 $>10^{720}$ 种调度策略,采用基因算法
- 调度搜索空间(schedule search space)
- 合理性检验(sanity check):验证程序正确性
- 搜索起始点
- 基因搜索算法
- 突变规则(schedule mutation rules)
实验
五个图像处理算法
- Blur
- Bilateral grid
- Camera pipeline
- Local Laplacian filters:非常复杂的依赖关系!
- Multi-scale interpolation x86增速1.2x-4.4x,cuda增速2.3x-9x
GraphIt 3
组合性的赞歌!
GraphIt does not introduce any new optimizations. Instead, the DSL achieves competitive or better performance compared to other frameworks by generating efficient implementations of known combinations of optimizations, and finding previously unexplored combinations by searching through a much larger space of optimizations.
同样分离开算法语言与调度语言,使程序员免除考虑底层并行同步的问题
权衡空间(tradeoff space)
- 局部性(locality):空间时间上重用(reuse)的数量
- 工作效率(work efficiency):加权指令数(cycle)的倒数
- 并行化(parallelism):能够并行的工作数目
图的优化
- 方向:push/pull
- 边界数据结构:sparse/dense
- 并行化:vertex-parallel/edge-aware-vertex-parallel/edge-parallel
- 后者针对幂律图,将同一顶点分为多个chunk,每个chunk有近似边的数目
- cache划分(几乎没有框架支持):尽可能将随机访问限制在LLC中,可微调划分数目,每次读入一个处理
- NUMA优化:不同于cache,每次读入多个并行处理
- 顶点数据布局(layout):访问两个不同数组相同下标
- 程序结构优化:如果两个图的遍历方式相同,可将两个图核融合(kernel fusion),并将两者的数据做成一个
struct
算法语言
filter(func f)apply(func f)from(vertexset vset)to(vertexset vset)
调度语言
configApplyDirection(label, config)configApplyParallelization(label, config, [grainsize], [direction]configApplyNumSSGconfigApplyNUMAfuseFields({vec1, vec2, ...}):融合多个数组进structfuseForLoopfuseApplyFunctions
通过scoped labels和name nodes访问
#l1# for i in 1:10
#s1# edges.apply(func1);
end
#l2# for i in 1:10
#s1# edges.apply(func2);
end
schedule:
program->fuseForLoop("l1", "l2", "l3")
->fuseApplyFunctions("l3:l1:s1", "l3:l2:s1", "fusedFunc")
->configApplyDirection("l3:l1:s1", "DensePull");
图迭代空间(graph iteration space)
用多维向量表示不同的优化组合,四维向量
\[\langle S, B, O, I\rangle:=\langle \text{SSG\_ID}, \text{BSG\_ID}, \text{OuterIter}, \text{InnerIter}\rangle\]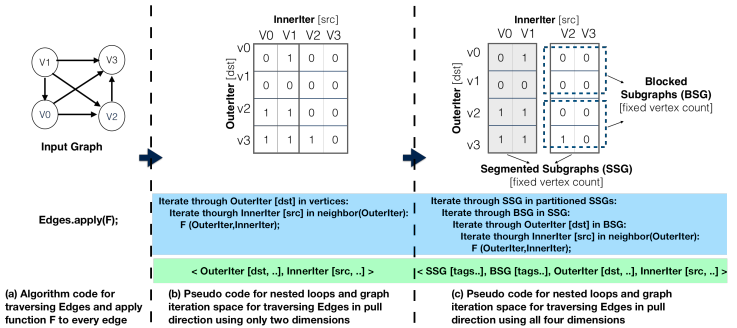
- O, I为顶点编号,控制遍历方向(pull/base)
- B控制并行优化
- S控制cache和NUMA优化
每一个维度都用tag标记,比如configApplyDirection("s1","SparsePush")的图迭代空间为</,/,O[src,SR,SA],I[dst,SR]>,其中SR为serial,SA为sparse array
编译器
编译到C++,目前不支持多后端
- 自动加同步设施
- 可自定义自己的优化pass
- 自动调参(在GraphIt中反而不是重头),用OpenTuner(Halide一作造)
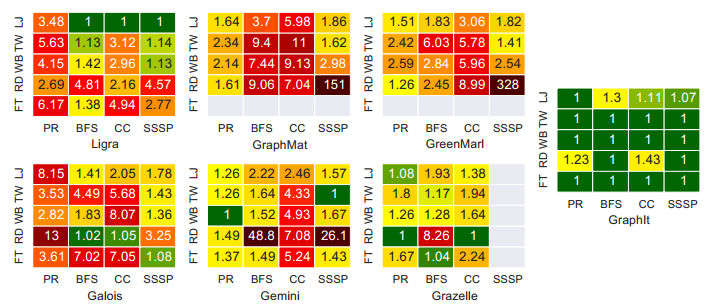
实验
- 四个算法:PageRank、BFS、Connected Components、SSSP
- 五个数据集:LiveJournal、Twitter、WebGraph、USAroad、Friendster
- 七个sota框架:Ligra、GraphMat、GreenMarl、Galois、Gemini、Grazelle
结果是碾压式吊打,1为最快的框架
Spatial4
TVM5
总结
两种设计DSL的方法
- 一种依赖于宿主语言
- Halide依赖于C++编译到汇编/cuda
- Chisel依赖于Scala编译到Verilog
- 一种做更高层的抽象
- GraphIt直接编译为C++
- Spatial直接编译为Chisel
| Halide | GraphIt | Chisel6+Firrtl7 | Spatial | |
|---|---|---|---|---|
| 面向平台 | CPU/GPU | CPU | FPGA | FPGA |
| 分离算法与执行 | √ | √ | × | ×(隐性) |
| IR | √ | × | √ | √ |
| 编译优化 | 大量 | 几乎无 | 部分 | 大量 |
| Autotuning | √ | √ | × | √ |
- Halide做得最好,全平台,大量优化,调度与计算分离
- Chisel抽象很弱,但是相比起传统HDL来说已经非常好了;后来又加上了Firrtl这个IR,规范了语义同时也便于做优化
- GraphIt主要做了抽象,调度与计算分离,编译优化做得很少
- Spatial做了大量优化,但是没有将设计与计算分离,或者是隐性分离了(?)
GraphIt和Chisel更多算Metalanguage/Code Generator,而不是真正的compiler
更加详细关于DSL的内容请见领域特定语言。
参考文献
-
Jonathan Ragan-Kelley (MIT), Connelly Barnes, Andrew Adams, Sylvain Paris, Frédo Durand, and Saman Amarasinghe, Halide: A Language and Compiler for Optimizing Parallelism, Locality, and Recomputation in Image Processing Pipelines, PLDI, 2013 ↩
-
Stencil code, https://en.wikipedia.org/wiki/Stencil_code ↩
-
Yunming Zhang (MIT), Mengjiao Yang, Riyadh Baghdadi, Shoaib Kamil, Julian Shun, and Saman Amarasinghe, GraphIt: A High-Performance Graph DSL, OOPSLA, 2018 ↩
-
David Koeplinger (Stanford), Christos Kozyrakis, Kunle Olukotun, et al., Spatial: A Language and Compiler for Application Accelerators, PLDI, 2018 ↩
-
Tianqi Chen (UW), Thierry Moreau, Ziheng Jiang, Lianmin Zheng, Eddie Yan, Arvind Krishnamurthy, et al., TVM: An Automated End-to-End Optimizing Compiler for Deep Learning, OSDI, 2018 ↩
-
Jonathan Bachrach (UCB), Huy Vo, Brian Richards, Yunsup Lee, Andrew Waterman, Rimas Avižienis, John Wawrzynek, Krste Asanovic, et al., Chisel: Constructing Hardware in a Scala Embedded Language, DAC, 2012 ↩
-
Adam Izraelevitz (UCB), Jack Koenig, Patrick Li, Richard Lin, Angie Wang, Albert Magyar, Donggyu Kim, Colin Schmidt, Chick Markley, Jim Lawson, Jonathan Bachrach, Reusability is FIRRTL Ground: Hardware Construction Languages, Compiler Frameworks, and Transformations, ICCAD, 2017 ↩