Hongzheng Chen Blog
ASPLOS'23 Virtual Attendence Summary
Mar 31st, 2023 0This year ASPLOS was held in Vancouver, Canada. Several of my friends attended the conference in-person and gave excellent talks. As many papers are very interesting, I attended the conference virtually. This blog post primarily provides a summary of papers presented at the conference that are related to machine learning systems, which constituted around 50% of the total number of papers presented.
Keynotes
This year’s ASPLOS’23 featured three keynote presentations, two of which centered around machine learning. Initially, I thought both keynotes were related to LLM, as their titles mentioned “generative models” or “language models,” but the first talk wasn’t directly related to LLM. Below are some brief summaries of each keynote:
[Keynote1] Pushing the Limits of Scaling Laws in the Age of Generative Models
This talk was given by Azalia Mirhoseini, who is a Member of Technical Staff at Anthropic, and an incoming Assistant Professor at Stanford. Probably because Anthropic is currently making waves in the LLM area, I directly connected her talk with NLP, but actually most of her works were related to machine learning for systems.
I’ve been familiar with Azalia’s work since she published her paper on device placement five years ago, which employs reinforcement learning to map operations in the DL computational graph to different devices. This paper is actually considered the pioneer of model parallelism. At the time, I was also exploring the use of reinforcement learning for operator scheduling in HLS, and her work greatly inspired me.
Unfortunately, I missed all the talks in the first day, and only became aware of ASPLOS on the second day. Although I missed her talk at the conference, I found that she gave a talk at UW CS colloquium, where she talks about her works from software-hardware co-design [ASPLOS’22] to chip placement and routing problems (the paper was also published on Nature!). I think most of the content is similar, so the UW talk could be a great reference.
[Keynote2] Direct Mind-Machine Teaming
Abhishek Bhattacharjee, a professor at Yale University, gave this talk on Brain-Computer Interface (BCI). As I’m not an expert in this field, I won’t comment much on it.
[Keynote3] Language Models - The Most Important Compute Challenge of Our Time
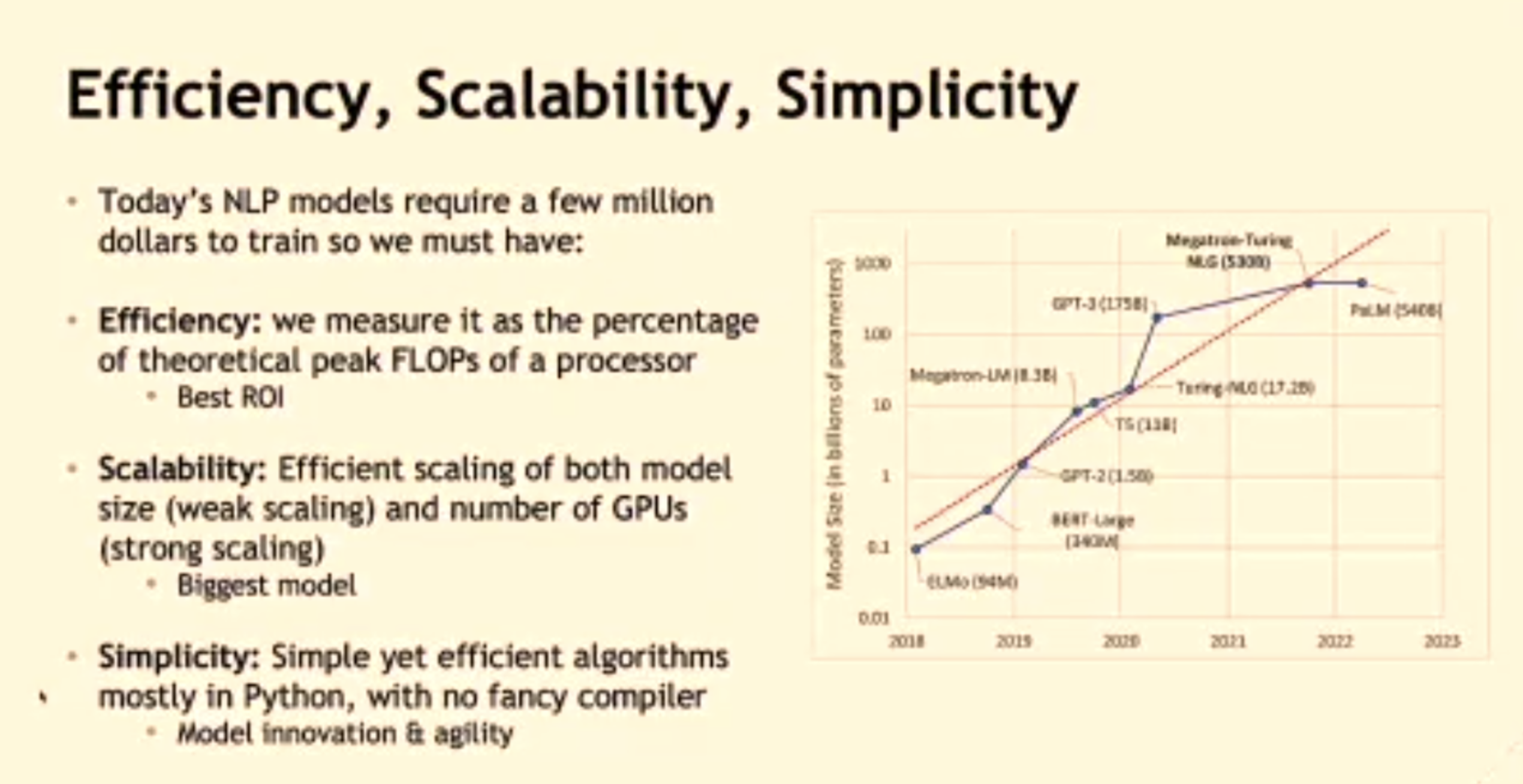
This keynote was given by Bryan Catanzaro. He is the VP of Applied Deep Learning Research at NVIDIA, and previously he received his PhD from UC Berkeley under the supervision of Kurt Keutzer. His most well-known work is probably Megatron-LM, which has already become the mainstream LLM training framework.
In his talk, he also centered around the parallelism techniques in Megatron-LM, including tensor, pipeline, and sequence parallelism. One interesting thing he mentioned was that he did compiler research when he was in grad school. However, when they first considered parallelize the model, they did not leverage compiler but instead manually wrote the parallization scheme. This is because they want to move fast to quickly develop a prototype for high-performance Transformer training. A sophiscated compiler requires lots of engineering efforts and probably cannot quickly catch up with the latest models and hardware.
Another funny thing is that in the Q&A section, someone asked him about how he thought about the proposal of pausing giant AI experiments for 6 months. Bryan immediately reputed “Elon knows nothing about AI” :). The full answer probably can be seen from the official ASPLOS YouTube channel, but in his opinion, the proposal is nonsense, and we should continue researching for a safer LLM.



[Session 1A] Systems for ML
Overlap Communication with Dependent Computation via Decomposition in Large Deep Learning Models
Shibo Wang, Amit Sabne, Andy Davis, Berkin Ilbeyi, Blake Hechtman (Google); Dehao Chen (Waymo); Jinliang Wei, Karthik Srinivasa Murthy, Marcello Maggioni, Qiao Zhang, Sameer Kumar, Tongfei Guo, Yuanzhong Xu, Zongwei Zhou (Google)
https://dl.acm.org/doi/10.1145/3567955.3567959
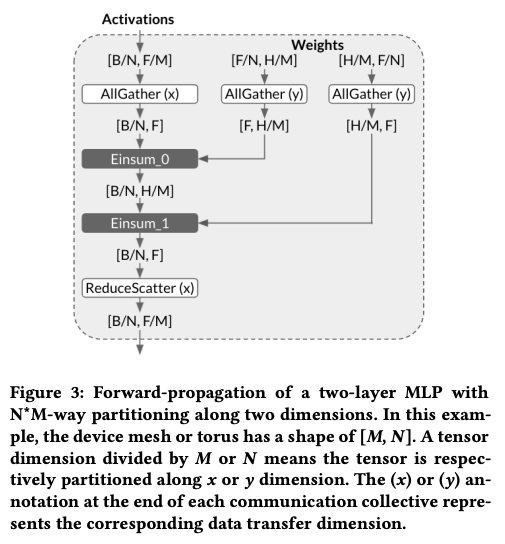
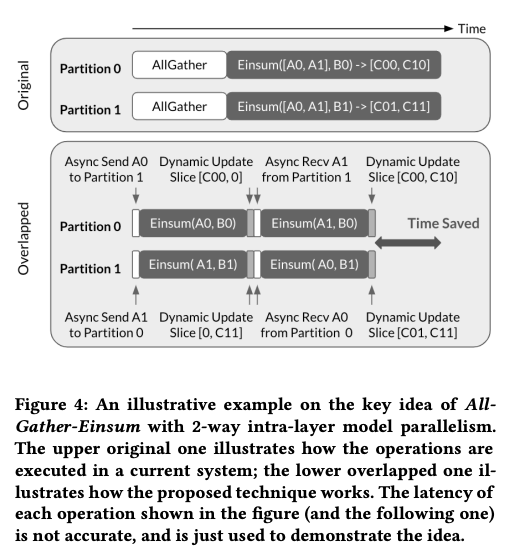
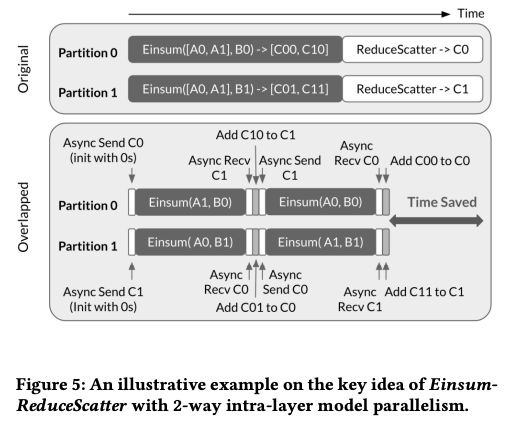
The main idea behind this paper is straightforward: instead of waiting for all data to be received before performing computations, we can overlap computation and communication in an asynchronous manner. This is achieved by decomposing the computation and sending partial matrices to other devices while leveraging the existing matrix for partial computation. The partial results are then combined in the current device to ensure accuracy.
By replacing heavy blocking communication with lightweight non-blocking communication, the communication overheads are greatly reduced. This technique is implemented in XLA, and the authors test a 1T GPT model with 2048 TPU. The communication pattern, which utilizes AllGather+ReduceScatter, is similar to those employed in DeepSpeed or FSDP, but I am not sure why the authors didn’t cite these works.
Heron: Automatically Constrained High-performance Library Generation for Deep Learning Accelerators
Jun Bi (Univ. of Science and Technology of China); Qi Guo, Xiaqing Li, Yongwei Zhao (Inst. of Computing Tech., Chinese Academy of Sciences); Yuanbo Wen, Yuxuan Guo, Enshuai Zhou (Univ. of Science and Technology of China); Xing Hu, Zidong Du (Inst. of Computing Tech., Chinese Academy of Sciences); Ling Li (Inst. of Software, Chinese Academy of Sciences); Huaping Chen (Univ. of Science and Technology of China); Tianshi Chen (Cambricon Technologies)
https://dl.acm.org/doi/10.1145/3582016.3582061
It feels like it’s been a while since we last saw a paper from Cambricon. This work focuses on auto-schedulers for deep learning accelerators, such as NVIDIA TensorCore, Intel DLBoost, and TVM VTA. The authors construct a constrained search space that enables irregular searching, but their key algorithm still relies on genetic algorithms. It seems this work is somehow incremental, and actually this field is very crowded – those baseline systems were published in recent top-tier system conferences claiming significant speedup (e.g., Ansor[OSDI’20], AKG[PLDI’21], and AMOS[ISCA’22]).
TelaMalloc: Efficient On-Chip Memory Allocation for Production Machine Learning Accelerators
Martin Maas, Ulysse Beaugnon, Arun Chauhan, Berkin Ilbeyi (Google)
https://dl.acm.org/doi/10.1145/3567955.3567961
The problem they tackle is placing buffers within the device memory without exceeding the memory capacity, which is NP-hard due to the need to consider both the temporal dimension (operation dependency) and spatial dimension (memory sharing). It is similar to the register allocation problem for CPUs, but the search space is much larger.
EVStore: Storage and Caching Capabilities for Scaling Embedding Tables in Deep Recommendation Systems
Skip. Not my area.
WACO: Learning Workload-Aware Co-optimization of the Format and Schedule of a Sparse Tensor Program
Jaeyeon Won (Massachusetts Inst. of Technology); Charith Mendis (Univ. of Illinois Urbana-Champaign); Joel Emer (Massachusetts Inst. of Technology / NVIDIA); Saman Amarasinghe (Massachusetts Inst. of Technology)
https://dl.acm.org/doi/10.1145/3575693.3575742
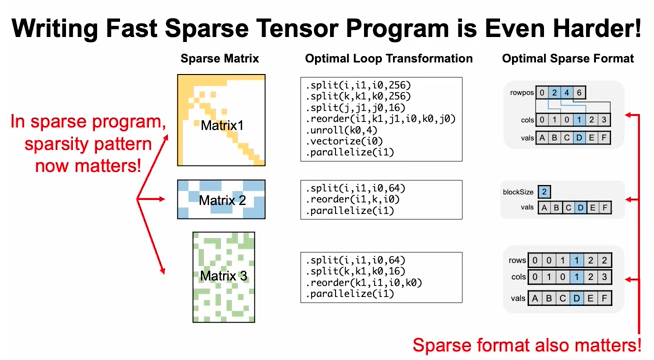
This paper is from Prof. Saman Amarasinghe’s group at MIT. The authors’ motivation is sound: for sparse workloads, the pattern or format of the sparsity significantly affects performance, and simply ignoring the pattern is not a viable solution. To address this, the authors propose leveraging data information and combining it with common loop transformation techniques to improve the efficiency of sparse programs. Specifically, they introduce a CNN model to encode the critical features within sparsity.
GRACE: A Scalable Graph-Based Approach To Accelerating Recommendation Model Inference
Skip.
[Session 2A] Compiler Techniques & Optimization
SPLENDID: Supporting Parallel LLVM-IR Enhanced Natural Decompilation for Interactive Development
Zujun Tan, Yebin Chon (Princeton Univ.); Michael Kruse, Johannes Doerfert (Argonne National Laboratory); Ziyang Xu (Princeton Univ.); Brian Homerding, Simone Campanoni (Northwestern Univ.); David I. August (Princeton Univ.)
https://doi.org/10.1145/3582016.3582058
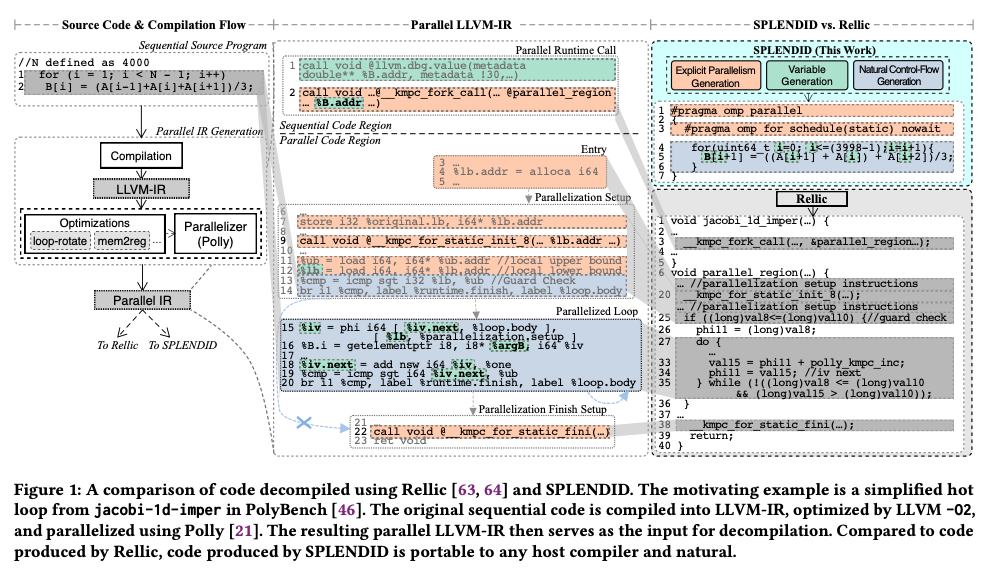
This paper presents an intriguing concept: a decompiler for OpenMP/C. It is my first time knowing about the concept of decompiler, which can be thought of as the reverse engineering process of a compiler. Since compiler optimization is often a black box, programmers struggle to understand how the compiler transforms their program. This paper takes an optimized parallel program/IR and recovers its OpenMP pragma, generating a more concise and simplified program. This tool can be a boon for programmers seeking to improve their program’s performance. It offers more guidance and leverages the benefits of both manual and compiler optimizations.
I will revisit this paper later. It is worth considering if a deep learning decompiler could be developed. Such a tool would significantly aid programmers in understanding the optimizations made in their program.
Beyond Static Parallel Loops: Supporting Dynamic Task Parallelism on Manycore Architectures with Software-Managed Scratchpad Memories
Lin Cheng (Cornell Univ.); Max Ruttenberg, Dai Cheol Jung (Univ. of Washington); Dustin Richmond (Univ. of California, Santa Cruz); Michael Taylor, Mark Oskin (Univ. of Washington); Christopher Batten (Cornell Univ.)
https://doi.org/10.1145/3582016.3582020
Paper from Batten’s group. Since hardware cache-coherence brings lots of overheads, this work tries to remove the L1 cache and leverage work stealing mechanism to improve parallel performance.
Graphene: An IR for Optimized Tensor Computations on GPUs
Bastian Hagedorn, Bin Fan, Hanfeng Chen, Cris Cecka, Michael Garland, Vinod Grover (NVIDIA)
https://doi.org/10.1145/3582016.3582018
The lightning talk is very interesting (but at the same time is not that informative). This paper claims that CUDA is not a good intermediate representation for deep learning compiler, so they introduce a new IR closer to the domain of tensor computation. However, it is hard to know the differences or the benefits of this work compared to OpenAI Triton. The paper gives the following comparsion.
Triton exposes a high-level Python DSL which is transformed into a custom IR that is eventually lowered into high-performance LLVM code using tensor core instructions. However, Triton’s highlevel DSL and IR intentionally abstract the complexity of GPU tensor instructions and only introduce them during LLVM code generation. This leads to highly complex compiler transformation passes whose extension requires both initimate knowledge of the targeted GPU architectures as well as the compiler implementation itself. In contrast, Graphene aims to explicity express optimized computations on the IR level and uses a straight-forward code generation.
Coyote: A Compiler for Vectorizing Encrypted Arithmetic Circuits
Raghav Malik, Kabir Sheth, Milind Kulkarni (Purdue Univ.)
https://doi.org/10.1145/3582016.3582057
Skip.
NNSmith: Generating Diverse and Valid Test Cases for Deep Learning Compilers
Jiawei Liu (Univ. of Illinois Urbana-Champaign); Jinkun Lin, Fabian Ruffy (New York Univ.); Cheng Tan (Northeastern Univ.); Jinyang Li, Aurojit Panda (New York Univ.); Lingming Zhang (Univ. of Illinois Urbana-Champaign)
https://dl.acm.org/doi/10.1145/3575693.3575707
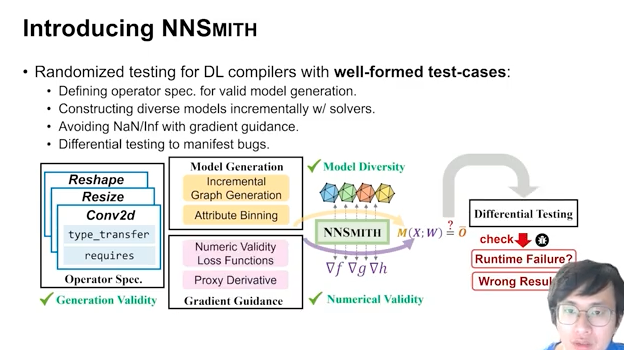
My friend Jiawei’s great work. He leads the pioneer research of fuzzing + DL compiler, and found many subtle bugs in TVM, PyTorch, etc. Please check his homepage for those amazing works!
In particular, this work aims to automatically generate valid and diverse test cases for DL compilers. Test cases need to pass the compiler’s parser, lexer, and optimization passes, as well as ensure numerical correctness, avoiding NaN or overflow during computation.
TiLT: A Time-Centric Approach for Stream Query Optimization and Parallelization
Anand Jayarajan (Univ. of Toronto / Vector Inst.); Wei Zhao, Yudi Sun (Univ. of Toronto); Gennady Pekhimenko (Univ. of Toronto / Vector Inst.)
https://dl.acm.org/doi/10.1145/3575693.3575704
Skip.
[Session 4C] Tensor Computation
Flexagon: A Multi-Dataflow Sparse-Sparse Matrix Multiplication Accelerator for Efficient DNN Processing
Francisco Munoz-Martinez (Universidad de Murcia); Raveesh Garg (Georgia Inst. of Technology); Michael Pellauer (NVIDIA); José L. Abellan, Manuel E. Acacio (Universidad de Murcia); Tushar Krishna (Georgia Inst. of Technology)
https://doi.org/10.1145/3582016.3582069
SpMSpM has the following three dataflow patterns. This work proposes an accelerator to combine all of those dataflows. Experiments are done on several sparse models including DistillBERT and MobileBERT.
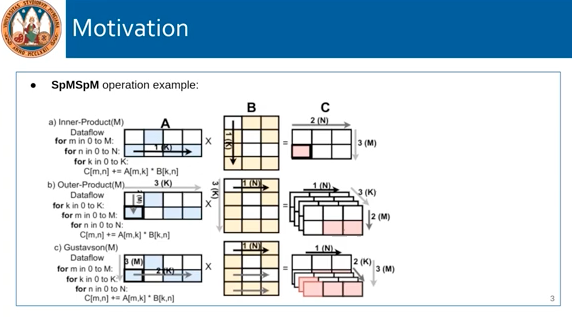
Accelerating Sparse Data Orchestration via Dynamic Reflexive Tiling
Toluwanimi O. Odemuyiwa (Univ. of California, Davis); Hadi Asghari-Moghaddam (Univ. of Illinois Urbana-Champaign / Meta); Michael Pellauer (NVIDIA); Kartik Hegde (Univ. of Illinois Urbana-Champaign); Po-An Tsai, Neal Crago, Aamer Jaleel (NVIDIA); John D. Owens (Univ. of California, Davis); Edgar Solomonik (Univ. of Illinois Urbana-Champaign); Joel Emer (Massachusetts Inst. of Technology / NVIDIA); Christopher Fletcher (Univ. of Illinois Urbana-Champaign)
https://doi.org/10.1145/3582016.3582064
- Tile shape must be non-uniform (otherwise may incur load imbalance)
- Tiling should be done in the coordinate space
- Tiling must be dynamic
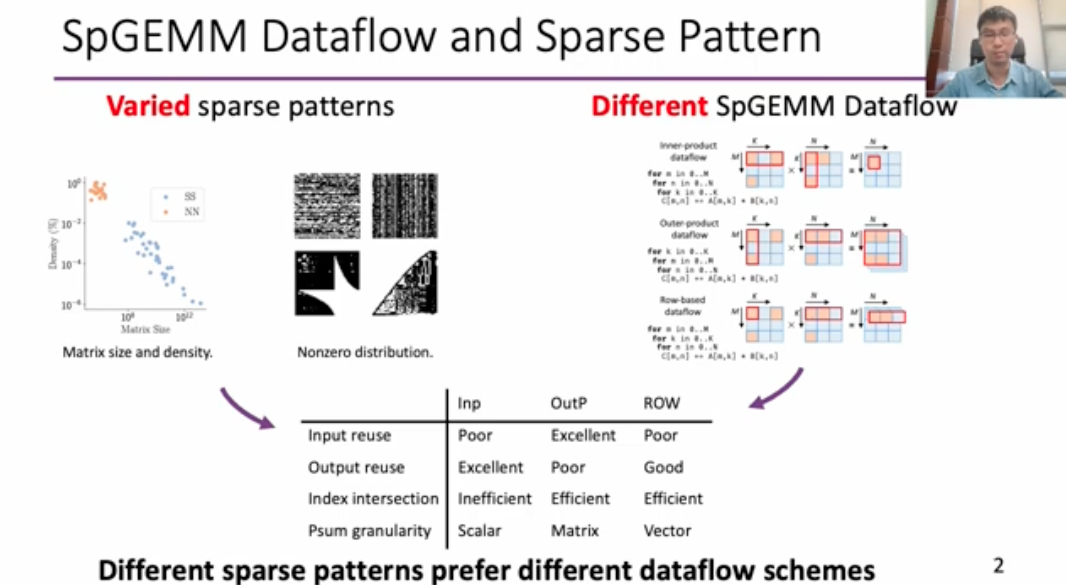
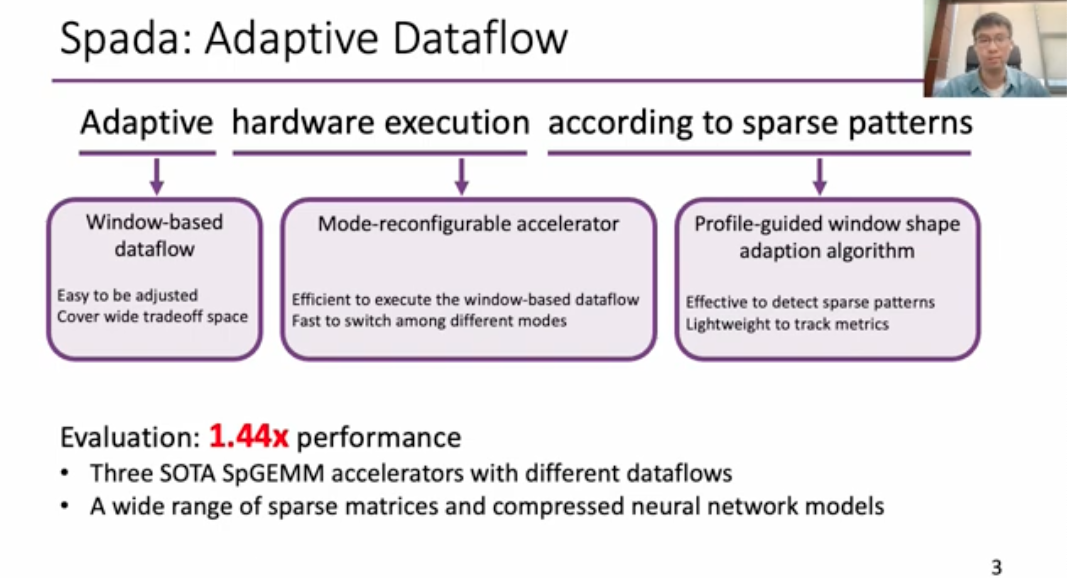
SPADA: Accelerating Sparse Matrix Multiplication with Adaptive Dataflow
Zhiyao Li (Tsinghua Univ.); Jiaxiang Li (Northwestern Univ.); Taijie Chen (Tsinghua Univ.); Dimin Niu, Hongzhong Zheng, Yuan Xie (Alibaba DAMO Academy); Mingyu Gao (Tsinghua Univ. / Shanghai Qi Zhi Inst.)
https://dl.acm.org/doi/10.1145/3575693.3575706
This work is quite similar to the Flexagon one, which dynamically chooses the dataflow based on the matrix patterns.
SparseTIR: Composable Abstractions for Sparse Compilation in Deep Learning
Zihao Ye (Univ. of Washington); Ruihang Lai (Carnegie Mellon Univ.); Junru Shao (OctoML); Tianqi Chen (Carnegie Mellon Univ.); Luis Ceze (Univ. of Washington)
https://doi.org/10.1145/3582016.3582047
My another friend Zihao’s work. Represent sparse format and transformations in TVM, which enables better layout composition and high-performance kerenel generation.


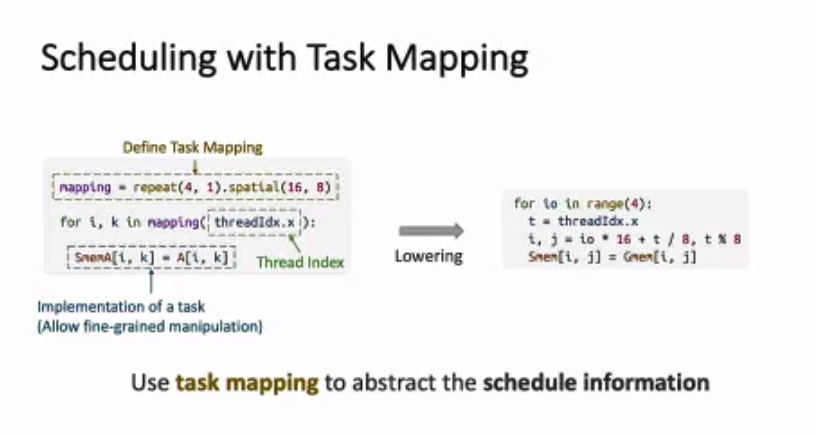
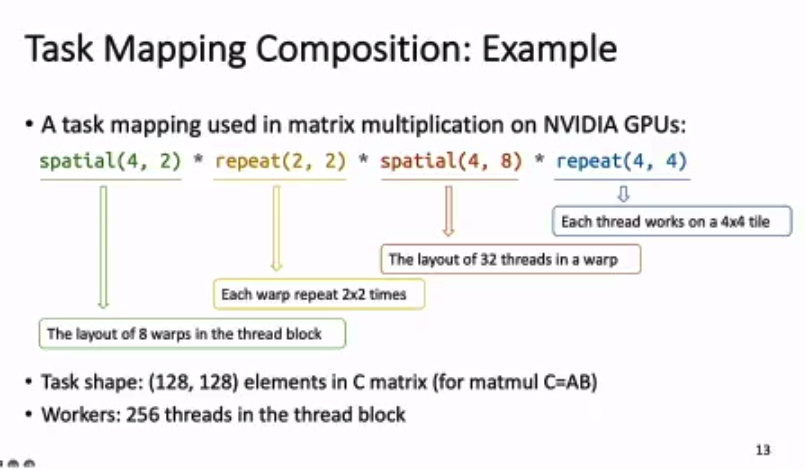
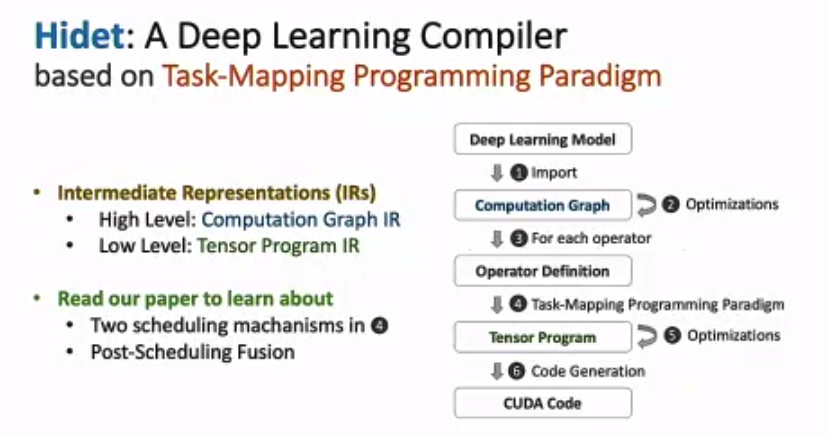
Hidet: Task Mapping Programming Paradigm for Deep Learning Tensor Programs
Yaoyao Ding (Univ. of Toronto / Vector Inst.); Cody Hao Yu (Amazon Web Services); Bojian Zheng (Univ. of Toronto / Vector Inst.); Yizhi Liu, Yida Wang (Amazon Web Services); Gennady Pekhimenko (Univ. of Toronto / Vector Inst.)
https://dl.acm.org/doi/10.1145/3575693.3575702
Work from my AWS team. It is funny to put this work in a fully “sparse” session. Nevertheless, this work is a great work to argue that the TVM programming interface is not the best one and may lose lots of optimization opportunities (e.g., double buffer). By redesigning the programming model using a task-parallel method, we can express those optimizations easier and generate high-performance programs much faster. (Actually the Hidet program is also much closer to CUDA.)


Sparse Abstract Machine
Olivia Hsu, Maxwell Strange, Ritvik Sharma (Stanford Univ.); Jaeyeon Won (Massachusetts Inst. of Technology); Kunle Olukotun (Stanford Univ.); Joel Emer (Massachusetts Inst. of Technology / NVIDIA); Mark A Horowitz, Fredrik Kjolstad (Stanford Univ.)
https://doi.org/10.1145/3582016.3582051
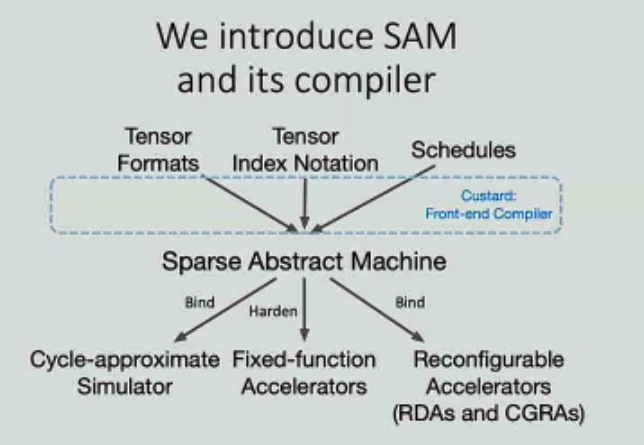

This work is not yet integrated with MLIR, and the author claimed they were looking into the FPGA backend.
[Session 5C] Machine Learning
Homunculus: Auto-Generating Efficient Data-Plane ML Pipelines for Datacenter Networks
Tushar Swamy (Stanford Univ.); Annus Zulfiqar (Purdue Univ.); Luigi Nardi (Lund Univ. / Stanford Univ.); Muhammad Shahbaz (Purdue Univ.); Kunle Olukotun (Stanford Univ.)
https://www.youtube.com/watch?v=4xmwHIDbxjM
Sounds like an interesting work, but haven’t got time to dig into it.
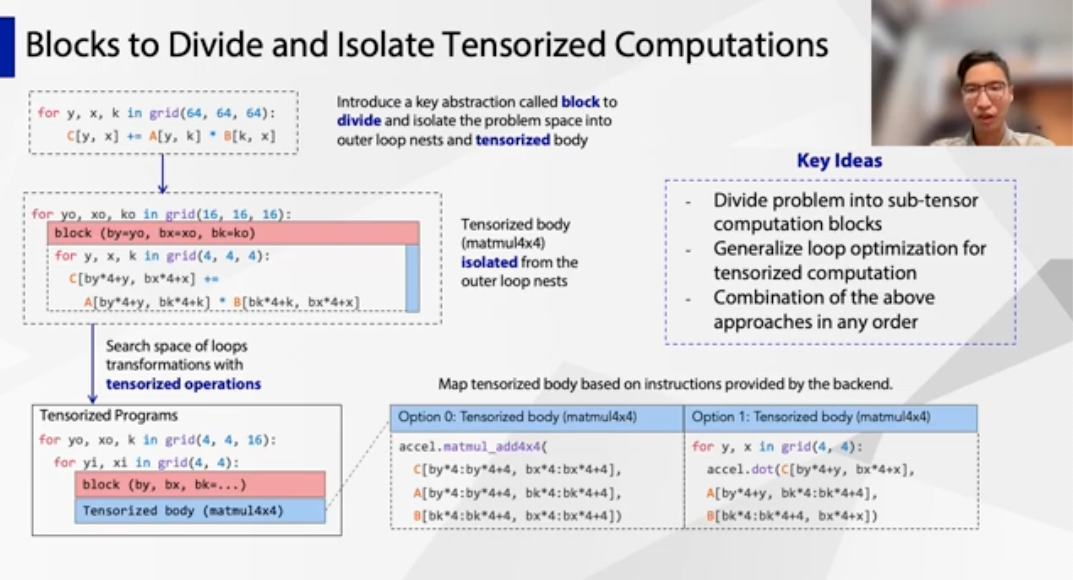
TensorIR: An Abstraction for Automatic Tensorized Program Optimization
Siyuan Feng (Shanghai Jiao Tong Univ.); Bohan Hou, Hongyi Jin (Carnegie Mellon Univ.); Wuwei Lin, Junru Shao (OctoML); Ruihang Lai (Carnegie Mellon Univ.); Zihao Ye (Univ. of Washington); Lianmin Zheng (Univ. of California, Berkeley); Cody Hao Yu (Amazon Web Services); Yong Yu (Shanghai Jiao Tong Univ.); Tianqi Chen (Carnegie Mellon Univ. / OctoML)
https://dl.acm.org/doi/10.1145/3575693.3576933
Another work from TVM. Compared to the previous TIR, TensorIR makes big improvement for imperative programs description inside a block (mostly deprecate the declarative tensor expression programs), which supports better tensorization. It is essentially important for mapping those workloads onto TensorCore.
FLAT: An Optimized Dataflow for Mitigating Attention Bottlenecks
Sheng-Chun Kao (Georgia Inst. of Technology); Suvinay Subramanian (Google); Gaurav Agrawal (Microsoft); Amir Yazdanbakhsh (Google Research, Brain Team); Tushar Krishna (Georgia Inst. of Technology)
https://dl.acm.org/doi/10.1145/3575693.3575747
Summarized by the presenter, there are two main differences between this work and FlashAttention (FA):
- FLAT uses output-stationary while FA is weight-stationary
- FLAT uses a row-wise tiling method while FA uses block-wise tiling
Otherwise, it also leverage operator fusion to reduce memory footprint.
TLP: A Deep Learning-based Cost Model for Tensor Program Tuning
Yi Zhai, Yu Zhang, Shuo Liu, Xiaomeng Chu, Jie Peng, Jianmin Ji, Yanyong Zhang (Univ. of Science and Technology of China)
https://dl.acm.org/doi/10.1145/3575693.3575737
Another autoscheduler work. This work extracts features from schedule primitives rather than tensor programs, and treats schedule primitives as tensor language and turns the task of predicting tensor program latency into an NLP regression task.
Also compared to Ansor, but it seems most of the improvements in this field is incremental.
Mobius: Fine Tuning Large-scale Models on Commodity GPU Servers
Yangyang Feng, Minhui Xie, Zijie Tian, Shuo Wang, Youyou Lu, Jiwu Shu (Tsinghua Univ.)
https://dl.acm.org/doi/10.1145/3575693.3575703
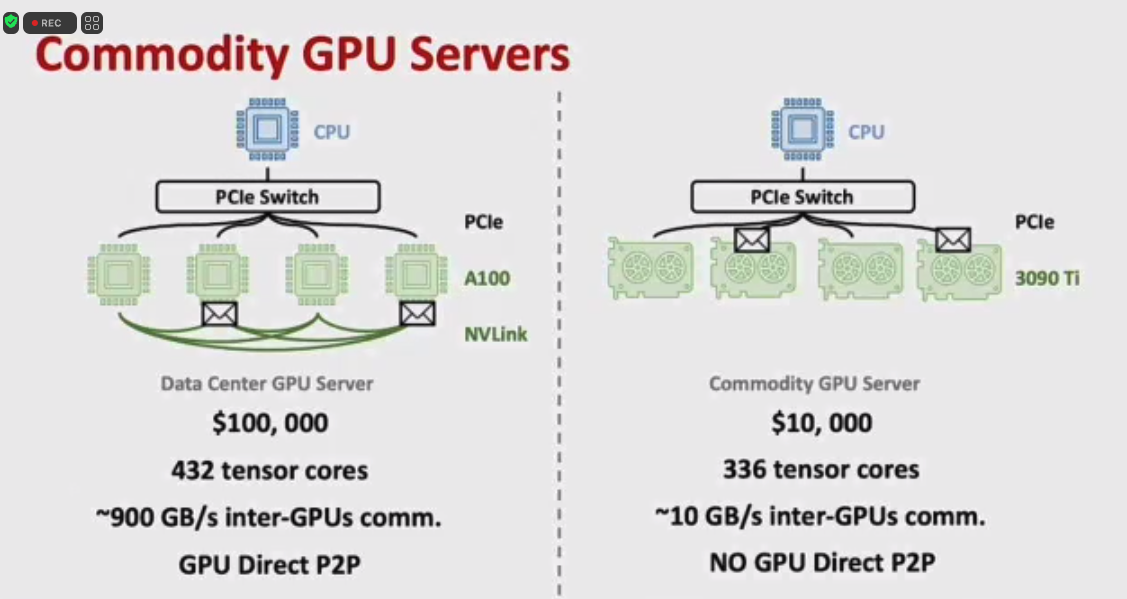
This work proposes a new pipeline parallelism method that is more suitable for commodity GPU training. However, I am uncertain about the relevance of fine-tuning large-scale models as a topic, since GPT-series models all claim to require no fine-tuning, instead leveraging few-shot learning from examples. Furthermore, no one would want to fine-tune a 540B model, even on commodity GPU servers (without NVLink connection), as it requires a significant amount of money and time. Additionally, the experiments are questionable. They could have used DeepSpeed-Megatron for training large models or leveraged ZeRO-2 + pipeline parallelism as a baseline, but they simply report out-of-memory results. The lack of model size in the convergence analysis is also concerning.
Betty: Enabling Large-Scale GNN Training with Batch-Level Graph Partitioning
Shuangyan Yang (Univ. of California, Merced); Minjia Zhang (Microsoft Research); Wenqian Dong, Dong Li (Univ. of California, Merced)
https://dl.acm.org/doi/10.1145/3575693.3575725
Target a common challenge in GNN training – how to partition a large graph onto mutiple devices while maintaining good data locality. They introduce two techniques, redundancy-embedded graph and memory-aware partitioning, to reduce the redundancy while effectively mitigating the load imbalance issue from the batch-level partitioning.
[Session 6C] Graphs A
Glign: Taming Misaligned Graph Traversals in Concurrent Graph Processing
Xizhe Yin, Zhijia Zhao, Rajiv Gupta (Univ. of California, Riverside)
For the first time, my first-author paper was cited in the top-tier conference! This work can be viewed as an improvement for my SC’21 concurrent graph processing system Krill. It also explores the intrinsic characteristics of the graph queries, so that we can have a better understanding of the tasks and achieve higher speedup.
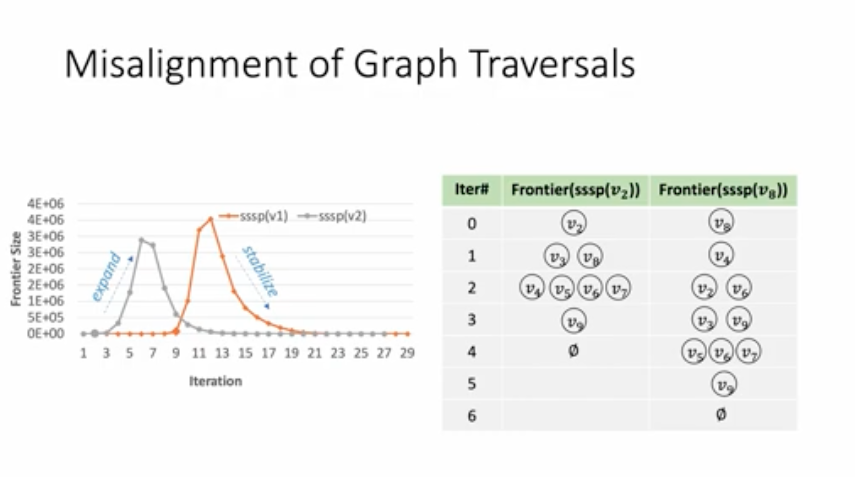
The authors of this paper highlight the low performance results caused by inter-iteration and intra-iteration misalignment of graph tasks and propose two techniques to mitigate these issues:
- Intra-iteration alignment: Maintain a single frontier for all the graph queries.
- Inter-iteration alignment: Use offline profiling – hops to a closest high-degree vertex (use BFS).
The intra-iteration alignment part is quite similar to Krill’s common frontier. I think the biggest improvement compared to Krill is that it pays more attention to the inter-iteration alignment, which delays the queries to make them have a similar frontier expansion time interval. This idea is very intuitive and I believe it can have good performance. I also observe the phenomenon of frontier misalignment when I conducting experiments with Krill, so I pointed out in the paper that Krill is more suitable for homogenous graph queries, especially for those have neighboring starting vertices. Delaying the graph tasks is great for aligning the frontiers and leading to high throughput. However, this paper does not evaluate the average response latency of the graph tasks (Krill did evaluate this), which is an important metrics for end-uesr experience. Additionally, the paper also does not conduct scalability experiments regarding number of CPU cores and graph tasks. Probably this is not that important for ASPLOS.
NosWalker: A Decoupled Architecture for Out-of-Core Random Walk Processing
Shuke Wang, MingXing Zhang (Tsinghua Univ.); Ke Yang (Tsinghua Univ. / Beijing HaiZhi XingTu Technology Co., Ltd.); Kang Chen, Shaonan Ma, Jinlei Jiang, Yongwei Wu (Tsinghua Univ.)
Improvement to KnightKing.
DecoMine: A Compilation-based Graph Pattern Mining System with Pattern Decomposition
Jingji Chen, Xuehai Qian (Purdue Univ.)
Xuehai group’s work. Two first-author ASPLOS papers by Jingji was accepted this year!
[Session 7A] Deep Learning Systems
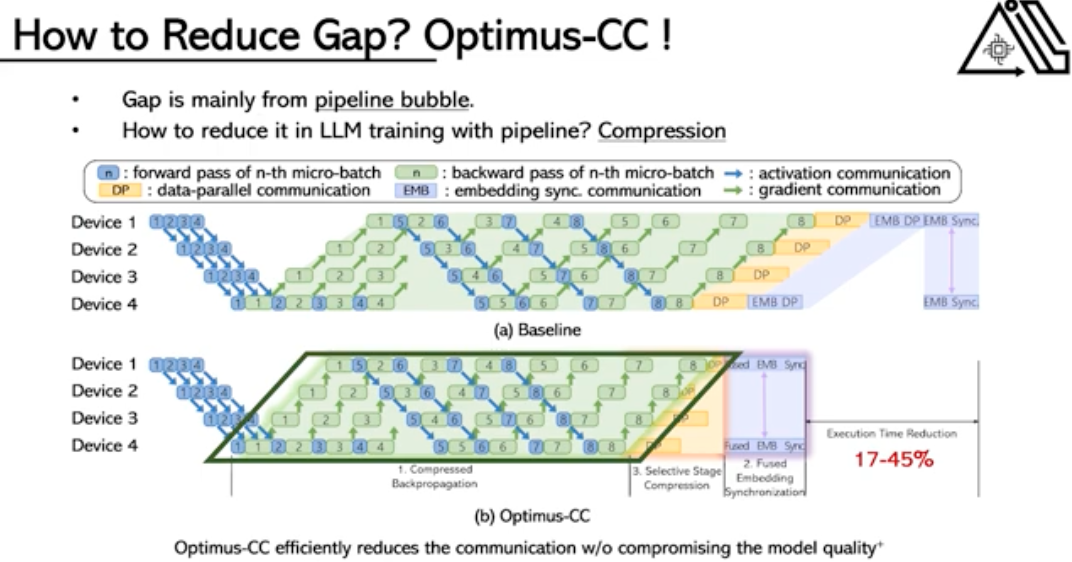
Optimus-CC: Efficient Large NLP Model Training with 3D Parallelism Aware Communication Compression
Jaeyong Song (Yonsei Univ.); Jinkyu Yim (Seoul National Univ.); Jaewon Jung (Yonsei Univ.); Hongsun Jang (Seoul National Univ.); Hyung-Jin Kim (Samsung Electronics); Youngsok Kim (Yonsei Univ.); Jinho Lee (Seoul National Univ.)
https://dl.acm.org/doi/10.1145/3575693.3575712
This work mainly targets to reduce the communication overheads in pipeline parallelism. The following figure shows their proposed three techniques.
DPACS: Hardware Accelerated Dynamic Neural Network Pruning through Algorithm-Architecture Co-design
Yizhao Gao, Baoheng Zhang, Xiaojuan Qi, Hayden Kwok-Hay So (Univ. of Hong Kong)
https://dl.acm.org/doi/10.1145/3575693.3575728
Similar to the channel gating work proposed by our group.
CGNet [21, 22] proposed a dynamic channel gating technique for DNN inference. It gates the computation on the conditional path if the partial sum of the base path is effective enough. CGNet also proposes a hardware accelerator architecture that can efficiently carry out dynamic inference. Compared with DPACS, CGNet performs per-activation dynamic gating while we explicitly use spatial + channel pruning separately. CGNet requires all the weights to load on-chip as the conditional path can be activated during run time. While in DPACS, owing to the precomputation of the channel masks, we can additionally save the unnecessary weights IO during run time.
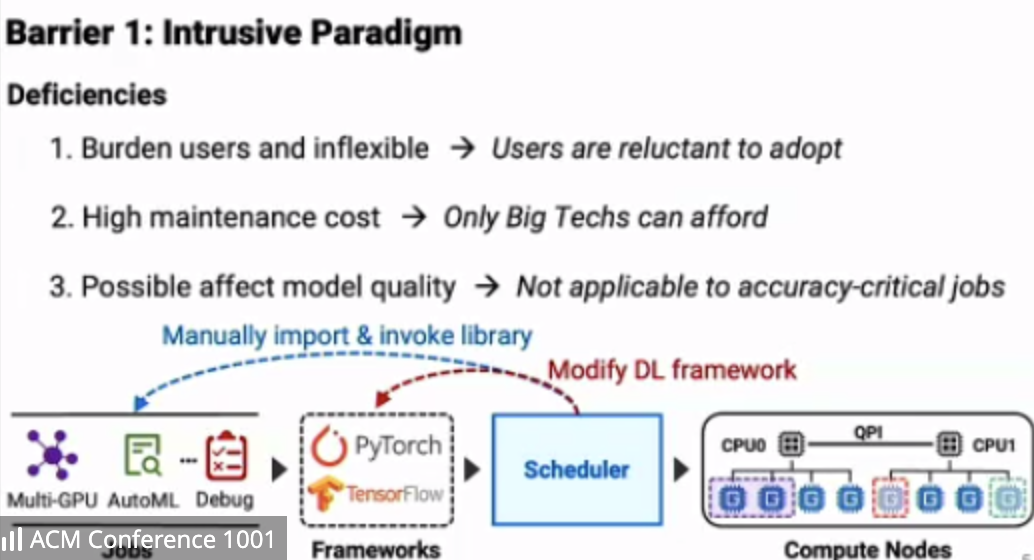
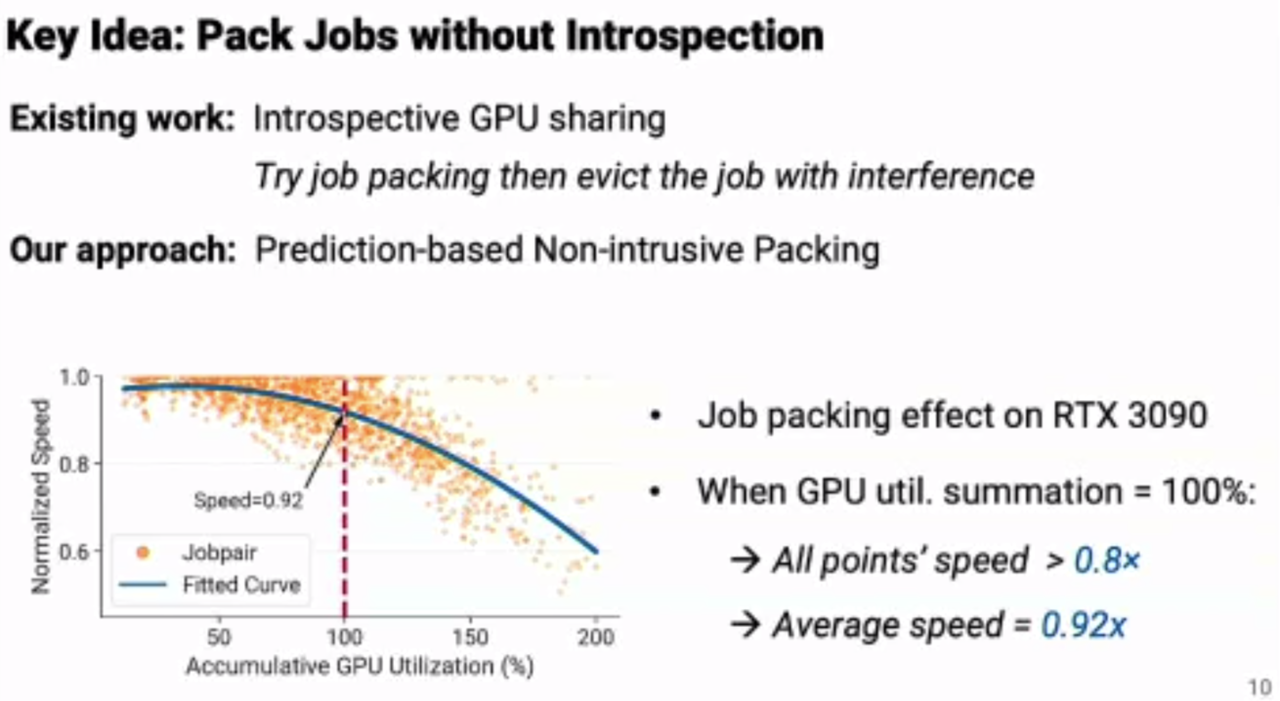
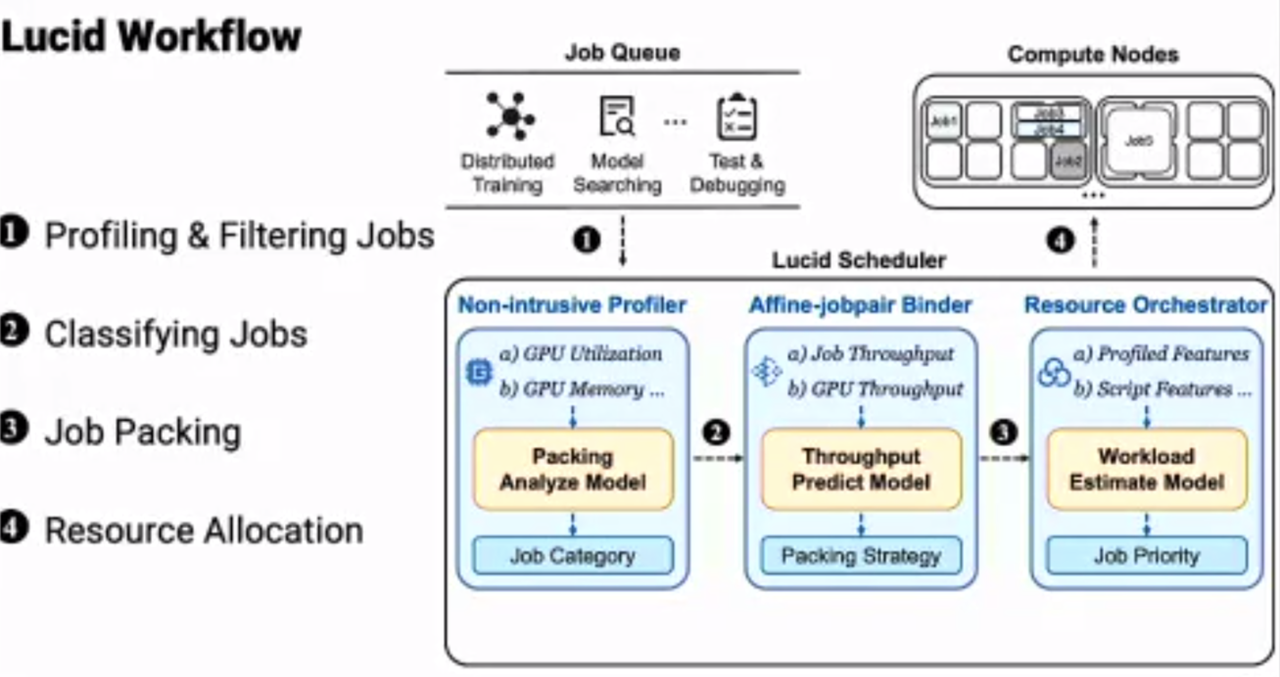
Lucid: A Non-Intrusive, Scalable and Interpretable Scheduler for Deep Learning Training Jobs (Distinguished Paper)
Qinghao Hu, Meng Zhang (Nanyang Technological Univ.); Peng Sun (SenseTime); Yonggang Wen, Tianwei Zhang (Nanyang Technological Univ.)
https://dl.acm.org/doi/10.1145/3575693.3575705
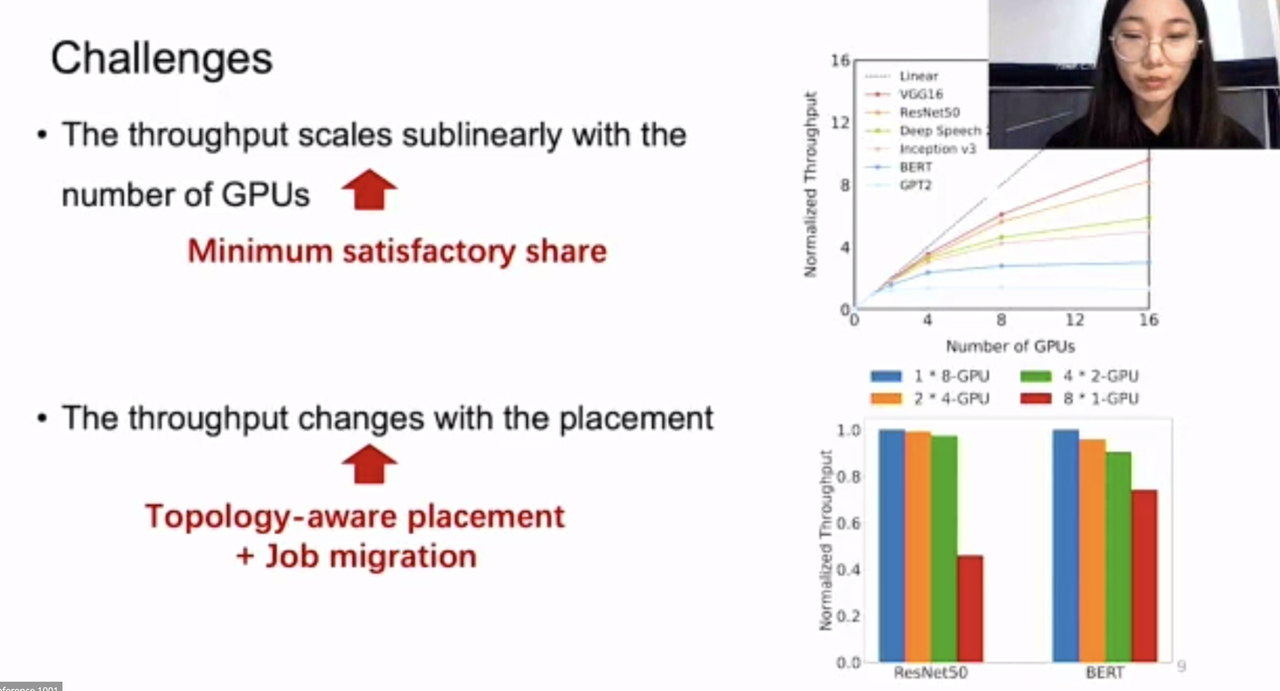
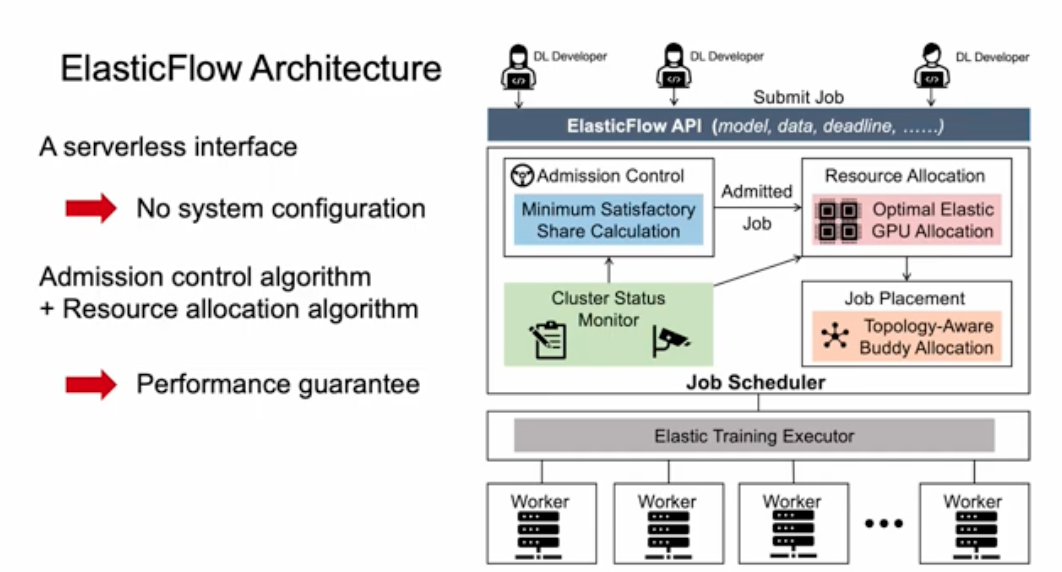
ElasticFlow: An Elastic Serverless Training Platform for Distributed Deep Learning
Diandian Gu, Yihao Zhao, Yinmin Zhong (Peking Univ.); Yifan Xiong, Zhenhua Han, Peng Cheng, Fan Yang (Microsoft Research); Gang Huang, Xin Jin, Xuanzhe Liu (Peking Univ.)
https://dl.acm.org/doi/10.1145/3575693.3575721
Hyperscale Hardware Optimized Neural Architecture Search
Sheng Li, Garrett Andersen, Tao Chen, Liqun Cheng, Julian Grady, Da Huang, Quoc Le, Andrew Li, Xin Li, Yang Li, Chen Liang, Yifeng Lu, Yun Ni (Google); Ruoming Pang (Apple); Mingxing Tan (Waymo); Martin Wicke, Gang Wu, Shengqi Zhu, Parthasarathy Ranganathan, Norman P. Jouppi (Google)
NAS. Skip.
Probably a more interesting work is the full-stack DSE work from Google published in ASPLOS’22.
A Full-Stack Search Technique for Domain Optimized Deep Learning Accelerators
Dan Zhang, Safeen Huda, Ebrahim Songhori, Kartik Prabhu, Quoc Le, Anna Goldie, Azalia Mirhoseini
https://dl.acm.org/doi/pdf/10.1145/3503222.3507767
DeepUM: Tensor Migration and Prefetching in Unified Memory
Jaehoon Jung (Moreh Inc.); Jinpyo Kim, Jaejin Lee (Seoul National Univ.)
Skip.
[Session 8B] Accelerator B
Stepwise Debugging for Hardware Accelerators
Griffin Berlstein, Rachit Nigam (Cornell Univ.); Chris Gyurgyik (Google); Adrian Sampson (Cornell Univ.)
Adrian group’s work. Very impressive demo. They propose a gdb-like debugger for hardware programs written in accelerator design language (ADL), making it much easier to debug waveform step by step. This is a significant advancement that will greatly aid in the debugging process of hardware programs.