Hongzheng Chen Blog
PhD第二年 - 自由而热烈
Sep 11th, 2023 0在Austin开会做完presentation,线下跟人聊还是没能完全改口说自己是second-year PhD的说法。进入第三年就有种旅程已经过半,很快要毕业的感觉。PhD第二年过得很快却又经历了太多事,在西海岸呆了半年,又回来东海岸过了很intense的一个学期以及疯狂的暑假。大概是走火入魔了,PhD读到现在反倒很快乐。 一方面是科研稍有起色,能够持续做自己喜欢的research本身就是件快乐的事;另外一方面则是有很多很棒能够一起喝酒打牌玩耍的朋友,在村里在纽约在波士顿都能吃上热腾腾的饭菜,去到哪都感觉跟回家一样,所以一直都很幸福。
第二年在工业界lead一个新project投出了PhD期间的第一个work,全部CS/ECE advanced level courses都拿了A+,线下开了5次会,给了十几次talk,也攒了些citation; 但与之相对是0中稿的同时收了6封拒信,学术意义上这并不是漂亮的成绩,但这一年大概是发现在成功失败二象限之外,还存在着更多的隐藏维度,那些关于生活本质的探索。回想第二年大概没有什么人会用这样形容自己的PhD生活,但「自由而热烈」确实是我想到最好的概括第二年的词语,在异国他乡肆意生长是远超科研本身最大的意义。
构筑意义
这一年一直在路上,自从在加州高频次开车,世界顿时就从家附近那几公里地扩展到了地平线的尽头,在东西海岸的里程数加起来也超一万mile了。以前觉得一两个小时的车程都好远,现在自己开车开七八个小时也不觉得枯燥。远距离开车或许是难得的能够全身心放空,欣赏美景,去思考人生的时候;经常上高速开了自动巡航就能以最小的能量去放空,听歌听podcast,当熟悉的旋律响起总是能让我记起自己当时在哪里。
听过很多人提及湾区的无聊生活,但前半年亲身体验反倒总能找到有意思的事情干,或许是太过想要换一种环境去体验不同的美国生活,所以在村里呆了一年出来去哪都觉得是人间天堂。因为有非常正宗的粤菜,去餐厅也能说粤语,所以大概跟在国内也没什么区别,湾区某种程度上已经成为我的第二快乐老家。有时在小红书上看到某家三番的餐厅,可能开车一个钟直接就从南湾杀过去了。湾区的菜肴太对广东人的胃了,试过早早去排早茶位,也刷过米其林三星,在加州半年直接让之前一直说自己不会长胖的我变胖了不少。
湾区的气候也非常适宜,更没有广州那种一到夏季就闷热潮湿之感,对于一个期待一年365天有366天有太阳的人来说,能够每天晒太阳的日子就很快乐。因为每天都在往外面跑,去看海追光,湾区的山和公园基本也被我hike遍了。到处跑开图的过程总会有些意想不到的收获,见到了五彩斑斓的盐田在落日余晖下闪耀着独特的光芒,在一号公路上沿着海岸线吹海风听浪涌,感受了拉斯维加斯纸醉金迷的夜生活与一望无际的荒漠戈壁,在自带复古滤镜的洛杉矶仿佛闯进了上个世纪中国的二三线城市。

在湾区无忧无虑浪了五个月之后,回村第一件事就是去买车。提车当天正好遇到暴风雪,在夜晚能见度几乎为零的高速上把新车开回去也算是难忘的体验。以前在国内因为塞车经常不想开车,但在加州和村里倒是开车开上瘾了,一路非常享受。在加州还不敢从湾区一路开去LA,回来自己买了车就是在村里、Boston和NYC之间来回跑,有车也提供了说走就走的自由,再也不用被bus和飞机的schedule所牵制。
刚回到村里还怕自己会不适应,但发现自己已经练就了超强的适应能力,在大城市有大城市的放纵不羁,在村里也有村里的快乐源泉。伊萨卡虽然村,但终究还是“绮色佳”,世外桃源般的生活环境提供了一种与世无争纯粹的氛围。Cornell的强势学科都是theory和PL这种“没啥用”的东西,大家也就没有这么卷一定要争着热点发paper;相较之下我在西岸每一天都感觉有大新闻发生,一天不关注科技动态仿佛已经落后了一个时代。村里的一切总是会提醒我慢下来,在slope上远远看到Cayuga Lake的波光粼粼就会心情平静;喜欢在Olin看大草坪听钟楼敲钟看夕阳逐渐消失在山间,天边从由红变粉再逐渐暗下去;去Hartung-Boothroyd天文台看星星,沐浴在星空之下,烦恼似乎也会被洗刷干净。
 今年英仙座流星雨在村里天文台拍到的银心
今年英仙座流星雨在村里天文台拍到的银心
这一年在东西岸截然不同的生活体验让我发现PhD更多是构筑意义的过程,一方面是探寻外部世界的意义,另一方面也是给自己赋予意义。在村里遇到的PhD学长学姐自己在家里搭了个暗房洗胶卷,玩赛车组乐队,怎么炫酷怎么来;在公司的mentor,PhD毕业了几年也还是抱有对科研的真挚情感,对自己的领域有着绝对的掌控,同时还有些成熟的稚气(可能是经常跟我发颜文字0.0),每个月都到处去度假,带完我最后一个实习生就跳槽做去startup。很多很多事情都在提醒我PhD并不是只能一条路卷到黑,在路上的风景与其他可能性才是漫长PhD之旅中不能错过的东西。 这也是我这一年的theme,早早认清卷科研也没有办法卷赢那些已经赢在起跑线的人,既然如此不如换个赛道去卷生活,更确切的说法是用心去享受生活。要从卷的路径中逃离出来,对东亚人来说必然是件特别难的事,毕竟从小到大的教育体系都在教育我们怎么卷而不是不卷。有人教我们怎么好好学习,但从不会有人教我们怎么好好生活,但这种技能却是重要且需要习得的。受学长学姐影响,这一年尝试了很多自己以前不会尝试的东西,也找到了自己想要的生活方式。
前段时间被undergrad问到经典的问题,为什么想要读PhD做研究。这个问题其实是跟我做的方向tightly couple的,很难说是因为我接触了而喜好,还是因为喜好而接触。我很喜欢PL和systems research的原因是,它提供了一种具象的能够从零开始搭建起整个世界的能力,这种composability1贯穿着我研究的每一个角落,就像搭乐高一样用几种基本的砖块能够搭建起无比复杂的结构。这个过程可能更像塞尔达,最开始只有木棍可以用,但一旦有了组合技就能够创造出各种奇奇怪怪的黑科技。真实的系统研究甚至比塞尔达还更加有意思,毕竟会直接作用在真实世界。搭自己的框架创造自己想要的东西,继续用现有的工具组合成更强大的东西,最后将困难的问题逐一击破,是件持续让我有成就感的事。
科研谓之为外部世界,关于自我的探索也成为我PhD之旅的必修课。
前段时间重新测了MBTI,发现自己又回到了INFJ,以前测出的不同的结果大概都是INFJ的人格流动性所致。最近也才发现INFJ是极其稀少的人格,总是矛盾地生活在这世上,既想要出世又想要入世,想要自闭与世隔离,却又渴望人群的热闹。“宁愿在纽约睡地板,也不愿在村里住大house”,大致是这么个道理。
 夕阳下的花在墙上投射出了一个心形!
夕阳下的花在墙上投射出了一个心形!
“因为INFJ的感觉是乘以十倍的”,手机相册里存的全是各种光影、猫猫和大海。快乐是十倍的,焦虑与痛苦也是十倍的。现在回看起来大概就能理解当时在国内为什么会这么焦虑,因为骨子里厌恶一切不确定的东西,对生活失去了掌控让自己感受到与世界的剥离。对国内往往复复的封城感到绝望,毕业典礼因为广州疫情被取消,开学依然还有几个月遥遥无期,签证被check也不知道什么时候会下来。在亲密关系中的struggle,对现实的无力,造成了极端的精神内耗。
当Fe太过强大感受到太多这个世界的悲欢离合,所以会被外在的情绪压垮了自身;而Ni的内倾思考已经在脑海中推演了无数种情况,绕了千万次也没有找到出路,是与世界的格格不入之感。当时的情感已经与世界抽离了,跟心理咨询师说我和世界隔着一层膜,现在看来也是是非常恰当的描述。大概是不能接受世界在变得越来越糟的事实,宁愿作茧自缚也不肯去承认那些魔幻的现实。从字节离职那天在五道口的书店蹲坐在地板上空洞地迷茫着未来,回到广州跟心理咨询师聊完在日料店里痛哭流涕,那些经历都真真实实地存在过。以往被忙碌填充而忽略了自己内心的背景板,当忙碌褪去,背景板真正暴露出来,自己独处的时候才发现自己的心灵是多么脆弱。
但换了环境之后这一年习得了很多对未来不确定性的把控,让自己有了稳定的内核。去加州前还在恐惧真正自己一个人怎么有办法过好日子,后来去到湾区自己一个人租房住,自己一个人出游,反而感受到前所未有的快乐。到现在来Austin开会的机票提前半天被航空公司取消了,计划的行程全部被打乱,也能非常心平气和地给老板给出Plan B/Plan C。
听过很多人说读博的痛苦,读博要“甘坐冷板凳”,但我想我并不是typical的PhD。大概是因为在读博前就已经体会完最痛苦的日子,所以从最低谷出发读博的经历倒都是快乐。其实没有必要把自己逼的那么死,生活也没有那么intense,拒稿拒多几次倒也没啥,一个deadline过了还能投下一个。科研只是最简单的一件事,能够把生活过好才是真谛。高中时就想周游世界,想去到各地听人讲他们的故事,因为那些经历与感受是从来不会被写进书本的独特体验。现在还没能周游世界,但有机会去各地开会,认识了很多很多有意思的人,也算是小小地达成目标吧。
这个暑假跟很多人谈心,意识到最重要一点是去接受人格中的一些不完美,不再去纠结过去那些想得到而不能得到的东西,与自己和解算是一种成长;解铃还须系铃人,能够去承认一些问题是没有答案的,有些东西无法被证明也无法被证伪,就像数学体系也是不完备的2,那些无解的问题就让它们石沉大海吧。不去否认过去的事情都是真实的,那些软弱无助的时候,很庆幸自己都走了过来;也不再去担心那些尚未发生的事情,而是更多活在当下感受生活。
在国内这么多年的循规蹈矩,并没有办法抹灭骨子里反叛的火苗,美国大概是让我可以肆意撒欢的地方。滑雪滑板摄影调酒,能够花自己赚的钱买自己想探索的东西就特别快乐。用自己赚的钱买车是我至今下的最大一笔投资,也算是迈向独立与自由的第一步;半年听了三场演唱会,五月天、黄老板还有Radwimps都算是青春的记忆了,总是能在他们身上看到光,现场听live会彻彻底底被他们那种向上迸发的能量感染到。
这一年还跟舍友一起养了只脾气特别好的美短,最开始还觉得他丑丑的,后来生活时间久了就彻底爱上了他的可爱和慵懒。最开始他只是朋友寄放在我们家,但一起生活了一年,也有点成为我们家不可或缺的一部分了。猫咪相处久了好像带着点我的性格——每天都很困,困了就睡觉,喜欢光亮的地方,每天总是在日出日落时分呆坐在窗台上看很久,总是好奇心爆棚在房间里到处捣鼓。
 他叫雷达!小老虎可霸气了!
他叫雷达!小老虎可霸气了!
这些都是读博之余的意外收获。列表上还有太多想做的事,还有太多地方想要探索,或许PhD in snowboarding/skateboarding/photography比PhD in CS更有意思。
变革的世界
这一年也是科技变化翻天覆地的一年,在国内还在为疫情封控而限制技术交流时,ChatGPT就已经横空出世了。有人说ChatGPT将引领下一次工业革命,现在看来我们确实已经站在S型曲线的拐点了3。技术的指数级爆炸是很恐怖的一件事,但在我们固有思维里往往只能看到线性增长。很难想象说ChatGPT才出现了不到一年的时间,而深度学习的这一切都是从2016年之后才开始步入高潮,不到十年时间比计算机出现的几十年间发生的变革还要巨大。都说量变引起质变,而当质变到一定程度,会进一步促进量变的积累,从而导致更迅速的质变。
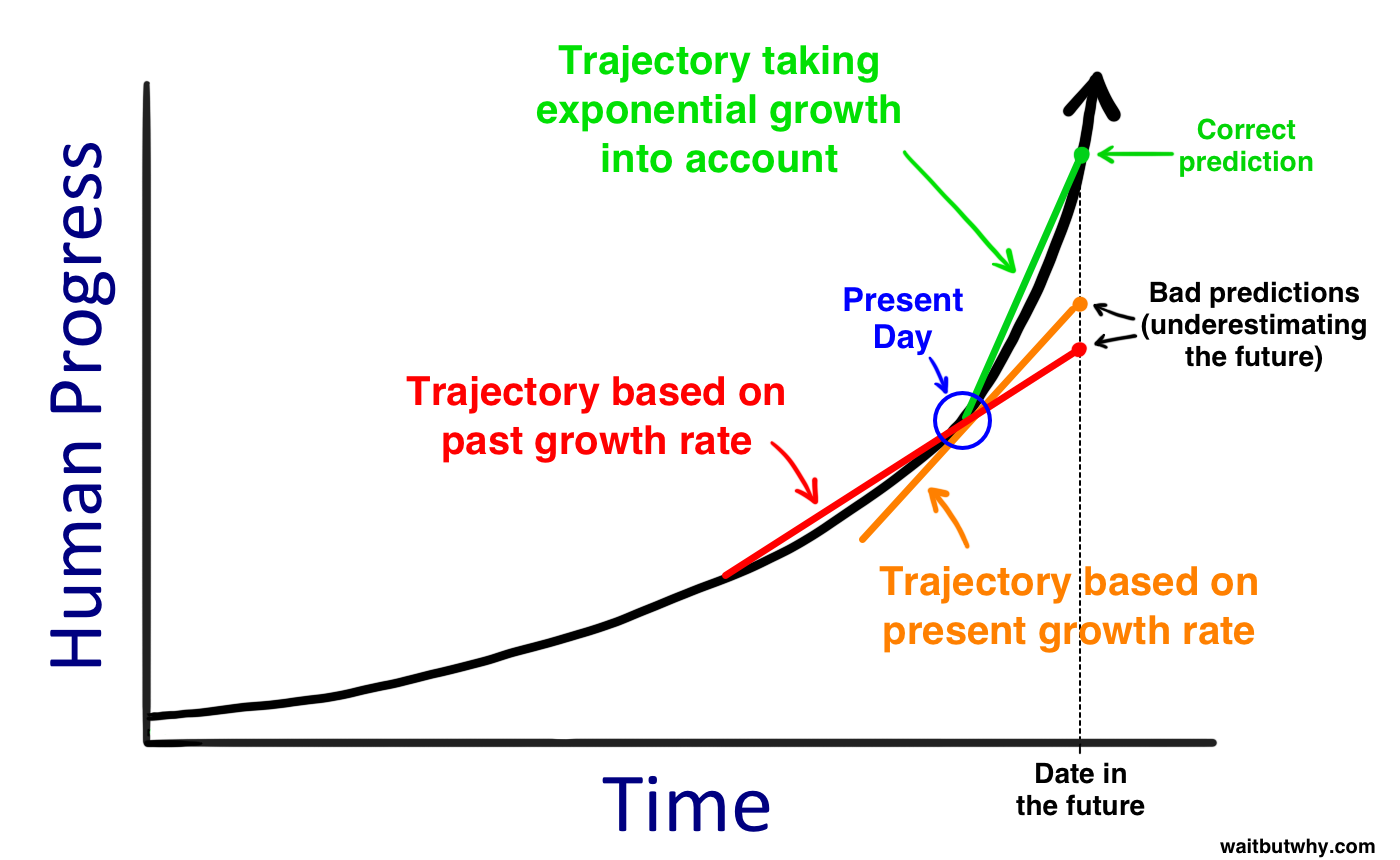 我们总是suppose技术应该step by step地突破,但事实却是技术的爆炸式增长远超我们想象,我们应该用更加aggressive的眼光看接下来十年的进程。强烈推荐阅读Wait but why的这篇文章。
我们总是suppose技术应该step by step地突破,但事实却是技术的爆炸式增长远超我们想象,我们应该用更加aggressive的眼光看接下来十年的进程。强烈推荐阅读Wait but why的这篇文章。
上一次技术的巨大飞跃还是在2016年AlphaGo横空出世的时候,但那时的影响还没有这么深远,下赢围棋真的会对普通人的生活产生多少影响吗,大概率不会。当时人们觉得深度强化学习才是通往通用人工智能的必经之路,DeepMind Alpha的一系列探索也都是在多智能体协作、生物医药、算法发现方面尝试去获得比传统启发式算法更好的解法4,这些问题相比起自然语言处理一个很大的区别在于它们都是well-defined的,所以机器在有限的空间中搜索最优解便成为一个经典的限制优化问题。自然语言处理之所以难是因为人类的语言并没有被良好定义,很多语义是非常模糊的,这种模糊的语义几乎不可能用规则穷举完。之前NLP大量工作也是在上游预处理语料再送入模型训练,但现在ChatGPT非常暴力直接,有什么语料都直接丢进去训练,让AI自行学习其中的规律,效果竟然出奇的好。很多人也没有想过ChatGPT会这么早到来,等到它真正出来之后才发现当初可能点错了技能树(其实ChatGPT也用了深度强化学习去做alignment5)。不仅仅是普通人,甚至业内很多资深的researcher也不相信竟然有人这么快就做出这么惊艳的效果。听很多人提起过Google的趣闻,像最基本的Transformer model和算法都是由Google提出的,但是他们明显也被OpenAI这波操作打懵了,后面只能赶紧launch一个BARD的project企图反超。
本科的时候训过非常小的Transformer model,那时能够填充句子中的一个词就已经很难了,很多情况下因为语料不足,常常会给出一些啼笑皆非的答案。如果要生成整段话更是难上加难,句子可能都读不通顺。所以当去年12月第一次试验ChatGPT的时候,就已经被深深震撼到了,原本以为他只会像以往的那些很蠢的聊天机器人一样给出一些预设的回答。但ChatGPT的聊天过于自然,甚至让人感觉不到是在机器对话,当时有种感觉是ChatGPT已经通过图灵测试了。最开始还只是把它当成聊天机器人在用,但后来随着越多隐藏功能的解锁,人们才发现这个东西不仅能聊天,还可以整理文献、算数学、写代码,几乎所有能用计算机处理的工作它都无所不能。这也是之前一段时间很多人在聊的涌现 (emergence)的能力6,这种涌现在小模型是看不到的,只有当把模型做大了才有办法看到这些特性。这其实也是系统的复杂性,一个一个量级scale上去会有新的现象产生也会有新的bottleneck,从而会产生不同的问题。
想想很多前瞻性的东西竟然都被我碰上了。摩尔定律终结,domain-specific systems是必然,本科时就深受Saman和Kunle组一系列domain-specific compiler和architecture的work影响,想着以后也要做自己的domain-specific language & compiler,但这里的关键在于找对domain。本科的时候做graph processing就觉得这个东西不会火更没有必要为它设计专门的DSL,在字节做GNN system也会发现好像研究的东西就那么多,CV这种deep learning传统的neural network也被TVM做得差不多了,似乎没有更多值得为其专门设计系统的application出现。万万没想到在我PhD期间等到了一个新的domain——LLM的出现彻底改写了CS领域研究的整个格局。
第一件很有前瞻性的事情是在ChatGPT出现前就入局了LLM。故事要从去年三月份开始说起,Shuai当时发邮件问我想不想去Amazon intern做gigantic language model的时候,我还没有任何概念,因为这并不与我的research直接相关我也没有做语言模型相关的经验,但当时我觉得我不应该去拒绝任何可能性,不同的研究方向或许会衍生出一片全新的领域。当时我对NLP除了本科课上的一些浅薄认知几乎没有其他了解,甚至连最基本的attention model有什么组分都没有记清楚,面试时让我现推各种loss function也都是临时恶补的。但没想到最终还是拿到了offer,也在半年时间里把分布式模型训练的前沿摸清楚了7,并且搭出了一个用于大规模训练LLM的原型系统。我8月份入职时从没有想过NLP竟是通往AGI的一个重要分叉口,而如果一直学校里闭门造车是不会知道这么前沿的动态的,我很庆幸自己当时选择了拥抱这种全新的可能性。这次实习的体验也让我发现,真正有影响力,能够给人类社会带来深刻变革的工作现在都只能在工业界完成。工业界占据了大量的计算资源,而只有堆集群堆算力,才有机会看到真正的智能。
 找不到更高清的图了,但还是能隐隐看到当时在用Windows跑ResNet,每晚在宿舍都听着电脑风扇满功率运作睡着
找不到更高清的图了,但还是能隐隐看到当时在用Windows跑ResNet,每晚在宿舍都听着电脑风扇满功率运作睡着
而另外一个前瞻性的事情在于编程模型的使用。17年大学刚入学的时候就参加了天池一个场景识别的比赛,现在来看当时的比赛就是一个ImageNet的变体,算是非常入门和简单,而当时90%的队伍都在采用TensorFlow进行训练,因为那是工业界的标准。因为一个学长的提议,我们把模型实现都从TensorFlow转成用PyTorch。我还记得17年的时候用pytorch v0.2 在Windows下裸装是多么麻烦,各种手动配置CUDA环境,在老旧的GTX 1050(只有4G显存)笔记本电脑上炼丹,还需要采用一些特殊的方法才能让Windows版PyTorch能够跑起来,属实是时代的眼泪了。现在已经到了PyTorch 2.0版本,HuggingFace上90%以上的model都是用PyTorch来写,学术界几乎没有人在用TensorFlow,哪怕Google内部也在用JAX渐渐淡化TF的位置。这个发展的过程就会发现工具带领生产力变革是多么重要。如果说一个算法是从0到1,那programming system则是起到1到1000甚至10000的作用8,就像从汇编到C++/Python真的有什么区别吗,最终代码也要经过一系列lowering跑在图灵机之上,每一段程序每一行代码不过是0/1的一些解析,看上去并没有新创造什么,但是更高的抽象与更强的组合性必然会导致更强大的算法出现。我始终相信编程模型的改变会深刻影响生产力,performance往往不是最重要的东西,shaping how the programmers program is more important。
在AWS的work很大程度上也是follow this line,众所周知大模型需要将模型部署到多张GPU卡甚至多台机器上面,但是怎么做模型的并行成为一个非常困难的问题。Megatron-LM手改model的做法虽然能够达到很高的performance,但是并不通用,一旦上游model改变了下游的优化也要相应改变,这样的程序会变得越来越不maintainable。现在很多的算法改进已经不能在小模型上测了,毕竟如前文所说很多涌现的特性只有当模型达到一定规模才会呈现,这也导致哪怕是算法researcher在实现他们算法的时候也不得不考虑分布式。training efficiency和usability之间的矛盾正是我们这个work想要解决的问题,通过将并行策略以及其他的一些优化从model implementation中decouple出来,让优化策略与模型本身相互独立,从而实现algorithm developers和performance engineers的协同合作,这样哪怕上游的model改动了,我们依然可以很方便运用同一套优化策略。在实现这个编程框架的过程中就会发现分布式训练其实细节的问题非常多,看Megatron-LM的paper那么轻描淡写,但真正要部署下来却非常难,像linear bias在partition之后怎么加,dropout的random state怎么partition,这些问题从来不会在paper里写到,但是却会真实地影响到收敛性9。有一个论断是全世界真正懂大模型训练的不超过100人,这也是成为制约很多公司没有办法训练出GPT4那么好模型的一个原因。在GPT4时代,算法跟数据很重要,但是如果没有专门的系统团队,根本没有办法让那么多机器高效协同运作训练出如此庞大的模型。
关于大规模并行编程模型的探索是我research的一个方面,另一方面则是更多地考虑硬件优化,无论是CPU还是GPU,其实都是去让软件算法/网络结构去适配硬件10,比如FlashAttention也是充分利用了GPU多级memory的特性去融合算子,尽可能减少访问DRAM的访问从而实现性能的大幅提升。但更有趣的可能是尝试去让硬件去适配软件,通过设计出更好的accelerator去fit对应的network architecture来最大化性能输出。同样的,设计高效的加速器本身就是件很难的事情,它不同于直接编写编译软件程序直接就可以在硬件上运行,设计加速去需要我们真正去控制datapath并烧写电路,因此设计空间也会变得异常庞大。我们组一直以来在为降低加速器设计门槛的这件事情上投入了巨大的精力,自19年提出HeteroCL之后也一直在尝试怎么能够更好地抽象编程接口,提供更多的自动化。前年我们为HeteroCL设计了新的MLIR dialect,将整个后端迁移到MLIR之后,解决了一部分问题;但依然发现很多program transformation并没有办法方便实现,毕竟前端DSL用的还是老旧版本TVM的programming interface,这也成为制约我们写high-performance program一个重要因素。一直以来都没有下定决心去把这一切都推翻,因为涉及到大量与历史遗留代码兼容性的问题。但不破不立,之前的框架已经过于臃肿了,继续维护只会难上加难,因此最近还是重新设计了DSL,把整个前端也重写了11,提供了更多的advanced features,希望很快也能把这个work发出来。
What Makes You You
写到这里这个第二年的回忆录已经太长了,但最后的最后还有一个问题值得讨论:究竟是什么让我们区别于其他生物的存在,究竟是什么构成了人类的独特性呢?
无论是做算法理论研究尝试让神经网络变得泛化学到更多的知识,还是做系统研究尝试去榨干现有机器的性能,我们都是在加速强人工智能出现的进程,而且这一天不可避免地会很快到来。这大半年ChatGPT的不断进化也让我感觉到它似乎不再是最初的那个模型了,这种自我迭代的学习能力是非常恐怖的。有不少AI领域的先行者也在警告现在AI的进展太迅速了,正如前面技术指数级爆炸所预言的一样,一旦超过某个threshold,可能AI将在几分钟之内成为super intelligence彻底碾压人类的智力水平,这将直接诞生一系列的伦理问题。
《Her》中所言的每个人都有自己的赛博男/女友也许等GPT提升共情力后很快就会实现,最近脑机接口的飞速发展似乎让《万神殿》中预言的uploaded intelligence在有生之年也能得到突破。将自己的记忆与行为都上传云端,这一切都会导致真实与虚拟的边界模糊,那究竟是实体还是意识能够定义一个人呢?会不会情感也是语料中的隐藏维度12,就像人的各种情感本质上也不过是电信号的传递和一些化学反应。情感能够作为emergence的一部分被涌现出来吗,又或许理性与感性本来就是一体的?这些问题或许都值得我们重新去思考。
或许感知这个世界的能力,那些混沌运动中无法被捕获的生活连续的片段,无法被解析表达的情感与随机性,才是最独特的能够定义一个人的东西。
尝试理解这个世界抽象的复杂性,在杂乱无章的世界里把生活过成诗,这是我第二年的注解。
-
圆角骑士魔理沙,PL的赞歌是组合的赞歌! ↩
-
Tim Urban, The AI Revolution: The Road to Superintelligence ↩
-
David Silver et al., A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play, Science, 2018 ↩
-
OpenAI, GPT4 Technical Report, arXiv, 2023 ↩
-
Jason Wei, Emergent Abilities of Large Language Models, arXiv, 2022 ↩
-
强烈推荐沐神在B站上一系列关于分布式系统的paper精读视频,最开始也是通过沐神的视频入了LLMSys的坑。虽然跟沐神在同个组,但直到他离职也没能跟他说上话,也算是实习的一个遗憾了。 ↩
-
Nicolas Vasilache et al., Composable and Modular Code Generation in MLIR: A Structured and Retargetable Approach to Tensor Compiler Construction, arXiv, 2022 ↩
-
Sara Hooker, The Hardware Lottery ↩
-
重新设计programming interface算是叶老板给的建议,深以为然,今年开完ISCA回来之后就立即行动了。这一年跟叶老板见了三四次,每次都恬不知耻地向叶老板请教问题,从MLSys到UW再到PLDI,我们真是从西海岸一直见到东海岸,每次都获益良多。 ↩
-
现在已经有很多情感二分类的work,但是人格也好情感也好并不是一个简单的MBTI就能够衡量的,它也许是在连续空间变化的函数。 ↩