Hongzheng Chen Blog
剖析 FPGA 加速大模型推理的潜力
Dec 28th, 2023 0- TLDR: 用 FPGA 加速 LLM 推理在特定场景下能够达到比 NVIDIA A100 GPU 更高的性能和更低的能耗,但并非所有场景都适合用 FPGA。
- 论文链接:https://arxiv.org/abs/2312.15159
- 代码链接:https://github.com/cornell-zhang/allo/tree/main/examples
- 原文链接:https://chhzh123.github.io/blogs/2023-12-28-fpga-llm/
Hongzheng Chen, Jiahao Zhang, Yixiao Du, Shaojie Xiang, Zichao Yue, Niansong Zhang, Yaohui Cai, and Zhiru Zhang. 2024. Understanding the Potential of FPGA-based Spatial Acceleration for Large Language Model Inference. ACM Trans. Reconfigurable Technol. Syst. 18, 1, Article 5 (March 2025), 29 pages.
这一年生成式大语言模型(large language models,LLMs)的爆火直接促进了 NVIDIA 卖卡的进程,股价直接翻了几番,现在高价求卡都还一卡难求。NVIDIA 的 GPU 虽好,它高额的成本和产生的电费让很多人望而却步。为了实现更加高效的 LLM 部署,最近几个月来互联网厂商一方面继续买 N 卡,另外一方面也在寻求替代品。所有人都知道需要寻找一种更加高效且低功耗的加速器,但究竟什么硬件才能实现这个目的。一些厂商直接开始了造芯进程(Google 的 TPU,Amazon 的 Inferentia,和 Microsoft 刚出的 Maia 等等),但是造芯的周期太长,一旦流片也很难跟上瞬息万变的模型发展(Maia 尴尬的内存带宽就是个例子)。而在通用处理器 CPU/GPU 和专用加速器 ASIC 中间其实还有一种硬件,既能做到一定的可编程性,又能达到比通用处理器更高的性能,这就是可编程门阵列 FPGA(Field-Programmable Gate Array)。目前最大的 FPGA 厂商是 Xilinx(已经被 AMD 收购),其芯片也陆续被集成进现在高端的 SoC 里面。我们最近的工作正是要探讨利用可重构硬件 FPGA 到底能不能在 LLM 这波浪潮下占据有利地位,以及 FPGA 在大语言模型推理上究竟能够释放多大的潜力。
找对 FPGA 的应用场景其实很重要,要发挥其最大功力一定要考虑其重构性(reconfigurability)。之前很多工作1都尝试在 FPGA 上搭指令集架构(或称覆盖 overlay),但其实这是对 FPGA 的一种极大误用,因为一旦做成专用电路,将对应的架构做成 ASIC 总是可以比 FPGA 更加高效,那 FPGA 不过是一个实验性 prototype,它可重构的特点基本上就没有办法发挥出来。指令集架构如 CPU 最大的性能和能耗开销正是在指令解码和多级内存访问上,如果能够将这些额外开销消除,那实现的硬件将非常高效。我们希望实现的是针对模型定制化的(model-specific)完全展平的数据流架构(dataflow architecture),一方面能够最大程度减少片下内存(offchip memory/DRAM)访问从而降低能耗,同时因为没有 cache 的影响,实现的加速器也能具有确定性的时延(latency)。相比已经固化的 ASIC 电路,这种方式可以对新兴的复杂多变的网络结构进行重构,更加具有灵活性。
上述两种方案在我们 paper 里又被归类成 temporal 和 spatial 两种不同的 architecture,前者指在时间上复用同一个大而全计算单元,后者则是直接将不同算子的计算单元用 FIFO 进行相连形成一个流水线型的数据流架构。
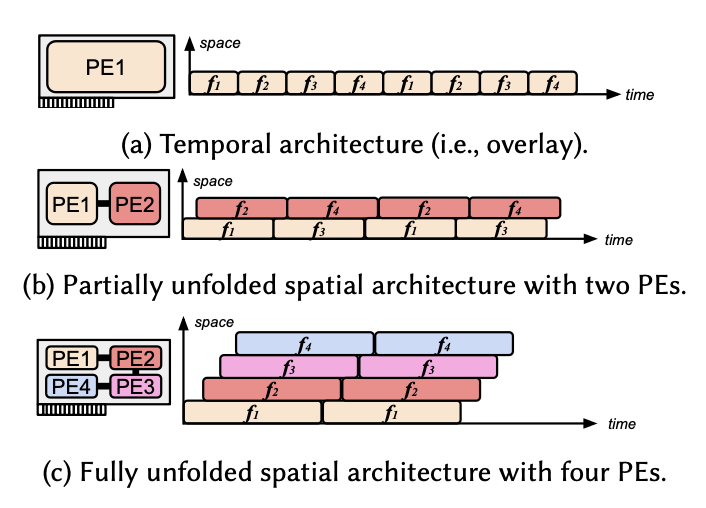 PE是不同的处理引擎(Processing Engine),f1-f4是模型中不同的算子
PE是不同的处理引擎(Processing Engine),f1-f4是模型中不同的算子
与之前的工作不同,我们并非要提出一个 state-of-the-art 的加速器;相反,我们提供了一个理论分析的框架,可以方便且准确地预测不同的 FPGA 设计能够达到的性能,同时我们也可以知道 FPGA 所能达到的理论上限以及与 GPU 的差距,从而来引导我们设计真正高效的加速器。基于这个理论分析,我们选择了一些数据点进行实现和验证,最终实现的 FPGA 加速器在特定模型上已经可以达到比 A100 更低的延时和更低的能耗。
背景知识
大语言模型推理一般分为预填充(prefill)和解码(decode)两个阶段2。预填充主要负责将用户输入的 prompt 读进来,然后生成第一个 token,而解码阶段则是所谓的自回归(autoregressive)过程,即根据上一个 token 生成下一个 token,直到生成结尾单词(EOS)为止。单从这个流程就可以发现,其实两个阶段的需求并不一样,第一个阶段由于读入多个 token,序列长度大于1,因此核心的计算是通用矩阵乘(General Matrix Multiply,GEMM);而后一个阶段是一个一个 token 进行处理,因此核心计算转换为通用矩阵向量乘(General Matrix-Vector Multiply,GEMV)。通常来讲 GPU 在预填充阶段由于有巨大的算力,所以可以达到比较高的性能;但是在解码阶段由于没有足够的并行度倒是 GPU 利用率低,所以性能并不高,这在后面的案例分析中也会有讨论。我们在这里主要讨论单批次(single-batch)推理的场景,看最终的延时能够减少到多少。
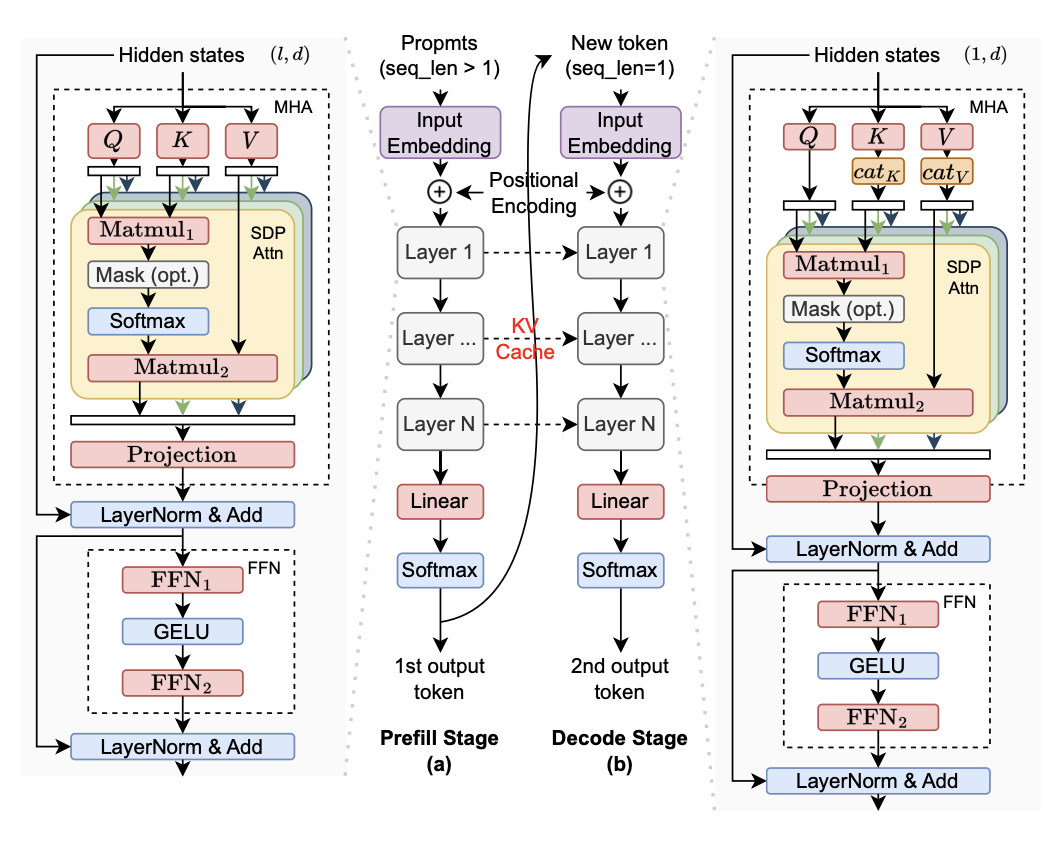 两阶段大模型推断
两阶段大模型推断
理论分析框架
我们主要考虑 Transformer 里面的线性层(linear layer),因为这些层占据了主要的计算和内存资源,而非线性层实际上在 FPGA 上用组合逻辑可以非常高效地实现,因此不在这里进行讨论。
算力需求
算力需求算是做 LLMSys 一个最基本的分析了,类似于@陈乐群 的 剖析GPT推断中的批处理效应,我们也可以将两个阶段每个线性层所需的计算量统计成表格,注意这里我们并没有采用大 O 记号,这是 GPU 与 FPGA 估计的一大区别。有了每个算子精确的计算量,我们就可以对 FPGA 加速器的整体延时做精确估计。
 l是序列长度,d是隐含层维度
l是序列长度,d是隐含层维度
为了最大程度发挥定制化硬件的性能,我们假设每个线性层都已经进行了量化(quantization),即里面的计算都可以高效地用整数乘加进行实现,这样每个乘加运算(Multiply-Accumulates,MACs)都可以在一个硬件周期内完成。同时我们假设 $M_i$ 是分配给每个线性层的算力,即每秒能够执行的乘加运算,以 MACs/cycle 为单位,因此比如 $Q$ 对应的线性层就可以在 $ld^2/M_q$ 个周期内完成。
这个算力是有上限的,其上限即为硬件所能提供的最大算力,在 FPGA 上也就是 DSP 的数目(通常一个 DSP 可以在一个周期内实现一个整数乘加)。我们可以得到下面的限制条件
\[\sum M_i C<M_{tot}, i\in\{q,k,v,a_1,a_2,p,f_1,f_2\}\]其中 $C$ 是在一块 FPGA 上部署的 Transformer 层数,$M_{tot}$ 是 FPGA 上所有等效 DSP 的总数目,可以通过查每个厂商的 FPGA 芯片手册得到。
内存容量限制
这个限制比较显然,将所有参数需要的存储容量加起来,只要不超过 FPGA 总的 DRAM 和 BRAM 容量就可以了。这里我们将参数存在 DRAM 上,要求所有参数量小于 DRAM 的容量
\[S_{param} C < DRAM_{tot}\]而片上内存主要存储分片(tile)后的参数、KV cache 和中间存储激活值的 FIFO,可以得到
\[\sum S_i C < SRAM_{tot}, i\in\{tile, KV, FIFO\}\]内存端口限制
这个问题其实更加严重,也是 FPGA 独有的问题。虽然 FPGA 有充分的可重构性,但是其可重构性并不是针对任意的内存访问带宽都成立的,比如对于 AMD UltraScale+ FPGA,就只有 $\{1,2,4,9,18,36,72\}$ 这几个位宽可以选,因此如果位宽不够的话就得做 padding,从而造成 BRAM 的浪费。
由于不同的计算单元需要对数据同时进行读取,为了避免内存访问冲突,我们需要将对应的数据分配到不同的端口上。假设线性层 $i$ 的参数量为 $s_i$,并且有 $M_i$ 个 MAC 计算单元并行执行,其中 $r_i$ 个计算单元会分享同一个加载的参数,因此权重缓存(weight buffer)需要被划分为 $M_i/r_i$ 个分片。如果权重缓存存储在片上,且每个元素的位宽为 $b_W$,那么每个分片得到的元素个数为 $s_i/(M_i/r_i)$。又由于 $b_W$ 不能占据 BRAM 的所有位宽,我们引入 $b_{BRAM}$ 为比 $b_W$ 大的最小合法 BRAM 位宽,$S_{BRAM}$ 为一个内存单元的总容量(比如 AMD FPGA 的 BRAM 容量为 36Kb),那么我们可以得到对于一个线性层来说需要的 BRAM 数目为
\[R_i=\left\lceil\frac{s_i b_{BRAM}}{M_i/r_i\times S_{BRAM}}\right\rceil\times M_i/r_i\]但明显这种方式对于内存的使用是非常糟糕的,我们可以通过将多个元素进行打包(pack)从而实现更高效的内存使用。假设我们打包 $k$ 个元素,即 $b_{pack}=k b_W$,那么我们可以得到新的内存需求
\[R_i=\left\lceil\frac{s_i b_{BRAM}}{M_i/r_i\times S_{BRAM}}\right\rceil\times \frac{M_i/r_i}{k}\]通过将所有线性层的内存需求相加,我们可以最终得到总的内存需求,这个值也需要小于对应的 BRAM 内存容量。
内存带宽限制
最后是内存带宽的限制,由于每个周期需要从 DRAM 中加载 $M_i/r_i$ 个参数喂给 $M_i$ 个计算单元,因此需要的带宽是
\[B_i = b_W\times M_i/r_i\times freq\]其中 $freq$ 是 FPGA 的频率,最终 $B_i$ 的总和也需要小于总的 DRAM 带宽。
延迟估计
在 FPGA 上实现数据流就可以做到非常高效,大部分的算子都可以被重叠到一起,即不需要等上一个算子的结果全部输出就可以进行下一个算子的运算。唯一需要等待的是 q/k/v 线性层和后面的注意力模块,因为这里需要计算 K 和 V 的值,并且存储/合并 KV cache,所以流水线在这里需要等前面的结果全部算完后再进行下一步的计算。因此我们可以得到下面这幅两阶段的流水线图,每个阶段的时间都大致为 $t$。
(Note:这里也可以发现 FPGA 数据流实现的一大好处——某种意义上这些算子都已经自动实现了算子融合,因为上一个算子的输出数据可以直接传到下一个算子作为输入,而不需要写回内存,因此也不需要像 GPU 一样搞各种 FlashAttention 的优化来进行算子融合。)
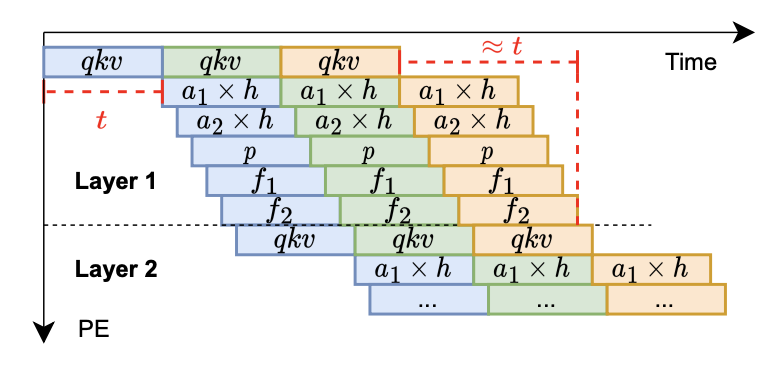 多个算子的流水线
多个算子的流水线
基于我们上述定义的算力 $M$ 和每个算子的计算量,我们可以估计出最终的延迟
\[T_{prefill}=\frac{1}{freq}\frac{N}{C}\left(\frac{ld^2}{M_k}+C\max\left(\frac{ld^2}{M_k},\frac{l^2d}{M_{a_1}},\frac{ldd_{FFN}}{M_{f_1}},T_{mem}\right)\right)\] \[T_{decode}=\frac{1}{freq}\frac{N}{C}\left(\frac{d^2}{M_k}+C\max\left(\frac{d^2}{M_k},\frac{(l_{\max} + 1)d}{M_{a_1}},\frac{dd_{FFN}}{M_{f_1}},T_{mem}\right)\right)\]其中 $N$ 是总的 Transformer 模型层数,$T_{mem}$ 是 DRAM 访问的延时,$l_{\max}$ 是最长的序列长度。
如果考虑负载均衡,上述公式还可以进一步简化成
\[T_{prefill}=\frac{1}{freq}N\left(1+\frac{1}{C}\right)\frac{ld^2}{M}\]可以看到最终预填充阶段的延时跟序列长度成正比,而解码阶段的延时则几乎为常数(因为 $l=1$)。结合前面的限制条件,我们可以利用简单的线性搜索解得到最优的 $M$ 值。多卡的分析在此不再赘述,详情可以参见我们的论文。
案例分析
接下来我们用上述框架预测一下现有 FPGA 在 LLM 推断时的性能,这里我们主要考虑 BERT、GPT2 以及 LLaMA2 几个模型。下面表格列举了我们进行比较的 FPGA 和 GPU 的核心参数。稍微对比一下 A100 与其他设备的数据就可以发现,A100 实在是一骑绝尘,浮点峰值性能都远超 FPGA 的整数峰值性能,同时内存带宽也达到了惊人的 2TB/s。现有的 FPGA 明显还是上一代的产品,跟 A100 的参数完全没有办法对标。但即便如此,我们还是分析了差距有多大以及怎么去弥补这个差距。
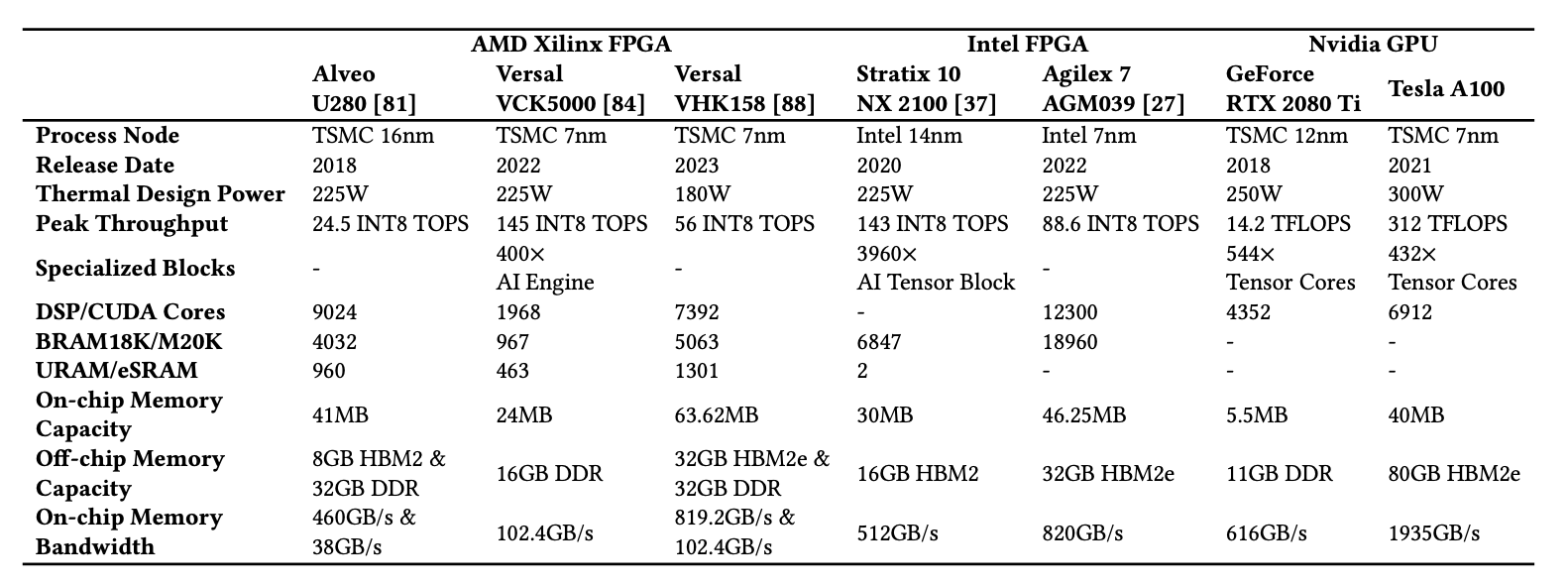 目前常用的 FPGA 和 GPU 设备参数
目前常用的 FPGA 和 GPU 设备参数
首先我们来看一下整体的延时,这里我们实测了 A100 和 2080 Ti 两块 GPU 的 fp16 性能,同时估计不同 FPGA 设备的理论最优延时,结果如下图所示。事实证明 GPU 在预填充阶段由于算力充足,改变序列长度基本不影响延时,而 FPGA 在预填充阶段想要达到 A100 的性能还是难度很大的(其延时是随序列长度线性增长的)。本来像 VCK5000 等专门为 AI 应用优化过的 FPGA 应该能够达到 GPU 的性能,但是比较迷的是 Xilinx 当时并没有给它加上 HBM,导致内存带宽严重受限。
相反,在解码阶段,FPGA 完全有可能达到比 GPU 更优的延迟,这主要是因为 GPU 在这个阶段没有办法充分利用其并行度,所以对于 GPU 来说一个常见的优化就是做各种 batching 去尽可能提升资源利用率。
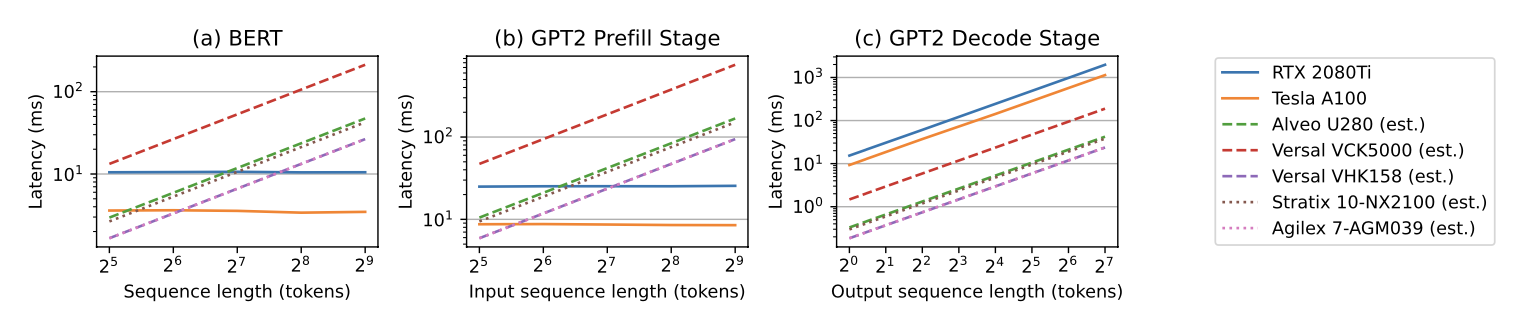 在 BERT 和 GPT2 模型上的延迟估计,GPU 的数据是实测值
在 BERT 和 GPT2 模型上的延迟估计,GPU 的数据是实测值
在 LLaMA2 模型上的数据更加说明这一点,FPGA 需要开到非常大的并行度才有办法在预填充阶段与 GPU 抗衡,而在解码阶段 FPGA 只需比较小的并行度即可达到 GPU 的性能。当然,最近很多 LLM 优化的框架也在不断推进 GPU 的性能(参见GPT-fast),目前优化到最好的 LLaMA2 模型大约能够达到 200 tokens/sec 的性能。对于 FPGA 来说,利用拥有最新 HBM 的设备(如 VHK158)还是能够跟 A100 拼一拼的。我们也可以通过 GPU 的性能指标,来反推 FPGA 的并行度需要达到多大才能与 GPU 持平。
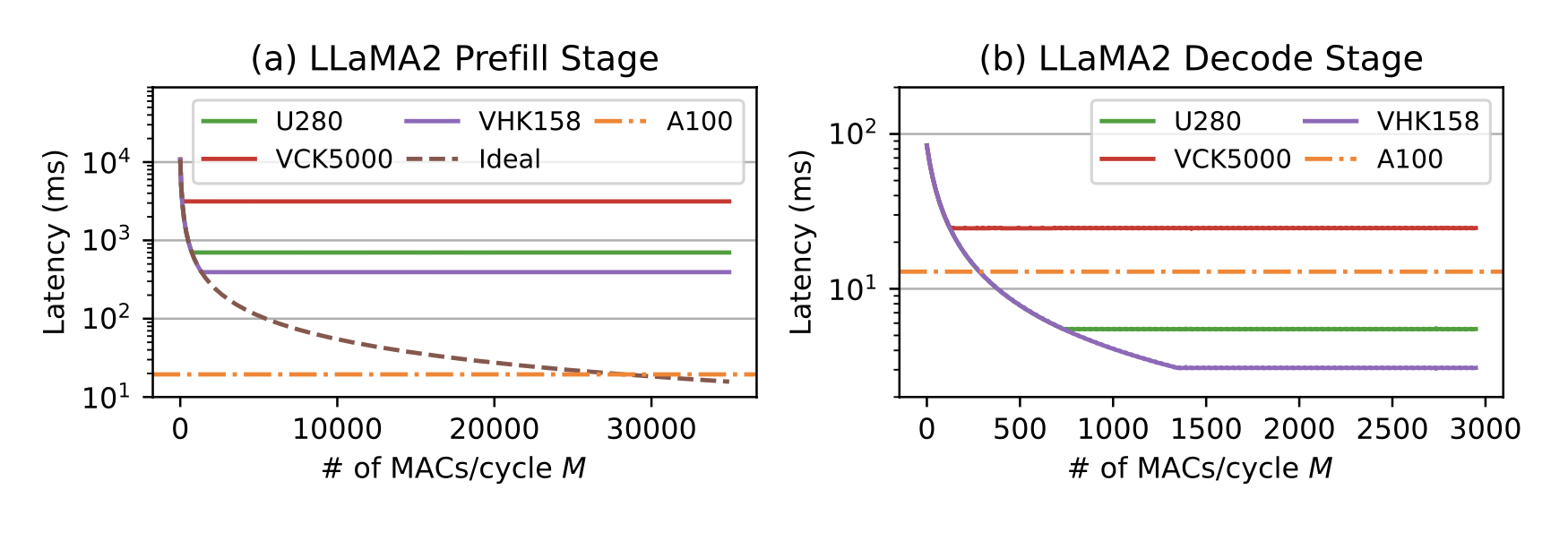 在 LLaMA2 模型上的延迟估计,GPU 的数据是实测值
在 LLaMA2 模型上的延迟估计,GPU 的数据是实测值
我们也进一步分析了量化和数据打包对延时的影响,这里直接给出结论:
- 权重量化非常重要,一方面可以降低 BRAM 资源占用,另外一方面也是减缓 DRAM 的带宽压力。
- 激活值量化对内存占用影响不大,因为数据流架构基本不需要存储中间的激活值。
- 数据打包对减少 BRAM 端口数目,降低资源占用至关重要,这也有利于后端的布局布线。
最近的一些量化工作(如 UW 的 Atom 3 和 我校的 QuIP4)都开始往 4-bit 甚至 2-bit 推进,他们的实验结构都证明了低位宽的 LLM 是完全有可能达到 fp16 模型的准确率的,因此这也给高效的 FPGA 实现提供了可能性。
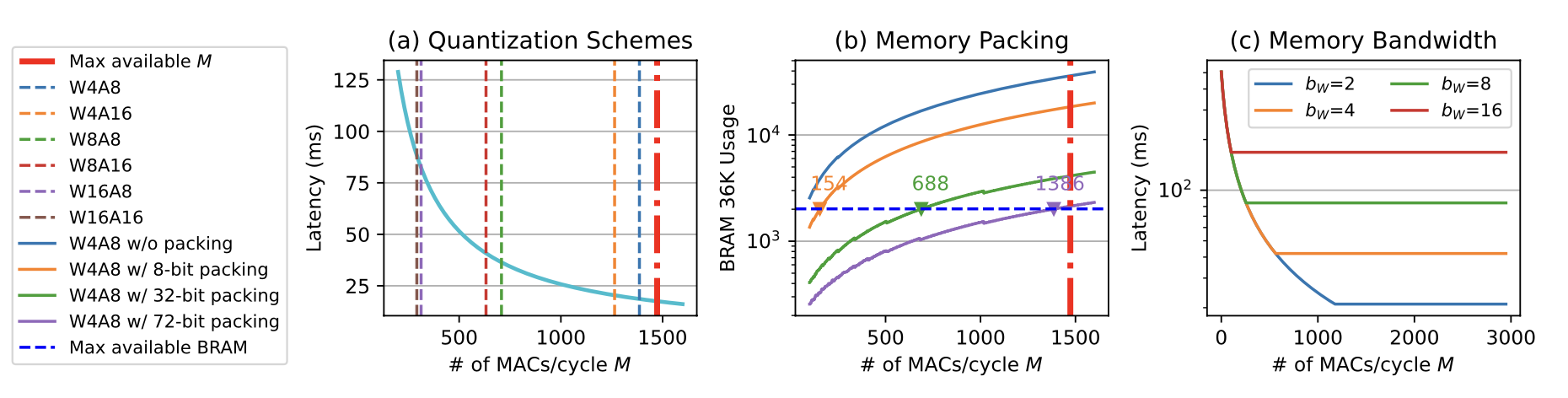 量化及数据打包对性能的影响
量化及数据打包对性能的影响
实验结果
仅仅理论分析是不够的,我们利用高层次综合(high-level synthesis,HLS)实现了一系列高性能的算子。对于线性层我们采用了脉动阵列(systolic array)进行实现,然后将多个脉动阵列用 FIFO 进行串联构成完整的 Transformer 层,这种串联方式也是之前的工作从未尝试过的。我们选取了 $M=128$ 的数据点进行实现,即脉动阵列的大小为 $8\times 8$(我们采用了 DSP packing,因此算力值可以翻倍),如果并行度再往上涨就会出现比较严重的 routing 问题。同时我们手动将模型划分到不同的逻辑块上(super logic region,SLR),这样可以进一步降低走线的压力,从而提升频率。
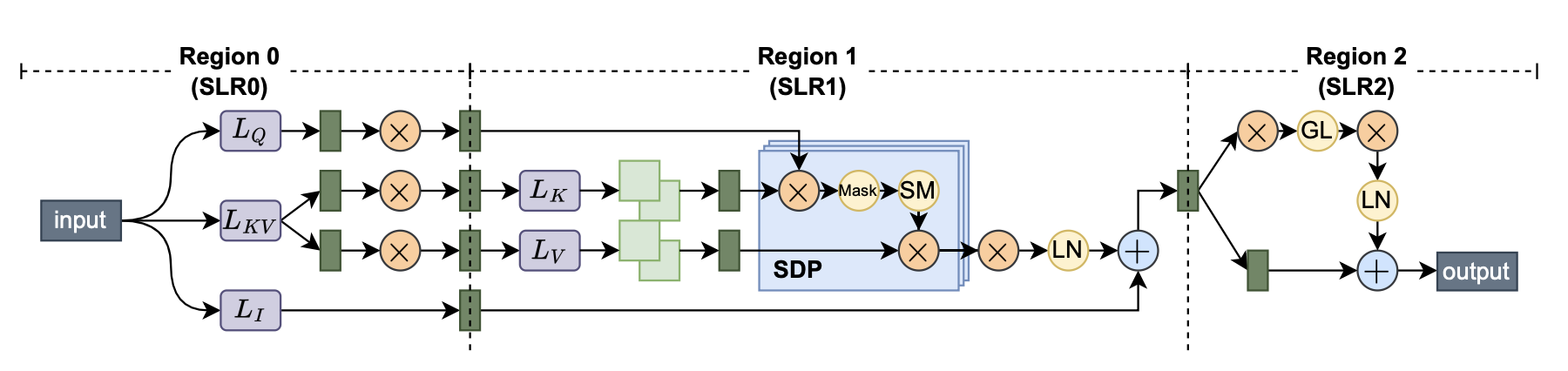 最终的加速器架构
最终的加速器架构
这里我们只放主要结果,在小的 GPT2 model 上,我们用 16nm 的 U280 FPGA 已经可以实现超过 7nm A100 GPU 接近1.9倍性能的推断加速比,同时比其能耗低 5.7 倍。
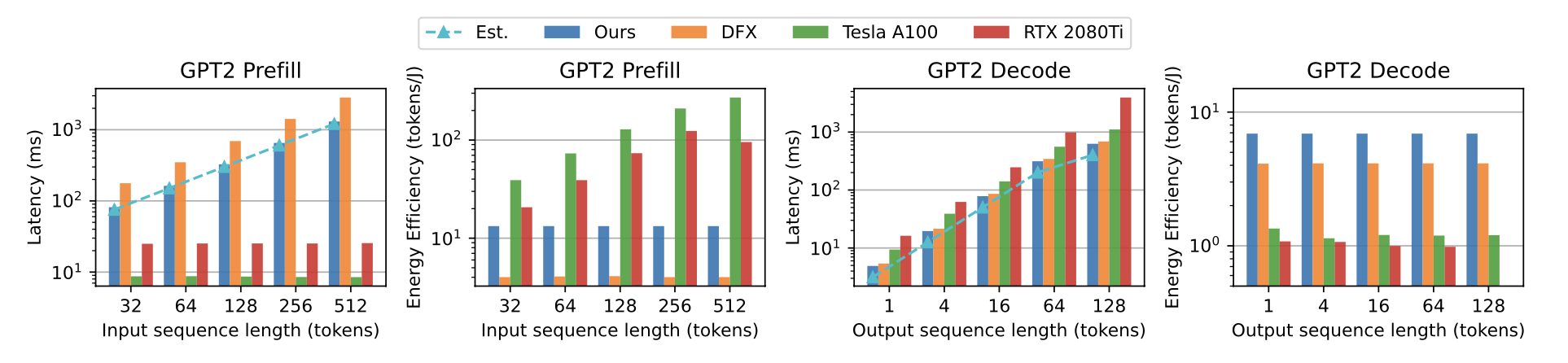 FPGA 加速器在 GPT2 模型上的延时与能耗实测
FPGA 加速器在 GPT2 模型上的延时与能耗实测
对于更大的 model,我们预计于明年上半年与我们的编译框架一同放出。事实上清华汪玉老师组的无问芯穹也已经做出了对应的 FPGA 加速器并且在 LLaMA 上呈现了比 A100 更好的 performance,大家之后也可以多加关注。
讨论
从延时的公式中,我们可以看到,要提升总体性能,其实有一个直接的方式是提升频率 $freq$。之前的工作大部分都是在 200MHz 左右,而我们的设计已经可以推到 250MHz,但是更往上推就会遇到 routing 的问题。将并行度 $M$ 给 scale up 的过程也会导致更大的走线压力,我们之前尝试使用 AutoBridge5 等框架来优化布线,但是这些框架对于复杂的数据流架构还是非常麻烦,需要进行大量的程序改写,并且多层级的数据流也没有良好的支持。
另外一方面我们也看到了 FPGA 自定义数据流在解码阶段的巨大潜力,一个直接的想法则是利用 GPU 加速预填充阶段,用 FPGA 加速解码阶段,这样可以充分发挥两者的优势。作为 NVIDIA 的对家,AMD 其实下了非常大的赌注在异构计算上,这也决定了到底能不能 AMD yes。其收购了 Xilinx 也是看中了FPGA的场景,再加上最近发布的 AIE 更加表明 AMD 想要充分利用异构硬件的优势,实现更高效的加速计算。事实上 AMD 已经将 FPGA 集成进他们的 CPU 里面了(参见 XDNA-AI Engine),所以异构计算也提供了弯道超车的可能性。
正如前文所说,仅仅提出一个高效的专用加速器架构并不是我们的最终目的,我们更希望能够有完整的框架适用于不同的应用不同的模型,并且快速生成高效的加速器架构。这也是我们同时进行的编译器项目想要实现的事情,上述的 HLS 算子也都直接由我们的编译器生成,对应的算子库及编译器都将在明年一起放出。
致谢
这个 project 从 23 年的春季学期就开始做了,期间 LLMSys 相关的工作层出不穷,我们对 LLM 性能瓶颈和优化的认识也提升了不少。特别感谢 Jiahao 带飞整个加速器设计,他是我至今见到最 productive 的 undergrad,从零开始搭建搭建起每个 LLM 的模块并组合成完整的加速器,初版的设计他可能用不到一周时间就写完了,组里的 PhD 得知后都非常震惊(Jiahao 今年也在申请 PhD,感兴趣的老师可以联系他 :))。也特别感谢 Yixiao 带我深入剖析加速器结构并且搭起了理论分析的框架,这是我做过最 architecture 的 project 了,没有他的协助我可能真的没法搞清楚后端综合出现的各种问题。还有其他的合作者 Shaojie/Zichao/Niansong/Yaohui 也对这个 project 的模型量化、实验、理论分析等方面做出了很大的贡献,一并在此感谢!
另外特别鸣谢叶老板 @yzh119 在 LLM 相关 project 上的深入讨论,以及介绍 UW 的朋友一起探讨,本文的写作受到了很多启发。
参考文献
-
Seongmin Hong, Seungjae Moon, Junsoo Kim, Sungjae Lee, Minsub Kim, Dongsoo Lee, Joo-Young Kim, “DFX: A Low-latency Multi-FPGA Appliance for Accelerating Transformer-based Text Generation”, MICRO, 2022. ↩
-
Reiner Pope, Sholto Douglas, Aakanksha Chowdhery, Jacob Devlin, James Bradbury, Anselm Levskaya, Jonathan Heek, Kefan Xiao, Shivani Agrawal, Jeff Dean, “Efficiently Scaling Transformer Inference”, MLSys, 2022. ↩
-
Yilong Zhao, Chien-Yu Lin, Kan Zhu, Zihao Ye, Lequn Chen, Size Zheng, Luis Ceze, Arvind Krishnamurthy, Tianqi Chen, Baris Kasikci, “Atom: Low-bit Quantization for Efficient and Accurate LLM Serving”, arXiv:2310.19102, 2023. ↩
-
Jerry Chee, Yaohui Cai, Volodymyr Kuleshov, Christopher De Sa, “QuIP: 2-Bit Quantization of Large Language Models With Guarantees”, NeurIPS, 2023. ↩
-
Licheng Guo, Yuze Chi, Jie Wang, Jason Lau, Weikang Qiao, Ecenur Ustun, Zhiru Zhang, Jason Cong. “AutoBridge: Coupling Coarse-Grained Floorplanning and Pipelining for High-Frequency HLS Design on Multi-Die FPGAs”, FPGA, 2021. ↩