Hongzheng Chen Blog
PhD第四年 - 加速世界中的存在主义
Dec 31st, 2025 0终于有时间来写年终总结,2025仿佛被按下快进键,世界在飞奔,一年时间堪比之前几十年的发展。
这一年经历了两次切身体会的震撼,第一次是年初的时候DeepSeek-R1出来,发现在中文语境下LLM已经能够模仿各种作家写作文风,也能够通过长时间的思考实现复杂的编程问题。当时已经隐隐约约感觉到自己手头上做的很多东西并没有什么意义,那一整周跟朋友讨论了很长时间的存在主义危机。而后我们发起了HeuriGym,想知道最前沿的LLM在一些实际的问题上表现如何,以及我们还有多久会失业。
第二次则是我在DeepMind实习被AlphaEvolve万物皆可进化的能力所震撼,在几小时内就突破了领域里十几年来累积的成果,也基本宣告了这个方向接下来的快速终结。这一年我很清楚地看到尽管人们鼓吹的AGI还没到来,但是以现有LLM的能力已经能够解决非常多现实中我们所关心的问题,给社会带来巨大变革。
『不要用人类巧思去对抗机械暴算』这是bitter lesson告诉我们的。当LLM战胜了所有的人类巧思,人类究竟还剩下些什么呢?
在agentic时代,环境赋予的context对agent来说至关重要,其实人也一样。人与人agent与agent之间的独特性,正是在一次次与环境的交互之中产生了差异。这一年尽管每天都在连轴转,但还是没有忘记去探索世界,去真实地感受生活。在科州冲了粉雪小树林也体验了体感零下30度的狂风,在日内瓦站上了从未设想过的讲台宣传自己的工作,在伦敦逛遍了museum也吃上了米三,在纽约有生之年听到了八爷的巡演,在Baker和Tahoe找到了属于自己的精神自留地,这些无法被数字化的经历与感受创造了2025年最独特的context。
加速!加速!加速!
加速必然是今年整个世界的主题,很难想象在2025年初的AI模型跟2025年底的AI模型差距有多巨大,每个模型厂商都在快马加鞭。2024年底本来以为pre-training和post-training训出来的model大概很难再有突破了,但事实证明我还是低估了模型发展的速度,没想到test-time scaling能让模型学会内在思考从而实现能力进一步提升。而DeepSeek-R1的出现更加让市场意识到,LLM是一场不能输的战役。技术迭代不是线性进步,范式跳跃带来的质变更为恐怖。虽然DeepSeek本质上是证明了LLM能够用更少的成本进行训练,但这不意味着scaling的终结,所以1月的美股暴跌并没有什么道理。后来美股重新回到轨道,NVIDIA也因此在这波浪潮下成为第一个突破4万亿市值的公司1。
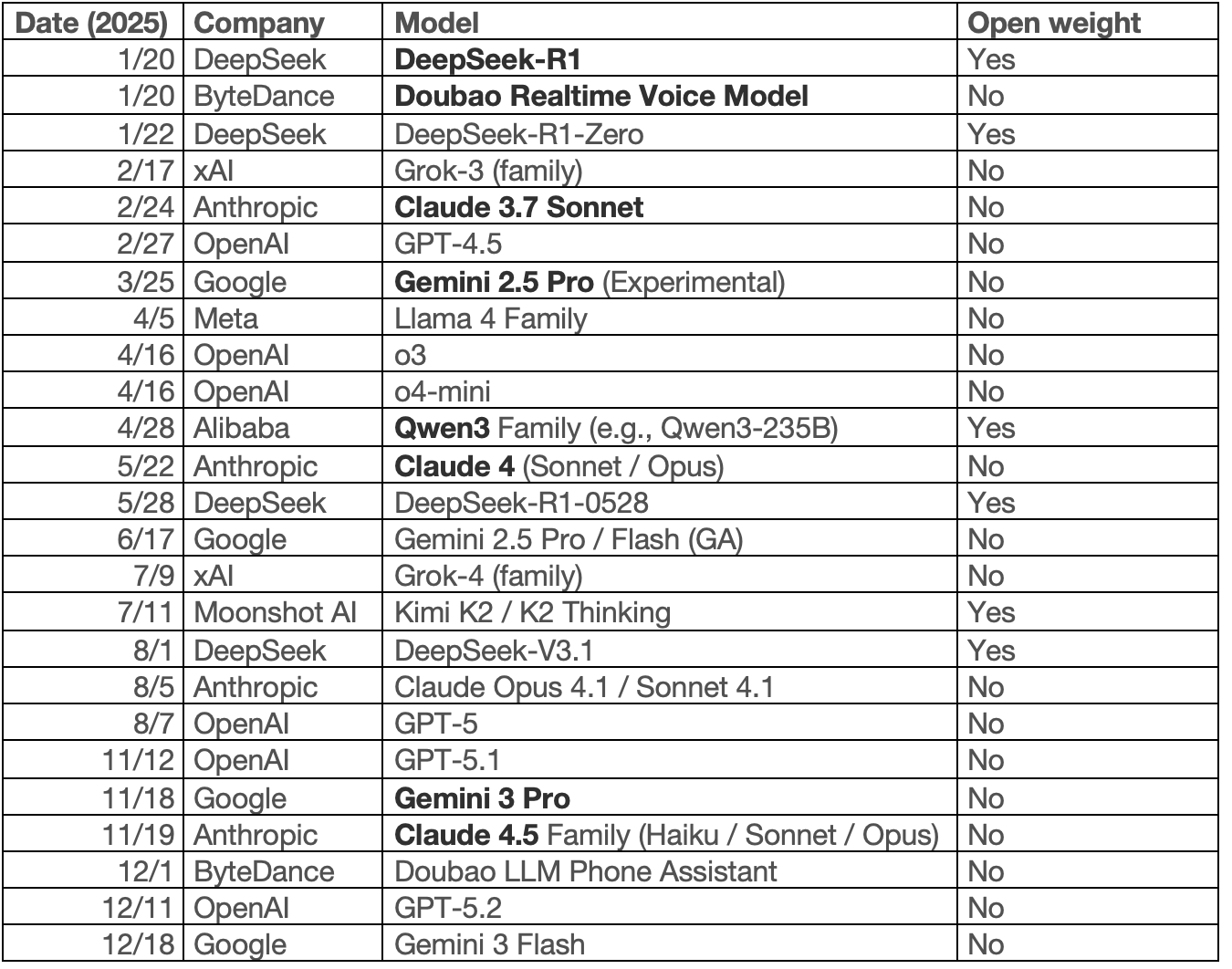
2025是名副其实的“百模大战”,各家厂商的模型呈交替领先的态势2。我让GPT总结了2025年主要model的发布时间线,可以看到几乎每隔一两个月各家厂商就会有一次小的更新。我加粗标注了其中一些我用过的模型,美国的闭源模型都各领风骚,而国内的开源模型则是断档式领先:DeepSeek不用说引领了开源reasoning model的热潮,Qwen3则成为学术界训练RL最好的选择。大部分这些model在各种benchmark的榜单都已经打爆了,所以单纯看榜单的score已经没有太大意义。
而今年很大的进展还是在多模态方面,年初回国的时候体验了一下豆包,发现语音识别立即响应已经非常丝滑,可以看出字节在这方面做了非常多的优化才能支撑这么多人的实时(几乎零延时)对话,而且还有很多额外的功能如角色扮演仿声等等,而当时OpenAI的语音模型工程落地还远没有做得这么完善。其次是图片视频生成,去年还觉得这些LLM要实现精细控制非常难,但今年GPT-4o生图已经能够实现非常完美的风格迁移,掀起了吉卜力热潮;然后是NanoBanana可以用文字描述实现非常精准的修图,Gemini的视频生成更是让一众视频剪辑者饭碗不保。
另外一个大的趋势是agent。人类日常的很多任务也是通过文字描述的,所以用文字描述动作这件事情属于从generative AI非常自然的拓展。最开始的时候对agent抱有偏见,觉得agent只是prompt engineering,关键在于system prompt怎么写;但随着这一年的发展,发现agent其实更加关键的是context engineering,在有限的context window下怎么合理压缩上下文管理memory并调用合适的工具3,这件事情是最终实现落地很重要的一个部分,其实并没有想象中那么trivial。现在做得比较好的agent startup像Cursor和Manus其实都做了大量的的工作才将产品打磨得这么丝滑,后者因为Meta的收购再一次被推到风口浪尖。
而Cursor其实我也是今年才开始使用,今年年初Cursor的cofounder第一次找我的时候我还不以为然。我用了这么多年VSCode觉得coding agent并不会改变编程本质的东西,而在当时VSCode+Copilot已经满足我日常的代码需求,我也不是非常comfortable让agent去大量修改我的文件。而且Cursor不是一个插件而是一个新的IDE,我不太确定彻底更换一个IDE值不值得。但我还是本着对新事物的探索精神,第一次下了Cursor。经过一番体验之后不得不说,他们的用户体验相比起copilot的集成实在做得太好了,基于VSCode的架构,所有VSCode的功能Cursor也都能够使用。那也是我第一次真正用Cursor写代码,一月份用的还是Claude 3.5,觉得Tab键非常神奇,不仅能够预测下一段代码是什么,而且还能够预测需要跳转到什么位置,但那时的基础模型还没有这么强,所以还不至于特别惊艳。等到3,4月份Claude 3.7和Gemini 2.5 Pro出来之后,Cursor的agent模式直接起飞,可以自动对整个repo的代码进行检索,也能够自己写test修bug,这促使我开启了一年的订购模式。随着下半年模型能力的日渐增强,我也逐渐放权在很多任务下完全采用vibe coding。
上半年因为DeepSeek的搅局,硅谷的各大厂商都变得更加严阵以待。所有人都在冲刺,像朝着某个看不见的终局狂奔,颇有些后现代的荒诞感。

而Meta到处挖人更加让今年LLM的竞争进入到非常白热化的阶段,无论是薪资或者是各种公司的估值都已经到一个非常离谱的地步。在LLM时代仿佛钱都不是钱了,天价薪酬满天飞;很多startup的融资已经看不懂了,一下子估值就窜到几十B美金,只要跟LLM沾点边就能起飞。我们MICRO的paper让某芯片公司一下股价暴涨200%,只因其宣称他们的芯片可以达到跟NVIDIA GPU一样的性能。
人们说着AI泡沫,但每个人都知道不能在这波浪潮中掉队,大家都很FOMO,大家都很焦虑。军备竞赛持续加剧,导致所有人都很卷,弄得大家都很累。硅谷不断上演造富神话,但人们只不过是加速财富积累的过程。原来需要多人协作的项目,现在全堆到一个人身上了,问题是目前AI真的能够起到几倍人力效率的提升吗?这个过程是否可以持续现在还是个未知数。
人类巧思与机械爆算
The bitter lesson is based on the historical observations that 1) AI researchers have often tried to build knowledge into their agents, 2) this always helps in the short term, and is personally satisfying to the researcher, but 3) in the long run it plateaus and even inhibits further progress, and 4) breakthrough progress eventually arrives by an opposing approach based on scaling computation by search and learning. The eventual success is tinged with bitterness, and often incompletely digested, because it is success over a favored, human-centric approach.
正好今年Rich Sutton拿了图灵奖,他的Bitter Lesson成为了不随时代变化的信条,而且可以明显看到他的论断正在影响越来越多的领域。对于系统方向也是的,我们有太多的人工实现的trick(aka heuristic),但这些在LLM时代很快就会被淘汰。我们在年初参加ASPLOS contest的时候就发现顶尖的LLM表现已经能够做得比我们学校最好的本科生手写程序实现的性能要好了。
也是这次比赛用LLM的经历促使我们提出了HeuriGym的benchmark,希望用LLM解决我们实际关心的一些系统工程和科学领域里的组合优化问题,看看现在LLM的能力到底去到哪了。这篇工作我日后还会再聊到,但结论是虽然目前的LLM还没有办法完美解决现有的这些NP-hard问题,但是已经可以达到专家60%的水平。我们有充分的理由相信只要不断scale up,LLM生成的program会取代大部分的人工heuristics。
而去年跟NVIDIA做的编译优化的工作经过非常波折的一年,最终通过内部审批终于得以对外发布,upstream到Triton上游并且中了CGO’26,这也会在之后再找时间说。本来今年暑假我应该回NVIDIA实习继续做Blackwell的拓展,但当时觉得虽然我的工作从Hopper拓展到Blackwell可以实现,但是还是沿着原来的路径循规蹈矩,也许不会太有意思。我这个人就是爱折腾,所以决定最后一段实习再换个地方。
当时其实已经到3月份了,我本来已经不抱希望暑假去实习了,但非常机缘巧合Google的一个compiler team突然联系到我说他们能够sponsor我做student researcher。那时他们说的project是用FunSearch4去解LLVM的优化问题,其实跟我主线的工作没有太大关系。但我只是想暑假离开村里,也不在乎还发不发paper了,所以便答应了下来。
后来的事情证明我还是做出了正确的选择,AlphaEvolve(其实就是FunSearch V2)在5月份发布,我也非常幸运地成为为数不多能够直接使用AlphaEvolve的实习生。
One thing that should be learned from the bitter lesson is the great power of general purpose methods, of methods that continue to scale with increased computation even as the available computation becomes very great. The two methods that seem to scale arbitrarily in this way are search and learning.
AlphaEvolve恰恰是将search(evolutionary search)和learning(LLM)这两种范式结合,从而实现足够的通用性,在不同的科学和工程问题上都能取得非常好的效果。AlphaEvolve在外部跟陶哲轩等数学家合作实现了大量有意思的数学突破,在Google内部也逐渐被很多团队重视并推广。
我们的project正是利用AlphaEvolve去写compiler pass,最开始只是在LLVM的一些简单的问题上尝试,几乎是effortlessly用Gemini-2.5-Pro就已经能够在特定的数据集下实现比现有heuristic更优的解法,这大概只花了我一周的时间去实现,包括我的cohost在内也对产出这个结果的速度非常震惊。有了第一次成功的尝试,我们决定用AlphaEvolve解决更复杂程序性能优化的问题,当然不出所料Gemini-2.5-Pro并没有办法直接提出更好的解决方案。经过几个月时间,我们做了大量的prompt engineering甚至重新实现了新的框架,始终没有办法突破瓶颈。
而最神奇的是Gemini-3出来之后,我们把AlphaEvolve的base model换成了Gemini-3-Pro,不到一天时间性能瓶颈就被突破了5。这其实验证了新时代的摩尔定律:我们只用干等着新的LLM出来,之前的问题就能迎刃而解。这段实习也更加让我坚信:NVIDIA的工作是过去,而Google才是未来。在现在LLM时代,我相信很多系统工作也能够被LLM解决6。NVIDIA这种靠堆人纯人工手写pass手写kernel的模式并不可持续,我们应该用更加聪明的模式实现这些系统的优化。Google今年将Gemini大范围推广,成功打了场漂亮的逆袭战,股价疯涨再到成功逆袭成为继英伟达之后市值第二的公司。
学术体系崩塌
工业界的工作固然有趣,相比较之下学术界已经逐渐走向崩塌。这个感受在2024年可能还没有这么强烈,2024年底还想着申请教职,但当时还是低估了LLM的发展对学术界的影响。
一方面是很少有人再去认真写paper打磨一个故事了,古早年代我们还会逐句逐字推敲措辞修改语法,现在基本有个大致的描述就可以丢给LLM去完成完整的叙述了。写作基本变成流水线上的工作,味同嚼蜡。不仅仅是写作,甚至很多paper的idea都可以由AI提,实验实现也可以AI做,很多事情就变得非常工程。在LLM出来之前世界一片祥和,但LLM出来之后一切都变得不那么漂亮了,大家都得跟着一起卷。久而久之劣币驱逐良币,long-term的高质量研究也越来越少。
从投稿角度,越来越多的投稿量,导致审稿人严重不足,进而引入更多的不合格的审稿人。今年我投了几次稿都没有特别好的审稿经历。NeurIPS经历了非常迷惑的全正分拒稿,AC完全没有读rebuttal而直接summarize了之前的问题直接拒稿;而ICLR变成了I Can Locate Reviewer大会,所有reviewer都被开盒,直接进入威慑纪元。现在就算是系统会议也不能幸免,本来系统会议的审稿人应该是最qualified的,至少都会招公司正式的研究员和教授,但是今年因为投稿量激增,又招了很多不合格的审稿人,ASPLOS第一轮每篇paper只有两个审稿人。今年审我们paper的两个reviewer都几乎没有阅读我们全文就给了评价,一收一拒就导致了desk reject,这属于我这么多年来最为糟糕的投稿体验。
从写作跑实验rebuttal再到camera-ready和presentation,现在写paper的overhead太大了,基本上这一套下来大半年时间就过去了,这篇paper也丧失了时效性。因此现在很多paper都直接挂arxiv了,中不中其实没有太大关系了(但对于在读的PhD来说为了毕业还是得中)。
不仅仅是paper的问题,现在学术界也没有funding,企业基本不再怎么资助学校,而把钱大量砸入AI军备竞赛中。Trump的上台又进一步将学术界的funding大幅缩减,搞得民不聊生。能够申的funding越来越少,竞争的人却越来越多,今年可能帮老板写了不下十个grant proposal,整个系统陷入了恶性循环。
Pain is inevitable, suffering is optional
大概基于上述的一些原因,如今的学术界已不再是从前的理想国。这种写作投稿拒稿的suffering被放大,为了中paper所做的很多effort现在变得没有什么意义。这是一个systematic的问题,但大家目前都没有想到合适的方案去解决。
AI时代的存在主义
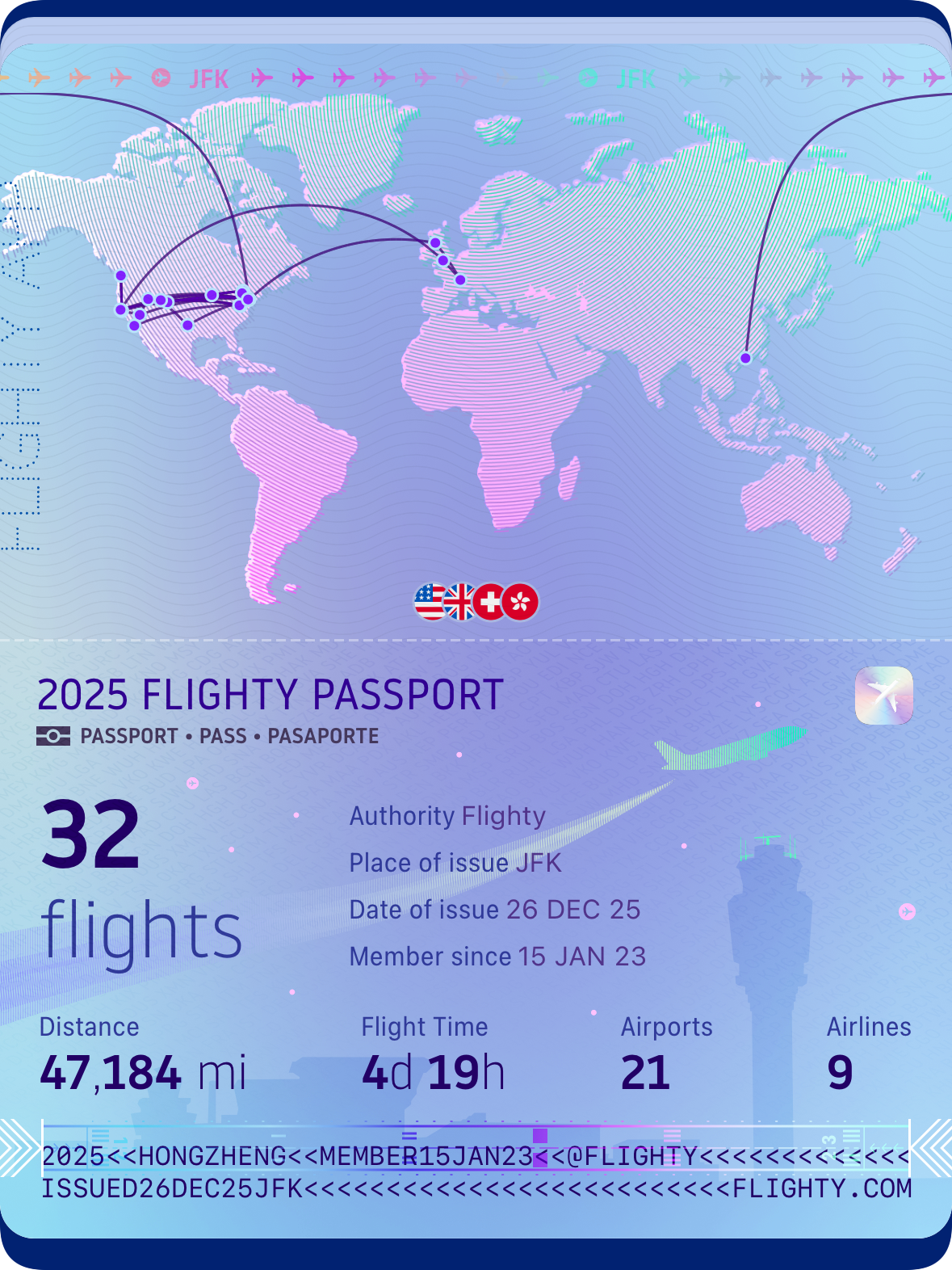
本来想着2024已经是漂泊的一年,但没想到2025坐的飞机竟然比2024还多,大部分都是开会和滑雪的出行。今年因为还在美签有效期内,所以得以去欧洲走了一趟,第一次踏入英国的土地去拜访了一个在爱丁堡的老朋友,然后又去伦敦玩了几天感受了一把回国的城市生活。北美大部分时间在东西岸来回飞,不过加起来也去了十几个城市;今年比较惊喜的是SLC和DC,都是第一次去就爱上的城市,也许是因为这两座城市都有湖,再加上我去的时候天气都很好,所以有特别的好感。
除了出行今年基本其他时间都是在连轴转,基本隔两周就有一个presentation。上半年上课赶NeurIPS和ASPLOS,然后5月份就急急忙忙去纽约给了两个talk又去英国和瑞士给了两个talk,从伦敦直飞三番还没倒过来时差第二天就实习入职了。下半年最多时候同时推进5个project,本来应该能够错开,但有DDL的时候实在没有办法。最后一个学期还在上课做作业,接着做Google的part-time实习项目,应对几篇paper的rebuttal,还得准备full-time的面试。那段时间精神高度紧张,焦虑感濒临极限。一度还在考虑要不要接一个startup的offer提前离校,很大程度上是我老板劝说我不要on leave,然后才没有提前离开。现在回想起来确实没有必要把自己推到悬崖峭壁,健康与平衡才是长久之策。
其实现在很多公司都在飞奔,但并没有想清楚真正的AGI实现之后对未来社会的影响到底会是怎么样。虽然对Anthropic这家公司没有特别的好感,但还是看完了Dario的采访podcast6,他对当前的AI现状判断以及未来可能发生的社会动荡还是看得比较清楚的。他所说的安全问题也并非纸上谈兵,不是“狼来了”的故事,而是对人类社会真真正正的变革/威胁。
是不是实现AGI真的重要吗,又或者说最终AI的形态是不是LLM真的重要吗?对于我来说AGI并不重要,就像AlphaEvolve所展示的,当下的AI已经可以做很多事情,已经足够改变世界了。

非常有意思的是,我们现在越是推动这波浪潮发展,最终越有可能导致我们都失业。加速这个过程某种意义上是加速我们失业的进程,我仿佛从中看到了“后现代”的光景。在这个加速的时代,我很感谢Google在这波浪潮中还能够给我们提供这么舒适的环境做着有意思的研究。在Google实习的这几个月是我这几段实习中最开心的几个月。在三番和Seattle的office都看到了绝美海景;每天在不同的campus蹭吃蹭喝,探索楼里的隐藏房间;报了钢琴课,没有了小时候家长的逼迫,现在反而学得更加尽兴。
所以在现在这个AI可以写作画画下棋写代码的年代,在“后现代”即将来临之际,作为人类究竟还剩些什么呢?
“It’s all about the context.”
AI在与人的交互中学到了pattern变得更强,人类其实也在一次次跟AI的对话中完善自我。但其实从来都不是我们自己定义了自己,而是那些“非我”的东西定义了我7。
那为什么还要坚持写作还要坚持coding呢?或许我们都是这个时代最为古老的手工艺人,还在坚守着自己内心的那份纯净。
The journey is the reward.
那些痛苦的过程恰恰是通往上层的必经之路,我们获得的成长都是一步一个脚印积累起来的。保持好奇心,勿忘来时路,这才是属于我们独一无二的旅程。
-
Nvidia briefly touched $4 trillion market cap for first time, https://www.cnbc.com/2025/07/09/nvidia-4-trillion.html ↩
-
大模型季报跨年对谈:和广密预言一场AI War、两大联盟和第三个范式Online Learning:https://www.bestblogs.dev/en/podcast/3ecd3c2 ↩
-
Manus 决定出售前最后的访谈:啊,这奇幻的 2025 年漂流啊…:https://www.bestblogs.dev/en/podcast/1c6b75e ↩
-
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M. Pawan Kumar, Emilien Dupont, Francisco J. R. Ruiz, Jordan S. Ellenberg, Pengming Wang, Omar Fawzi, Pushmeet Kohli, Alhussein Fawzi, “Mathematical discoveries from program search with large language models”, Nature, 2024. ↩
-
这件事情听上去简单,我们还是做了大量infra的support让实验可以scale起来,希望过段时间可以把我们这篇paper挂出来。 ↩
-
Audrey Cheng, Shu Liu, Melissa Pan, Zhifei Li, Bowen Wang, Alex Krentsel, Tian Xia, Mert Cemri, Jongseok Park, Shuo Yang, Jeff Chen, Lakshya Agrawal, Aditya Desai, Jiarong Xing, Koushik Sen, Matei Zaharia, Ion Stoica, “Barbarians at the Gate: How AI is Upending Systems Research”, https://arxiv.org/abs/2510.06189. ↩ ↩2
-
Dario Amodei: Anthropic CEO on Claude, AGI & the Future of AI & Humanity, Lex Fridman Podcast #452, https://www.youtube.com/watch?v=ugvHCXCOmm4 ↩