Hongzheng Chen Blog
从一到万的屠龙魔法书(1):[CGO'26] 面向Hopper和Blackwell GPU的自动化warp specialization
Jan 15th, 2026 0新年新气象,趁在毕业前开一个新的专栏,集中宣传一下我们最近的一些工作。
距离上次发帖子过去快两年,世界发生了翻天覆地的变化。现在人们总说 scaling law,但 scaling 并不是简单地堆叠参数和算力,它本质上是一个贯穿算法和软硬件的系统工程。随着硬件的高速更新迭代,我们有了更多的可用的算力,但是硬件彩票(hardware lottery)并没有减轻反而变得更加严重:如果一个算法/模型没有办法快速在规模适当的硬件上得到验证,再精妙 idea 也可能因实现难度从中夭折。如何方便用户更快地在不同的异构硬件上实现算法并释放硬件最大潜能,是我在 PhD 期间一直思考的核心课题。
从零到一的算法创新固然重要,但“从一到一万”的 scaling 也并非坦途。“屠龙”和“魔法”来自编译器和编程语言两个领域我非常喜欢的入门教科书的封面1,所以就有了这个专栏的名字,希望探讨在异构硬件平台上的实现生产力 scaling 的尝试,从而让“硬件彩票”不再是制约创新的瓶颈。
下面新年第一弹就送给我在 NVIDIA 实习的项目 Tawa,论文已经中稿 CGO’26。
- TLDR: 我们在 Triton 上实现了自动 warp specialization,在 H100 上达到手写 CUDA FlashAttention-3 95% 以上的性能。提出的 MLIR dialect(NVWS)和编译 pass 都已并入 OpenAI Triton 上游,成为 Triton 到 Hopper 和 Blackwell GPU 优化的必经之路。
- 论文链接:https://arxiv.org/abs/2510.14719
- 代码链接:https://github.com/triton-lang/triton/tree/aref_auto_ws
- 首个PR链接:https://github.com/triton-lang/triton/pull/6288
- 原文链接:https://chhzh123.github.io/blogs/2026-01-15-tawa/
Hongzheng Chen, Bin Fan, Alexander Collins, Bastian Hagedorn, Evghenii Gaburov, Masahiro Masuda, Matthew Brookhart, Chris Sullivan, Jason Knight, Zhiru Zhang, Vinod Grover, “Tawa: Automatic Warp Specialization for Modern GPUs with Asynchronous References”, ACM/IEEE International Symposium on Code Generation and Optimization (CGO), 2026.
Hopper 架构
Hopper 其实是 NVIDIA GPU 从 Ampere 架构之后一个非常大的改变,最主要的就是把 memory loading 单独拎出来做成一个硬件单元,也即 Tensor Memory Accelerator(TMA)。这最直接的影响是 memory access 变成硬件控制的异步单元,更加容易跟 Tensor Core 的计算模块(WGMMA)给 overlap 起来。可以看到从 Hopper 这一代架构开始,GPU已经越来越向 dataflow DSA 的方向发展,Blackwell 和 Rubin 都是进一步增强了这种趋势(从 NVIDIA 最近收编 Groq 也可以看出他们之后想要怎么发展,这我后面会另外开一篇文章进行讨论)。
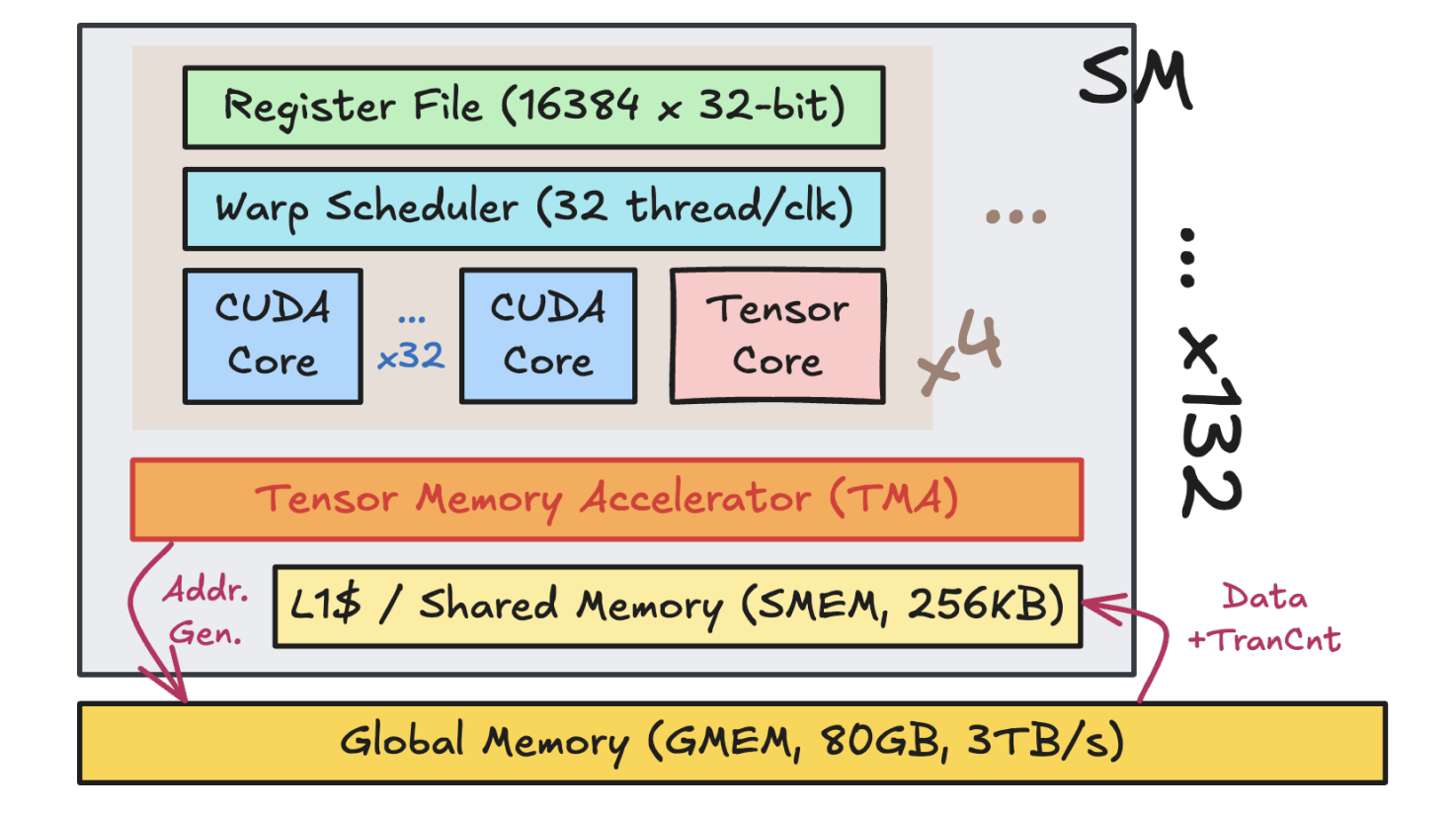
但这个架构上的改动基本上是要革了 CUDA 的命,因为之前无论 CUDA 还好或者 Triton 也好其实都是遵循 SIMT 的编程模式,假设每个 thread 每个 warp 都是干同样的事情,但是现在异步 dataflow 的出现彻底打破了这种模式,NVIDIA 官方会更加推崇 warp specialization 的模式,即每个 warp 干不同的事情,从而更加实现硬件层面上的调度。但这样做直接的后果是原本就已经很复杂的 GPU 编程雪上加霜,可以看 @郑思泽 大佬的文章”在Hopper GPU上实现CuBLAS 90%性能的GEMM“,就知道要在 Hopper 上从头写一个高性能的GEMM有多大难度。事实上我在入职 NVIDIA 的第一个月就对着一千多行的 CUDA GEMM 实现逐行分析,用一个月时间查了大量文档才明白其中的道理。
总结下来有三个方面的难点:
- 不同 warp 之间的计算划分:这也是前面提到的,因为异步 dataflow 的特性,在 Hopper 上实现高性能的算子就必须用 if-else 分支对计算访存进行显式划分。
- 低级原语的使用:在 Hopper 上其实很多硬件指令已经没有在CUDA中暴露了,所以导致很多 mbarrier 的操作都得直接调用 PTX,弄得整个程序非常难看;而 TMA descriptor 同样是一个非常难用的硬件指令,需要准备大量的 metadata,用起来非常麻烦。
- 资源调度和流水线的管理:包括每个 warp 需要 register,需要开多大的 buffer 去实现硬件 pipeline,以及像一些更复杂的算子还涉及到实现软件流水,这些手写难度都非常高。
实现一个 GEMM 已经难度这么大了,更何况是其他算子,所以我们这个项目的初衷就是想让 Triton 在这些新架构的 GPU 上能够更加自动地生成这些高性能算子。
异步引用 (Aref)
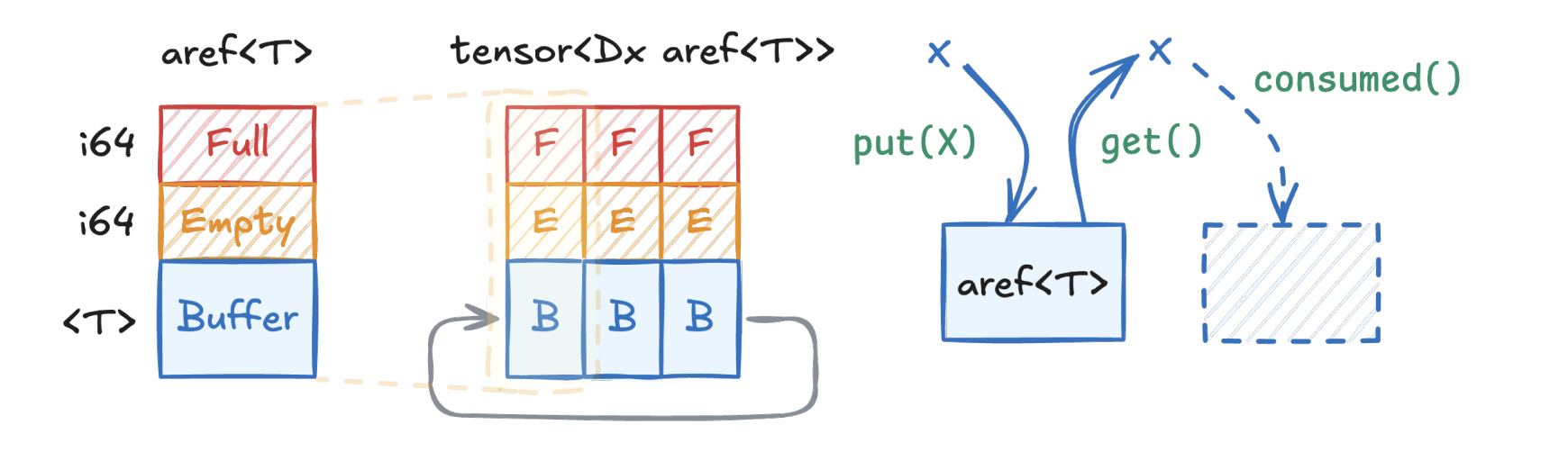
回到 Hopper 的架构本身,它本质上是让程序的执行模式变得 dataflow,而不再是单一的 SIMT,而 dataflow的问题在于怎么做通信,或者说 data movement,所以我们很自然地会想到将数据包裹在一个数据结构里面进行传输,所以就有了我们异步引用(asynchronous references,aref)的抽象。这个抽象如下图所示,有三个部分,一个是 buffer,还有两个指示 Full 和 Empty 的 flag(实际上是 mbarrier)。这也是因为GPU上没有FIFO的单元,所以需要通过 mbarrier 来显示控制同步。每个 aref 会指代一个数据单元,将多个数据单元拼起来就可以实现一个循环队列(circular buffer),这对后面复用 GPU memory 有着重要的作用。
而跟 aref 绑定的主要有三个 operation:.put()用来写入 data,.get()用来读出data,还有.consumed()用来指示 data 已经用完了。由于 aref 是一个抽象的数据结构,所以它可以接入不同的基本数据类型,从而不同大小 tensor的存储,以及实现 mbarrier 的共用。aref 也是我们这篇论文标题 Tawa(Task-Aware Warp Specialization)的来源。
图划分
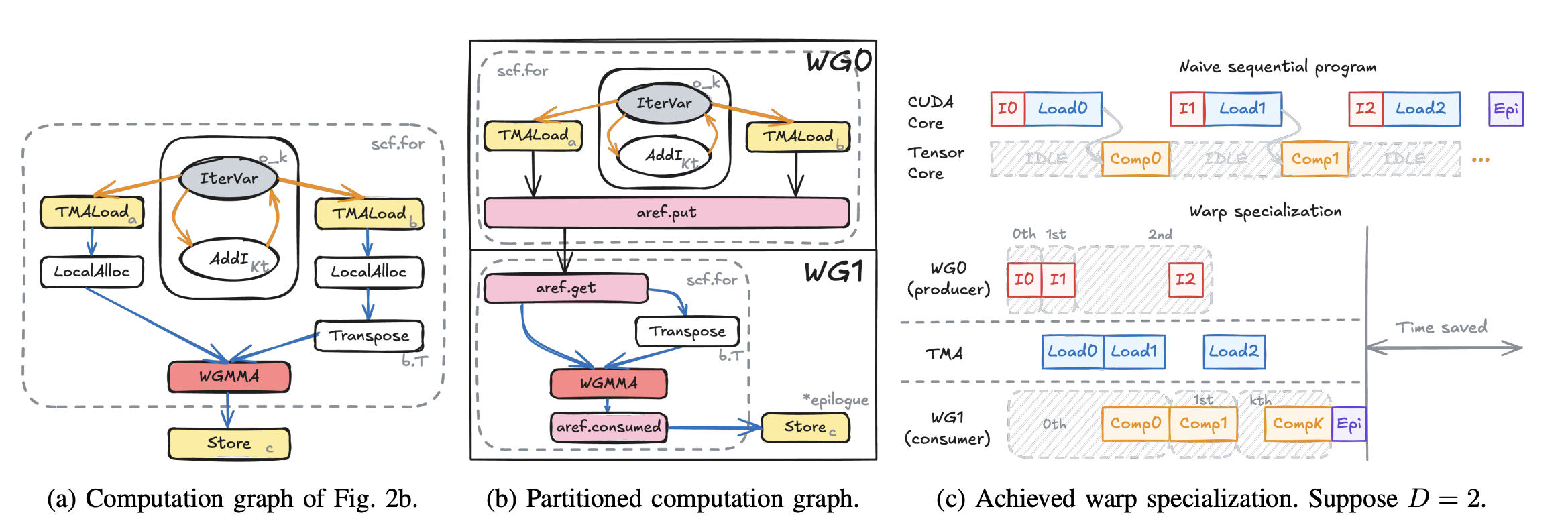
有了 aref 的抽象之后,我们就可以开始分析输入程序,尝试将其划分成不同的角色并分配到不同的 warp group(WG)上面。在 Hopper 由于只有 producer 和 consumer 两种角色,所以划分的逻辑非常简单,只需要将 TMA load 放在一个WG 里面,计算 WGMMA 放在另外一个 WG 里面即可。简单来讲就是从图的 sink node 开始反向遍历,并且标记哪些指令是访存操作,哪些是计算操作,这样前者可以被分到 load WG,后者被分到 compute WG。同时需要注意将地址计算相关的也都丢到load WG 里,而最后的 epilogue 丢到 compute WG 里,这样就能实现完整的划分。

比如上面的这个 Triton 程序进行划分之后就会变成下图的样子,我们需要在 load WG 里面将 data 都以aref.put的形式放到buffer 里,在 compute WG 则是将 data 都以aref.get的形式从 buffer 里取出来,并且在最后 WGMMA 用完之后标记aref.consumed来通知 load WG 可以重新 put 新的数据了。最终生成的 MLIR 可以见上面右图的代码,可以看到整个程序还是非常简洁的,也没有更底层的硬件指令出现。
流水线
除了 warp specialization 之外,我们还可以做不同粒度的流水并行,包括细粒度的 MMA 流水和粗粒度的软件流水。
细粒度的 MMA 流水如下图所示,核心还是要将能够并行计算的单元都给充分利用起来,这在 FlashAttention的实现里也是非常重要的部分。WGMMA 的并行主要是在地址计算和实际的 Tensor Core 的计算上面,所以我们可以一次 issue 多个CUDA Core 的地址计算,然后再调用 WGMMA,基本可以实现在算下一个 WGMMA 时前面一个 WGMMA 的地址计算已经完成了,但这个的效果在大规模的 GEMM 里面不会特别明显,在我们论文里的消融实验也可以看到这一点。
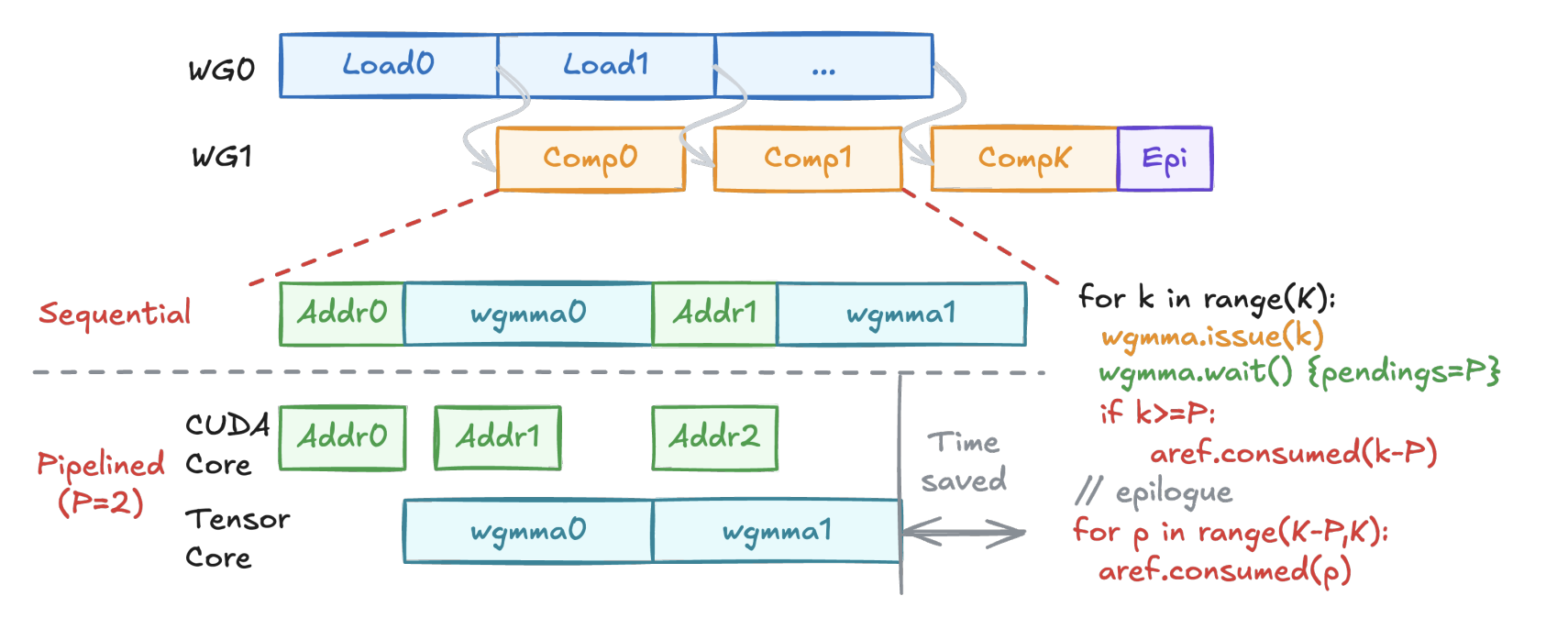
粗粒度的流水则是编译器里常用的软件流水,这里我们主要对 compute WG 里的计算进一步进行流水,可以参考FlashAttention-3 paper 里 Figure 2 的2-stage WGMMA-softmax pipelining 的实现。我们的工作则主要是将这个流程自动化,自动找出可以被 CUDA Core 和 Tensor Core 分别计算的指令,然后进行调度,从而实现不同硬件单元最大程度的 overlapping。
额外的优化
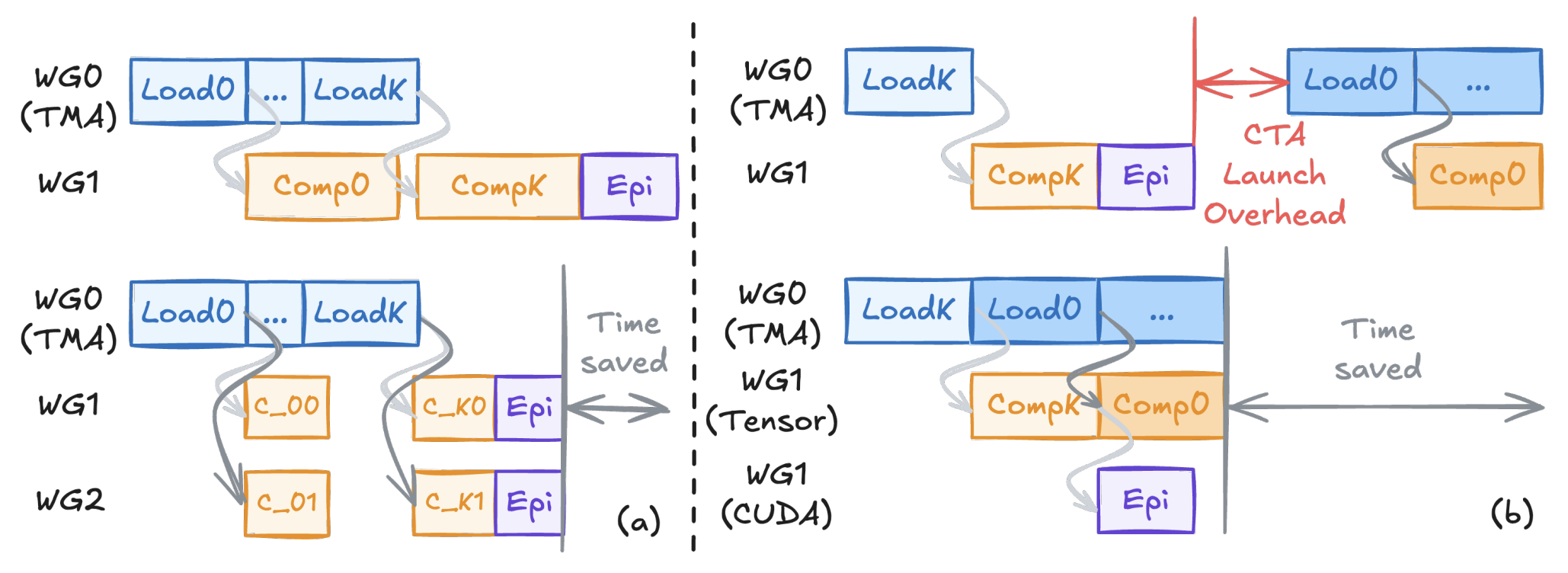
其他还有一些额外的优化可以进一步提升 GEMM 的性能,一个是合作(cooperative)WG,如上图(a)所示,采用多个WG去算同个tile,这可以减轻寄存器压力同时使得 tile size增大,从而实现最终性能的提升;另一个则是 persistent kernel,如上图(b)所示,有多少个 CTA 就启动多少个 kernel,用一个 for loop 去主动取新的 tile,让这些 kernel 常驻在 SM 里,从而减少 CTA 启动的开销。
实验结果
如开头所说,我们将 aref 的抽象做成了一个 Triton dialect(参见NVWS),并将图划分和 lowering的编译流程做成了一个 Triton 的 pass,这些都已经并入上游 main 可以使用。注意我们自动 warp specialization 与 Meta 提出的方案现在是并行的,main 里面更多做的是 Blackwell 的支持,Hopper 的支持在aref_auto_ws分支里面。
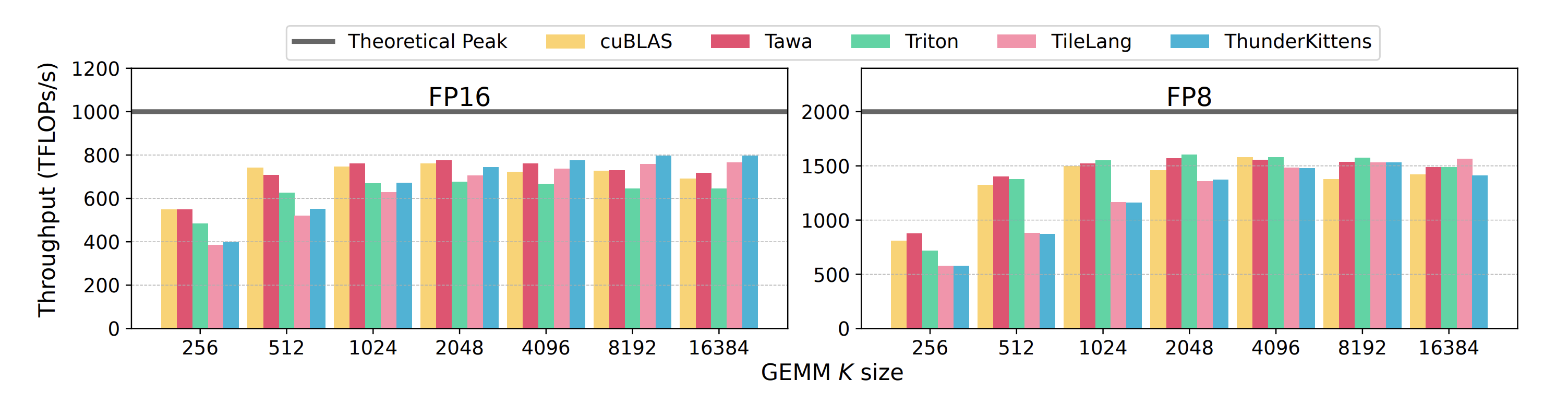
在这篇论文里我们主要做了 H100 的实验,并与 cuBLAS、Triton 原本 sw pipelining的版本、ThunderKittens和TileLang 进行比较,具体实验配置可以参见论文。对于 GEMM 我们测了 M=N=8192 的 size,从下面的结果可以看出 FP16 上我们基本可以跟cuBLAS的效果持平,FP8则有大约6%的提升。对于原生 Triton,我们在 FP16 上的优势会更加明显,FP8 在一些 size 下会比它慢,目前不知道具体原因。TK 和 TileLang 经过一整年的发展,现在其实相对来讲都挺成熟了,在 GEMM 上面都可以达到不错的效果,但在小的 K size 下跟 Triton 的差异还是比较大。
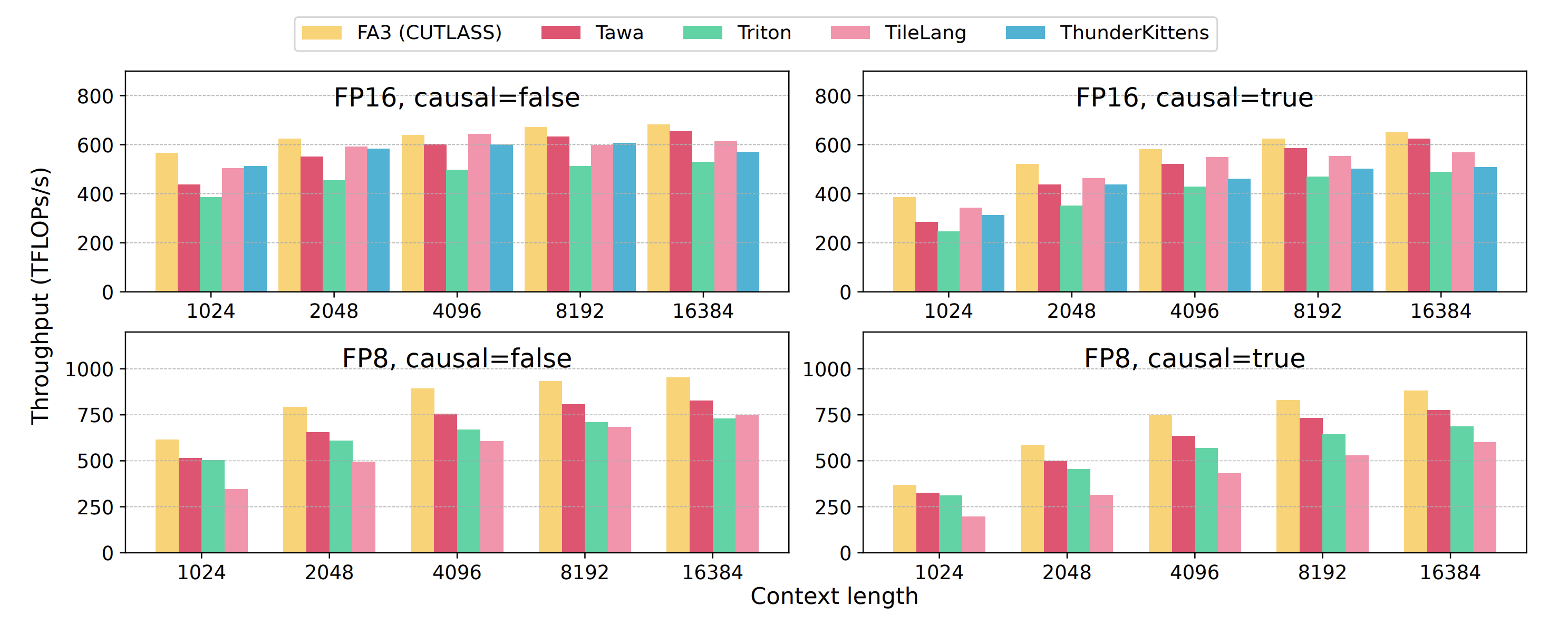
对于 FlashAttention,我们则主要测了 FP16 和 FP8、causal 和不 causal 四组实验。可以看到开了 warp specialization 之后,比原来 Triton的 FlashAttention-2 版本还是有了20%左右的提升,同时达到96%手写FlashAttention-3 的性能。TileLang 在 FP16 上的性能有些甚至达到了 FA3 的效果,但在 FP8 上的性能跟还是跟Triton 有近40%的差距。ThunderKittens则属于学术界的研究项目,显然没有投入过多精力进行维护,在 FP8 实验上出现了不少 bug。
其他的消融实验结果可以见论文详情。
讨论与未来展望
这篇论文主要做的是 Hopper 上的 support,但还有很多东西值得探索,包括对 ping-pong kernel 和 multicast的支持,这些都涉及到怎么更好地描述通信。
另外一方面则是对 Blackwell 的支持,Blackwell 在 Hopper 基础上引入了 Tensor Memory(tmem),进一步往dataflow 的方向发展,硬件上也能够支持更多的 WG,所以怎么去做调度划分就变成更加关键的问题。从FlashAttention-4的 blog 可以看到在Blackwell 上面划分出了五种不同的 WG。aref 目前在 Blackwell 上的实现也遵循类似的语义划分,通过给不同类型的IR 指令打标签,从而实现启发性调度,具体的实现细节可以在 Triton 上游搜索 aref相关的PR,目前 partitioner 还未并入 main中,所以性能还没有达到最优。
Blackwell 的 support 也是 OpenAI 和 NVIDIA 一直在合作推进的。OpenAI 觉得 Triton 基本已经做到头了,所以选择让用户提供更多的hint去进行优化,所以有了Gluon作为更底层的算子描述语言。而 NVIDIA 还是走的更加激进的道路,尝试让用户写更少的东西而将自动优化的部分更多交给编译器来做,更多细节可以看我们论文作者 Chris Sullivan 在 Triton conference 给的 talk:A Performance Engineer’s Guide to NVIDIA Blackwell GPUs in Triton。
我们也很高兴这一年里 Meta TLX和 TileLang也都做了类似的工作,并且都在 performance 和 productivity 上取得了不错的平衡。Blackwell 上的优化目前才刚刚开始,还有更多更有意思的方向值得探索,包括更好的编程模型,更好的划分调度方式等等,可以预见很多以前在 DSA 上用过的优化方式2,在新的 GPU 上也会重新焕发新机。
恰逢国内可以采购 H200 机器,希望这篇工作能够给还在用 Hopper 编程的朋友们带来一些帮助:)
致谢
最后非常感谢我的 mentor Bin 和 manager Vinod 对这个项目的大力支持,感谢 OctoML/NVIDIA 的工程师们把我的代码逐一 upstream,感谢叶老板 @yzh119 在我实习期间循循善诱,感谢磊哥 @LeiWang1999 在 TileLang baseline 上的协助,也要感谢 OAI Triton team 对我们的实现给出意见并合并到上游,最终造福了更多的 LLM 模型开发者。
我们会在2月2号15:10-15:30在CGO’26上进行present,欢迎大家来参加。我因为签证问题没有办法去悉尼,但 NVIDIA 的同事们会参加,也欢迎大家找他们讨论!