Hongzheng Chen Blog
从一到万的屠龙魔法书(3):[ICLR'26] HeuriGym:评测智能体解组合优化--迎接LLM的下半场
Jan 26th, 2026 0做了这么久 MLSys 在最后一年才第一次中 ML 顶会,很高兴这次能联合哈佛和 NVIDIA 的朋友们一起合作做了这个工作。
去年 LLM 在不少榜单上都刷出了接近100%满分的成绩,即便是在“人类最后的考试 HLE”上现在也可以达到40%的水平,但是刷高的榜单却往往在解决实际问题上不如人意,这是姚顺雨在 2nd half 说的 utility 的问题。 这里面很重要的因素在于,世界不是非黑即白非对即错,很多现实问题都是在多维度连续谱上的 tradeoff,之前大部分benchmark 都是在让 LLM 闭卷考试做有标准答案的题目,并不能真正反映LLM是否能够活学活用解决没见过的实际问题。这也是我们为什么提出了 HeuriGym:我们想定义一套 benchmark 既有闭卷考试的客观性,又有大范围的开放式探索空间,而 score-based 的问题是绝佳的评价指标。
在科学和工程领域,很多问题都是 NP-hard 的组合优化,在大规模数据上基本找不到最优解,所以现在大量的工业软件上基本上都是采用 heuristic 解决,而 heuristic 往往需要丰富的人工经验,我们想知道 LLM 在我们最关心的实际任务上,究竟能把算法设计得多好。所以我们找了系统、生物、物流、芯片设计里的9个组合优化问题,让 LLM 以 agentic 的方式去生成这些问题对应的 heuristic 看最终能达到什么水准。
- 论文链接:https://arxiv.org/abs/2506.07972
- 代码链接:https://github.com/cornell-zhang/heurigym
- 排行榜连接:https://cornell-zhang.github.io/heurigym/(最近会更新一些新model的结果)
- 原文链接:https://chhzh123.github.io/blogs/2026-01-26-heurigym/
Hongzheng Chen, Yingheng Wang, Yaohui Cai, Hins Hu, Jiajie Li, Shirley Huang, Chenhui Deng, Rongjian Liang, Shufeng Kong, Haoxing Ren, Samitha Samaranayake, Carla P. Gomes, Zhiru Zhang, “HeuriGym: An Agentic Benchmark for LLM-Crafted Heuristics in Combinatorial Optimization”, International Conference on Learning Representations (ICLR), 2026.
动机
过去两年 LLM 的发展太过迅速,很多评测集都已经被 LLM 刷榜刷到接近满分,但是这些 LLM 的能力在真实任务上却往往不如人意,这很大程度上是目前评测指标跟真实任务之间的 mismatch。现有的LLM评测大致分两种:
- 客观闭卷考(比如 HumanEval):有标准答案,容易刷分,也容易因为训练数据泄露而作弊。题目是静态的,但模型一直在学新数据,很快就能刷到天花板。
- 主观开放式评价(比如 Chatbot Arena):没有固定答案,靠人类或另一个 LLM 来评判好坏。但评判很主观,很多时候就变成生成答案的结构是否符合用户偏好,而不是看是否真正解决问题。
这两种方式都很难衡量 LLM 在需要多步推理、工具使用、算法设计的真实世界任务上的能力。我们更想知道 LLM 是否能够有创新,解决一些不是靠单纯记忆能够解决的问题。而我们之所以看上了组合优化问题也是因为组合优化问题能够系统性地测试这些能力。组合优化问题目标明确,但解空间巨大,没有通吃所有问题的标准算法(这是No Free Lunch定理告诉我们的),而这恰恰是检验 LLM 是否具备创造性问题解决能力的绝佳试金石,所以就有了我们这篇HeuriGym。
HeuriGym:让 LLM 设计启发式算法
HeuriGym 的评测方式非常直观,就是以 agent 的方式模拟一个人类算法工程师的工作流程:
- 接需求:给LLM一个形式化的问题描述,包括问题背景、形式化定义(目标函数、约束条件)和输入输出格式。
- 写代码:LLM需要生成一个完整的、可执行的启发式算法程序(Python 或 C++)。
- 跑程序:在一个沙盒环境里执行代码,用真实的验证器检查方案是否合法,用评估器计算目标函数值。
- 看反馈:把运行结果(成功/失败、错误信息、性能得分)作为反馈,连同几个示例,一起丢回给 LLM。
- 迭代改:LLM 根据反馈改进代码,再进行新一轮的迭代。
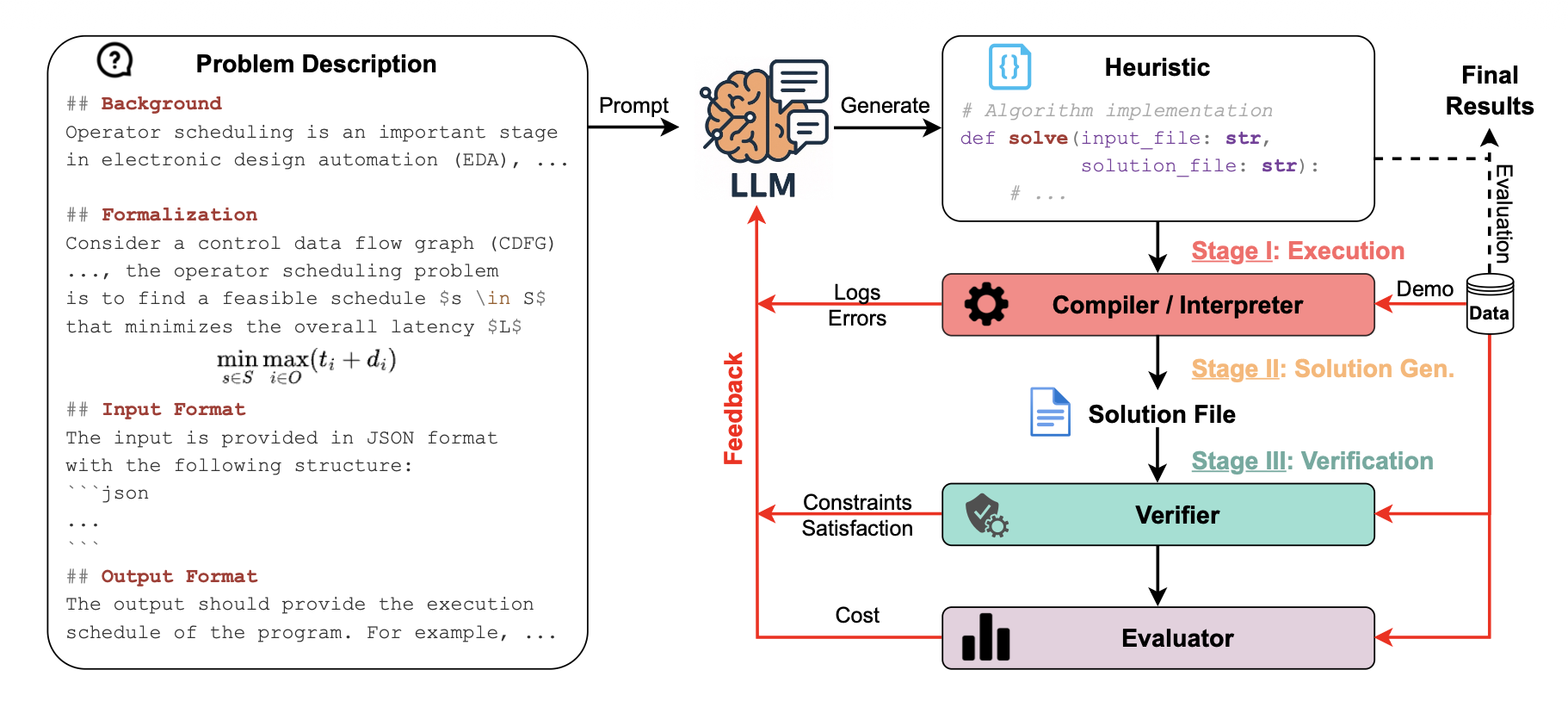
这个过程逼着 LLM 去真正理解问题约束、设计问题相关的数据结构(metaheurisitc在我们这些问题上并不行得通)、调试运行时错误、权衡算法优劣,而不是简单地生成一段看起来合理的程序。
新指标:QYI(质量-通过率指数)
传统评测常用PASS@k,但我们更希望看到 LLM 在多轮迭代中综合解决问题的实力,所以我们提出了solve@i指标,即在一轮迭代中通过的阶段数来细化 LLM 的能力,具体来说三个阶段是
- 第一阶段:程序能否正确编译、导入库、完成基本 IO?
- 第二阶段:程序能否在超时内产生非空输出、且格式正确?
- 第三阶段:输出是否满足所有问题约束?
形式化定义:
\[\texttt{solve}_s@i:=\frac{1}{N}\sum_{n=1}^N\mathbb{1}(\text{pass stage }s\text{ in the first }i\text{-th iteration})\]光看能不能跑通还不够,一个好的启发式算法,既要能产出可行解(Yield),也要解的质量高(Quality)。这里我们先定义两个指标:
- Yield:在测试集上能产出合法解的比例。
- Quality:LLM方案的成本 vs. 专家方案的成本(capped at 1,即最多追平专家水准)。
有了这两个指标我们就可以借鉴 F1 分数,将这两者结合起来:
\[\texttt{QYI}=\frac{(1+\beta^2)\cdot \texttt{Quality}\cdot\texttt{Yield}}{(\beta^2\cdot\texttt{Quality}) + \texttt{Yield}}\]QYI=1 表示达到专家水平,QYI=0 表示完全失败。这个指标比单纯看通过率(pass@k)更能反映 LLM 在多轮迭代中综合解决问题的实力。
问题集构造
我们故意避开了像 TSP、SAT 这类教科书级别的经典问题,因为它们在公开语料中出现太频繁,LLM 可能已经记住了常见解法,而在 HeuriGym 中我们设立了几个规则来筛选问题:
- 低曝光率:通过 Google Scholar 搜索,只选取最高引用论文少于1000次(截至2025年5月)的问题。这确保了问题有明确的学术定义,但又没有充分被引入进 LLM 的训练数据中。
- 目标清晰:每个问题都有能用自然语言和数学公式(用 LaTeX 表达)清晰定义的目标和约束,没有歧义。
- 解空间巨大:单个问题的搜索空间通常远超传统评测(例如 auto-sharding 的搜索空间达到了 $10^{65,000}$ 的量级),迫使 LLM 进行创造性探索,而非简单模式匹配。
- 实例可扩展:每个问题都提供小规模演示集(约5个实例,用于迭代反馈)和大规模评估集(几十个实例,用于最终测试),规模相差至少一个数量级。

评测结果
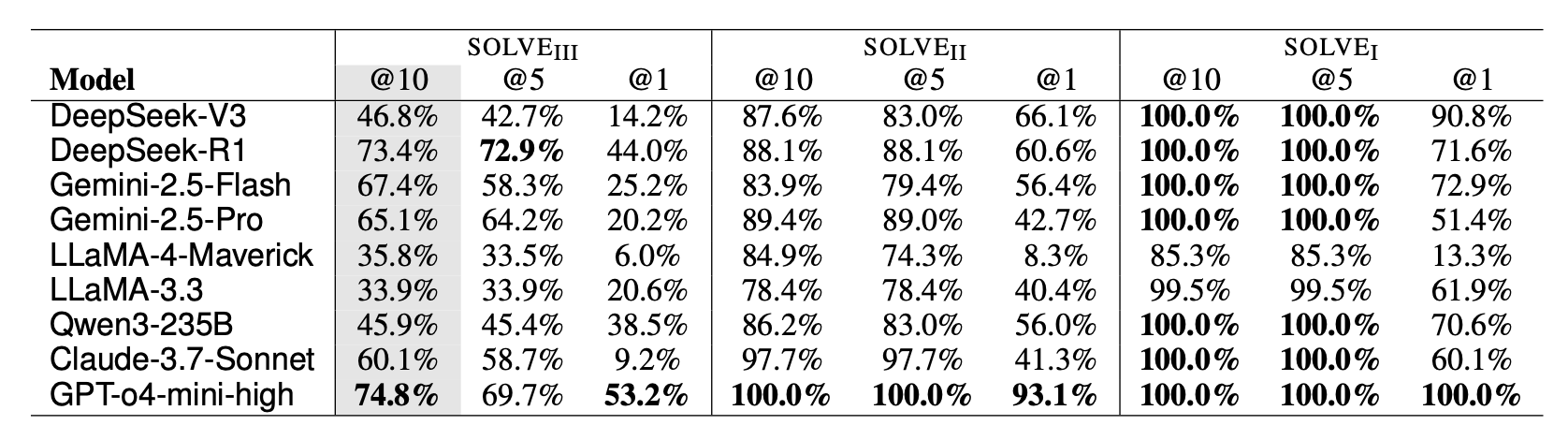
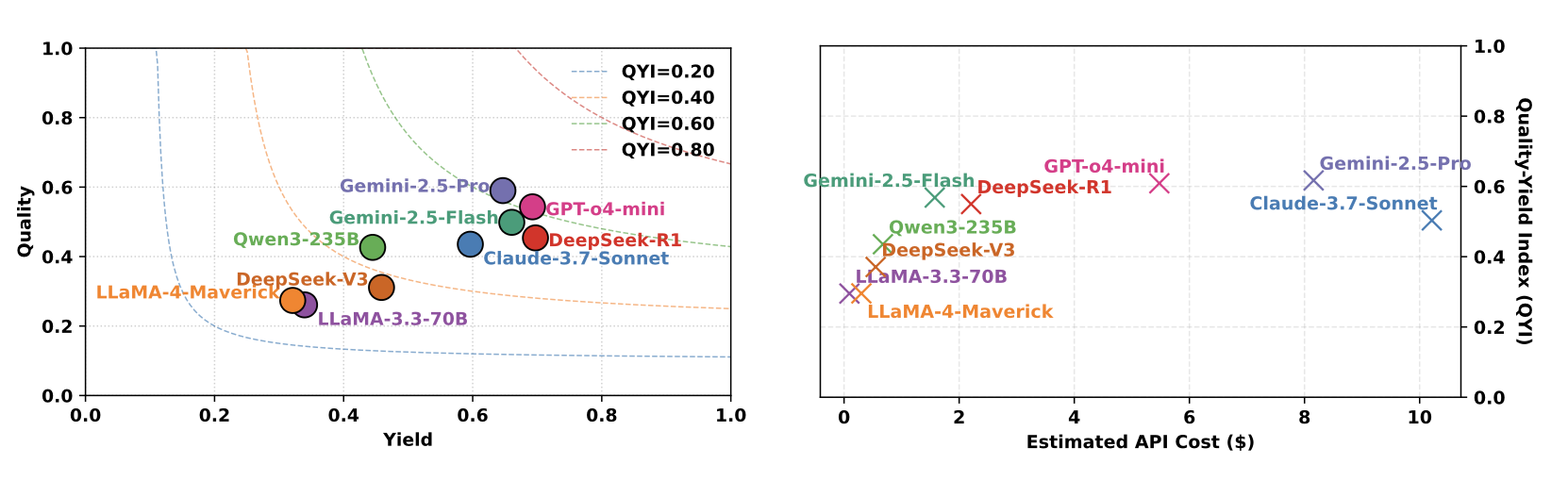
我们评估2024末-2025年初最强的9个模型(GPT-4o-mini、Claude-3.7、Gemini-2.5-Pro、DeepSeek-R1等),具体的结果可以参见论文的讨论。我们还在做新一批模型的测试,后续也会更新到排行榜上。总结来说:
- 整体表现:即使给10轮迭代机会,最好的模型(Gemini-2.5-Pro)QYI也只有0.62,相当于专家水平的六成。大部分模型在0.3-0.6之间徘徊。
- 单次成功率低:只看第一轮(solve@1),除了GPT-4o-mini(53.2%),其他模型大多在20%-40%之间,说明一次性生成正确算法非常难。
- 迭代有帮助但有限:增加迭代轮数普遍能提升表现,说明反馈学习有效。但提升幅度有限,离专家水平仍有显著差距。
- 错误五花八门:包括幻觉 API(调用不存在的库)、算法逻辑错误、误解约束、超时等等。模型在长上下文下的实际代码推理依然薄弱。
讨论与展望
HeuriGym 不仅仅是一个新基准,更是一种评测范式的转变:从静态问答转向动态、交互、需要真实执行的智能体任务。它暴露了当前 LLM 在工具使用、规划、调试和适应式推理上的短板。未来我们也希望能够在下面几个方面继续探索:
- 更丰富的反馈机制:可以引入自验证、进化算法、束搜索等,让迭代改进更高效。
- 从代理指标到真实部署:目前的评估还是计算成本,真实场景(如芯片设计)还需要后端物理验证,整个实验周期更长,如何缩小这个差距是关键。
- 社区共建:我们只放了9个问题,希望社区一起贡献更多领域、更复杂的问题,让这个基准持续进化。
如果说以前的评测是“知识测验”,那么 HeuriGym 就是“工程能力实战”。它告诉我们,LLM 在解决开放、复杂、需要反复调试的真实优化问题上,还有很长的路要走。
致谢
这篇 paper 可能对我来说更大的意义是能够跟不同方向特别好的朋友们一起合作,感恩 Yingheng 和Yaohui carry了这篇 paper ML 的部分,感谢 Hins 和 Jiajie 收集了不少新的问题,感谢 Shirley 临危受命帮忙写paper跑实验,也感谢 NV 的朋友们提供了非常高质量的代码和数据集。