Hongzheng Chen Blog
从一到万的屠龙魔法书(4):[CGO'26 C4ML] 通向编译器自我进化之路:用AlphaEvolve进化LLVM/XLA
Jan 31st, 2026 0很高兴这次能跟 DeepMind AlphaEvolve team 合作将 AI 里两个经典的范式 search 和 learning 推向更多领域。AlphaEvolve在去年五月发布的时候引起一阵轰动,那时更多还是关注在经典的数学算法问题上;而这次我们则是成功将其大规模应用到工程领域,让狗家的编译器开启自我进化之路。
编译器从计算机诞生的那一刻起就存在了,它将人类编写的高级语言转化为机器能够执行的低级语言,可以说是这个星球上最复杂的软件系统之一。编译器在 Google 属于非常核心的位置,也是 scaling 不可或缺的一环。因为采用 monorepo,所以所有程序都不可避免需要经过编译器优化,哪怕提升一点点效率,对整个集群的影响都是巨大的。
目前用有很多 LLM4Compiler 的工作,大致可以分为两个方向:一个是取代编译器,直接生成 kernel 代码如 CUDA/Triton;另一个则是去生成优化或者调度序列,典型例子如Autocomp,再借用编译器去实现这些优化的变换。因为我们还是针对大规模应用的优化,所以并不可能完全替代编译器,我们更倾向于选择后者保留原有编译器的存在。编译器的好处还在于能够保证转换代码的正确性,同时也能够相对比较 token-efficient 地生成程序。但是我们也不希望为每个应用都跑一次LLM生成序列,这太耗时也没有办法 scale,所以在这个项目中我们更想做的是去进化编译器本身。更具体地,我们希望去优化编译器里面的优化变换策略(pass),很多经典问题包括函数内联(function inlining)、寄存器分配(register allocation)等问题都是 NP-hard 的,大部分都是基于启发式算法来保证在合理时间内获得足够好的解。这些启发式规则凝结了专家数十年积累的工程直觉,用于权衡各种复杂决策,但这些手工启发式规则有着明显的局限性:它们难以适应快速演进的硬件架构,难以维护,且在面对庞大的、异构的现代软件生态时,往往捉襟见肘。
所以在这个工作中我们尝试去理解 LLM 能不能设计真正可用的启发式算法,并能够将其运用到现代的编译器之中。
- TLDR: Magellan 是一个由 AlphaEvolve 驱动的编码编写、进化搜索与自动调优相结合的系统,能够对编译器里的优化策略进行进化,生成可直接集成到生产级编译器(如LLVM、XLA)中的、高性能的算法。目前 Magellan 的框架和生成的代码都已经在 Google 内部部署,并且被运用到不同的编译器优化问题上。
- 论文链接:https://arxiv.org/abs/2601.21096
- 原文链接:https://chhzh123.github.io/blogs/2026-01-31-magellan/
- 会议链接:https://c4ml.org/
- 代码链接:正在给 LLVM 提 RFC,敬请期待!
Hongzheng Chen, Alexander Novikov, Ngân Vũ, Hanna Alam, Zhiru Zhang, Aiden Grossman, Mircea Trofin, Amir Yazdanbakhsh, “Magellan: Autonomous Discovery of Novel Compiler Optimization Heuristics with AlphaEvolve”, arXiv preprint arXiv:2601.21096, 2026.
将启发式算法设计视为程序合成问题
我在 Google 的团队此前在机器学习与编译器交叉领域也有不少探索,最出名的工作是 MLGO,可以算是工业界第一个将神经网络大规模部署进编译器优化的团队。而利用机器学习进行编译器优化主要有两个方向:
- 神经策略:训练一个神经网络,输入程序特征,输出优化决策。优势是可拟合复杂函数,但需要人工设计特征,同时将神经网络模型集成到编译器中,带来了部署、维护和可解释性的新挑战。这对新的问题、新的优化目标以及新的硬件其实都不太友好,需要重新设计一套流程再训练一个新的神经网络实现。
- 序列优化:正如前面所说,使用 LLM 为每个待编译的程序生成独特的优化序列。这避开了修改编译器本身,但无法积累可复用的知识,每次编译都需要重新搜索,对于大规模应用并不可行。
所以在设计 Magellan 时,我们选择了一条不同的道路:直接进化编译器 Pass 本身的 C++ 实现代码。我们不想生成最终的目标代码,也不为每个程序寻找临时策略,而是合成紧凑、可部署、人类可读的启发式函数,这些函数可以像手写代码一样被插入编译器代码库,长期复用。这直接带来了几个关键优势:
- 无缝集成:生成的代码直接使用编译器原生 API,与现有基础设施完全兼容。
- 可维护性:生成的 C++ 代码可以被工程师理解、审查和调试。
- 零部署开销:编译后的启发式规则就是原生代码,没有神经网络推理的额外延迟或依赖。
- 知识复用:一个在代表性基准测试上发现的优秀规则,可以应用于编译无数个新程序。
Magellan:分层进化搜索闭环
Magellan 则是基于 AlphaEvolve 的进化搜索框架,在它基础上增加了额外的黑盒调优器(autotuner)。这里核心的想法是关注点分离:LLM 只需要关注高层 idea 的实现,而底层的参数调整则交给黑盒调优器。这主要注意到 LLM 其实对数字并不敏感,很多时候在算法里给出的超参数其实只是随机生成的,并没有实际意义,所以超参数的部分不如就交由外部工具来处理。Magellan 的核心是一个四阶段的自动化闭环:
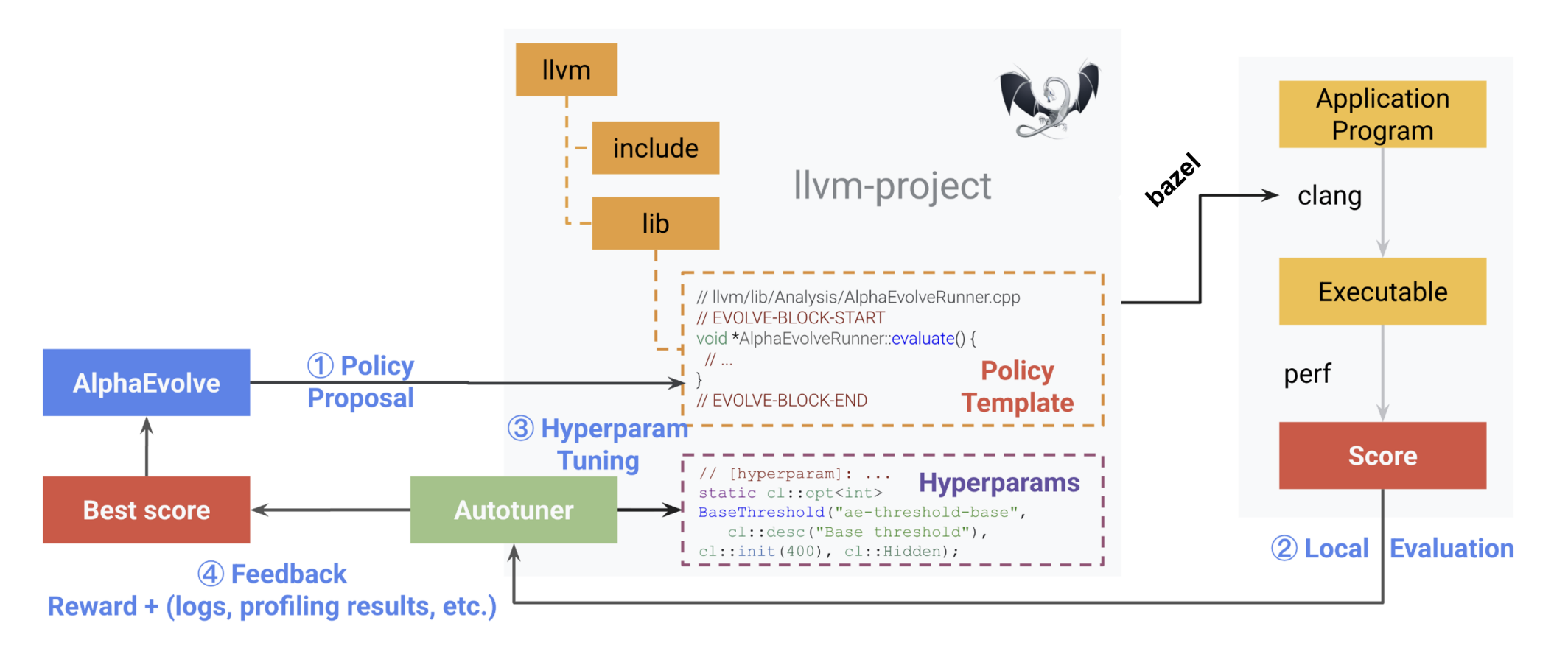
- 策略提案:我们使用集成了 LLM 的 AlphaEvolve 框架,在目标编译器 Pass 的源代码中(被
EVOLVE-BLOCK注释标记的区域)进行修改。LLM 的任务是生成一个”启发式模板”——一段合法的C++代码,但其中的关键数值常数被替换为符号化的超参数(例如BASE_THRESHOLD)。这迫使LLM专注于高层的决策逻辑结构,而非具体的数字。 - 本地评估:将生成的候选启发式(附带默认超参数)插入编译器代码库,重新编译整个编译器。然后,使用这个新编译器在一组真实的宏观基准测试上编译并运行程序,收集目标指标(如最终二进制文件大小、程序运行时间)。这个指标作为该候选启发式的”奖励分数”。
- 超参数调优:固定上一步得到的启发式模板代码,启动一个黑盒优化器(如 Vizier),仅对模板中暴露出的符号化超参数进行调优。优化器基于历史评估结果,提出新的超参数组合,快速在数值空间内寻找更优解。这避免了让昂贵的LLM去”猜测”具体数字。
- 反馈整合:将最佳的超参数配置、评估得分以及性能剖析信息反馈给 AlphaEvolve。进化算法利用这些信息,对启发式模板的代码结构本身进行选择、变异和重组,产生下一代候选模板,进入下一轮循环。
这种”LLM 管代码结构,调优器管超参数”的分层策略是 Magellan 高效的关键。我们发现它极大提升了搜索效率,将无效代码率从 LLM 直接搜索时的超过65%降低到了结合调优器后的仅13%。
案例分析1: 函数内联代码体积优化
这是我接手的第一个问题,也是最开始 MLGO 尝试做的第一个问题。函数内联(function inlining)很好理解,就是把函数体直接插入到调用点,从而减少函数调用开销。但是内联有着大量的 tradeoff,比如内联一些小的函数可以利于后续优化如常量传递的进行,但把所有函数都内联的话会导致代码体积变得非常巨大,执行速度也非常慢,所以这是一个(被证明了的)NP-hard问题。我们在这个问题上的第一个目标是减小最终二进制文件大小,这是一个非常确定性的目标,没有额外的噪音,所以非常适合作为第一个问题来验证 Magellan 的性能。
为了更好地跟之前的方法进行比较,我们设计了两组不同的设置(参见下图):
- 只让 LLM 生成部分启发式算法:输入是跟 MLGO 的神经网络一致的特征(feature),输出则是这些特征组合判断的二元决策(对于一个输入函数是否要内联)
- 让 LLM 生成完整的启发式算法:输入就是一段 IR,输出同样是是否内联的二元决策。但 LLM 在这里可以更自由地设计启发式算法,比如提出新的特征(通过遍历 IR 的方式获得)并且将这些特征以某种方式组合到一起。

我们让 Magellan 从零开始(一个始终拒绝内联的策略),以 Google 内部的搜索引擎作为测试程序,测试了两种不同设置下的结果(见下图)。对于部分启发式算法设置,Magellan 用了1.5天的自动搜索,就合成出了比 LLVM 上游手工启发式算法多减少4.27%代码体积的新规则;而让 LLM 生成完整启发式算法设置下,用同样的搜索时间,它可以最终减少5.23%代码体积。注意这里的基线程序已经是 LLVM 上游最好的启发式算法,并且开了-Oz进行优化。可以看到更加开放的搜索空间,可以给 LLM 更大的自由度去设计启发式算法,最终实现更好的效果。
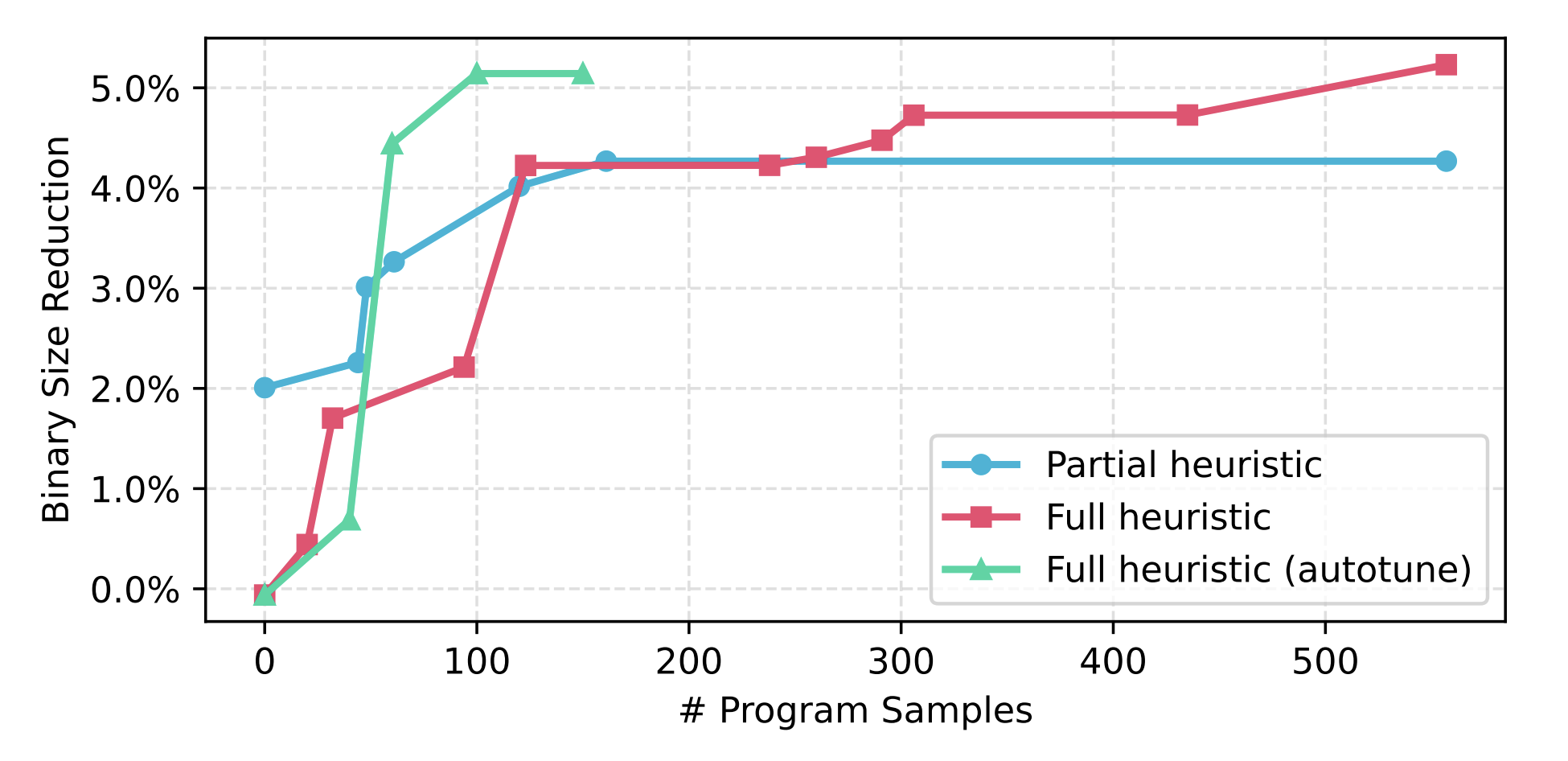
另外一组试验则是进一步开启了调优器,可以看到它大大提升了 Magellan 的搜索效率,大概只需100个程序的采样评估,它就可以达到超过5%的内联体积缩小。
我们也对 LLM 生成的代码进行了分析:它极其简洁,仅143行核心逻辑,比LLVM原有的2000多行实现精简了15倍,但效果更好。其核心洞见在于:激进地内联”单次使用”的函数,使得调用点和整个函数体都可能在后继优化中消失;并为那些在内联后能触发大量死代码消除的函数提供奖励。
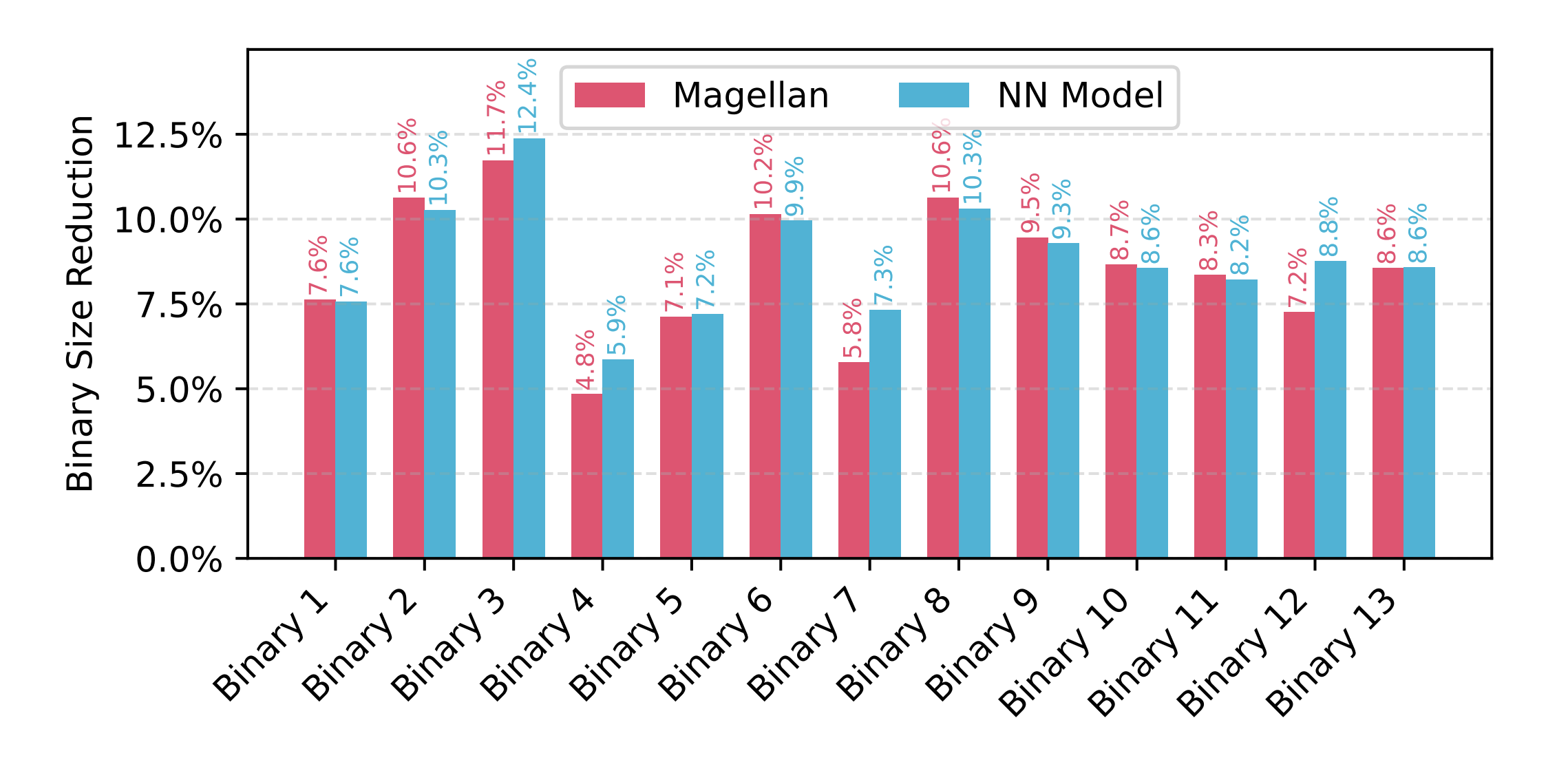
我们还测试了这份代码的泛化能力:我们将该规则应用到不同时间点快照的代码库以及十多个不同的生产级二进制程序(涵盖搜索、嵌入式等不同领域)上,其优化效果依然稳健,平均减少代码体积8.79%,与一个需要大量数据训练和集成的神经网络策略效果相当,且好处在于无需重新训练。
案例分析2: 函数内联运行性能优化
本来我们对 AlphaEvolve 能够优化编译器这件事情并没有报太大的期待,但是有了前面一个问题的成功案例,我们尝试将其运用在更加困难的问题上面。所以我们还是选择了函数内联,但是这次优化目标变成提升程序的运行性能。这是一个更具挑战性的任务,因为性能评估噪音更大、成本更高。
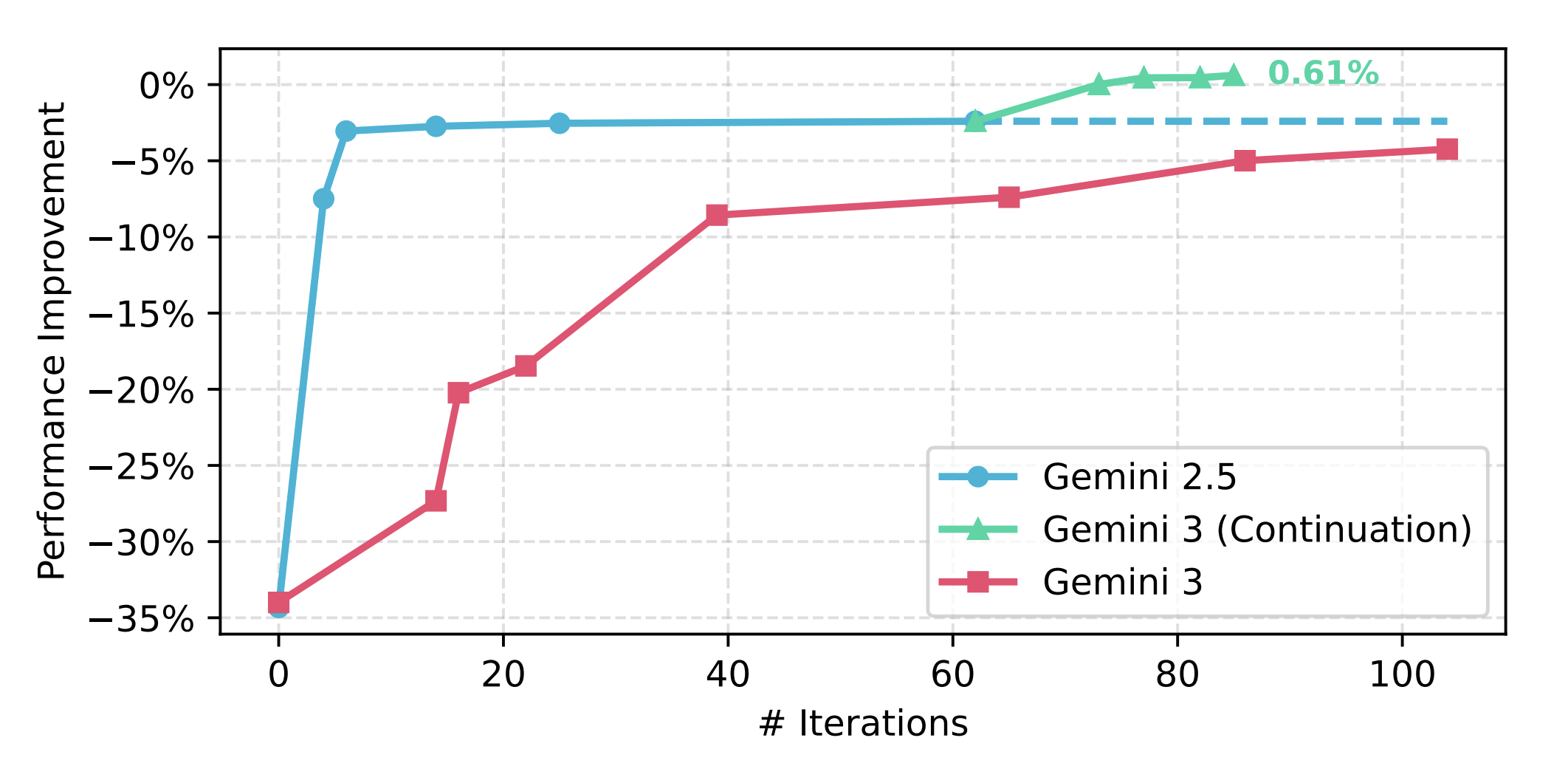
为了更快的迭代速度,在这个任务上我们选择直接优化 clang 编译器本身。我从暑假开始尝试了大量不同的设置,包括不同的 prompt 技巧、不同的 feedback、不同的初始程序、增加调优器的力度等等,但是最终都没有办法超越 LLVM 上游高度优化过的基线程序(开了ThinLTO和-O3优化,见上图)。
而真正的转机是11月底的时候 Gemini 3 对外发布,一开始我们也没有觉得模型提升会带来多大帮助,但我们低估了基模提升对整个领域的创造性改变。当我们把 Gemini-2.5-Pro 生成的最好程序喂给 Gemini-3-Pro 作为初始程序后,Gemini 3迭代了一夜,竟然发现了更好的内联算法,直接超过了 LLVM 开满优化的设置(这也是整个社区二十几年来维护的成果),最终达到0.61%的提升。虽然只是不到1%的性能提升,但是这是之前传统方法(包括使用神经网络)都从未达到过的突破。非常底层的通用优化、大规模数据集、非常强大的基线程序都说明这一点点提升的来之不易。
这条规则采用轻量级 cost model,智能地为常量参数、循环嵌套、向量化代码提供奖励,并为热点调用动态调整阈值,完整代码可以在论文中找到。
这个实验也说明即便是非常底层基础的科学和工程问题,在agentic时代依然有很大的机会能够获得提升。而新时代的摩尔定律或许是坐等新模型出来,之前的没解决的问题就能迎刃而解。
案例分析3:在 LLVM 寄存器分配与 XLA 上的探索
Magellan 的通用性在其他编译器优化任务上也得到了验证,因为生成的算法还未完全整合进 XLA 中,所以在这里不做过多的叙述:
- LLVM 寄存器分配(register allocation):Magellan 的目标是改进贪心寄存器分配器中用于对活跃区间进行排序的优先级函数。在一个大规模生产负载上,Magellan 最终收敛到了一个非常简单的策略:一个常数。这表明在该特定上下文中,复杂的排序规则可能是不必要的,简单的顺序同样有效。这个简洁的策略与复杂的人工规则性能相当。
- XLA 图重写(graph rewrite):在基于 equality saturation 的优化中,从代表无数等价计算方案的 e-graph 中,根据 cost model 选出一个最优方案。Magellan 合成的启发式规则比人工设计的策略提升了7%的效果。
- XLA 自动分片(auto-sharding):为在 TPU 集群上运行的机器学习计算图,自动选择如何将张量切片分布到不同设备上。在遵循 ASPLOS’25 IOPDDL 比赛设定的实验中,Magellan 在一周内进化出的策略,达到了与顶尖竞赛提交方案相当的水平,且无需手工设计复杂的 cost model。
后两个问题也可以在我们的 HeuriGym benchmark 里面找到。
通向自我进化编译器的阶梯
Magellan 的工作标志着编译器自动化进程中的一个重要里程碑:
- 生产力革命:它能够以天为单位,复现甚至超越人类专家数十年的启发式规则积累,将工程师从繁琐的规则调优中解放出来,专注于定义问题和提供评估基准。
- 实用主义:通过生成可集成的 C++ 代码,Magellan 在强大的神经模型与工业界对可靠性、可维护性的严苛要求之间,找到了一个极佳的平衡点。
- 揭示未知:它发现的简洁而有效的规则(如寄存器分配中的常数优先级),促使我们重新思考某些长期使用的复杂启发式是否真的必要,可能揭示了问题更深层的结构。
当然,挑战依然存在。每次候选规则的评估都需要重新编译编译器并运行大规模基准测试,计算成本不菲。如何为更复杂、噪音更大的优化目标(如多目标权衡、功耗)设计高效的搜索策略,仍是我们需要探索的开放问题。展望未来,我们相信 Magellan 有望成为一个通用的”编译器自我进化的平台”:
- 面向新硬件的快速适配:当一款新的 AI 加速器(GPU/NPU)问世时,Magellan 可以自动为其编译器探索出高效的算子调度、内存映射启发式,比如 Tawa 里的图划分,Dato 里的映射规则,这些问题往往没有太多已有的参考文献,属于全新的问题,所以更加考验 LLM 的创新创造能力。
- 与神经网络方法的协同:Magellan可以用于自动发现有效的程序特征,这些特征可以反过来用于训练更高效的神经策略。
- 人机协同设计:工程师提供高层意图和约束,Magellan 负责探索庞大的实现空间,形成高效的合作工作流。开源方面我们会在 LLVM 里面提供可进化的基础代码设施,之后也许可以用 OpenEvolve 等结合实现类似的流程。
这项工作其实也不仅仅关于编译器,它更是一份关于如何利用 LLM 自动化那些高度复杂、基于知识的工程设计蓝图。当机器开始学会编写优化它自身工具的规则时,我们正步入一个软件系统自我进化时代的前夜。
致谢
特别感谢我的 cohost Mircea 和 Amir 对这个 project 的极力推动并在内部广泛宣传,让 AlphaEvolve 以及我们的工作都能在更多的场景下落地。这个工作我在内部讲过不下五次,某种程度上也是让大家看到 agent 对自身工作流程的改变。在现在这种 AI 军备竞赛的环境下在公司里发 paper 已经成了一种非常奢侈的事情,因此我也要感谢 Google 很多很多同事对这个 project 的支持,最后才得以让这个工作这么快发布。在 Google 的半年时间是我这几段实习里非常快乐并且享受的一段,希望之后有机会还会再回来!