Hongzheng Chen Blog
分布式系统(11) - 补充内容
Jan 10th, 2020 0大数据
MapReduce的相关内容见并行编程-MapReduce
分布式机器学习
详情见李沐的论文
Mu Li, David G. Andersen, Jun Woo Park, Alexander J. Smola, Amr Ahmed, Vanja Josifovski, James Long, Eugene J. Shekita, Bor-Yiing Su, Scaling Distributed Machine Learning with the Parameter Server, OSDI, 2014
将集群中的结点分为计算结点和参数服务结点,后者通过分布式存储,各自存储全局参数一部分,并作为服务方接受计算结点参数查询和更新请求。
- server节点的主要功能是保存模型参数、接受worker节点计算出的局部梯度、汇总计算全局梯度,并更新模型参数
- worker节点的主要功能是各保存部分训练数据,从server节点拉取最新的模型参数,根据训练数据计算局部梯度,上传给server节点


分布式深度学习
Kubernetes (K8s)
详情可见
- Kubernetes: Container Orchestration and Micro-Services
- The illustrated Children’s Guide to Kubernetes或PDF版
可以理解成是一种云OS了,统一管理服务器集群上成千上万的Docker容器,基本的功能都有
- Scheduling: Decide where my containers should run
- Lifecycle and health: Keep my containers running despite failures
- Scaling: Make sets of containers bigger or smaller
- Naming and discovery: Find where my containers are now
- Load balancing: Distribute traffic across a set of containers
- Storage volumes: Provide data to containers
- Logging and monitoring: Track what’s happening with my containers
- Debugging and introspection: Enter or attach to containers
- Identity and authorization: Control who can do things to my containers
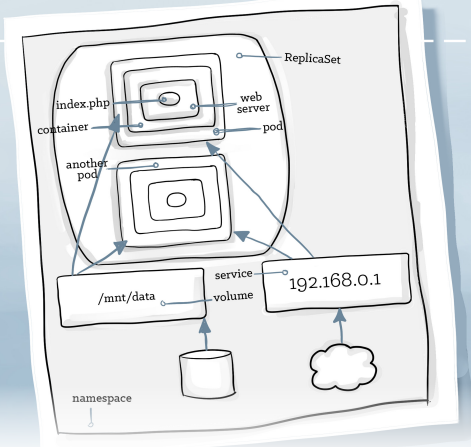
基本组成:
- Container:里面包裹应用及其依赖环境
- Pod:一个可运行工作单元,里面可放一个或多个容器(如果容器紧耦合),带有label
- ReplicaSets:包含一个Pod模板,可以被多次复制
- Services:永久化存储,提供IP地址(注意K8s中IP都被映射到集群内部,即不通过NAT的形式),通过label selector找到pod
- Volumes:Pod可以直接mount一个文件系统
- Namespaces:则是将上述内容全部包裹在一起
云原生系统DevOps
微服务(microservice)是指通过开发一组微型服务来组成一个单一应用的方法。这每一个小的服务都自成一体,运行在自己的进程中,彼此之间通过轻量级的机制,通常是HTTP资源API的方式,来进行通信。这些小服务一般基于既定的业务能力范围来构建,通过完全自动化部署的机制来进行独立部署。——Martin Fowler & James Lewis
传统开发过程都是一群人build->test->release,然后构成单体(monolith)APP,但现在的开发过程则是一个个小组分别build->test->release形成各自的微服务。

连续集成(Continuous Integration, CI):可以通过Github/GitLab和Jenkins/Travis CI结合云平台Docker+Kubernetes实现。

DevOps原则
- 基础设施即代码(infrastructure as code)
- 持续交付(continuous delivery)
- 协同工作(culture of collaboration)