Hongzheng Chen Blog
分布式系统(5)-命名系统
Aug 29th, 2019 0名称、标识符和地址
- 本质:用名字标识分布式系统中的实体对象,由字符组成的字符串。实体可以是分布式系统中的任何事物,包括主机、打印机、磁盘和文件等硬件资源,还包括:用户、邮箱、消息等抽象资源。
- 访问点(access point):对实体可进行一系列的操作,需要访问实体,因此需要一个访问点。访问点是一类特殊的实体,访问点的名称成为地址。实体的访问点的地址即为该实体的地址。
一个独立于实体地址的名称通常是比较合理的,而且更为灵活,这样的名称与位置无关
原则上,命名系统含有一个名称到地址的绑定,即一个存(name,address)对的表
无层次命名
转发指针
当实体移动的时候,会在当前位置留下到下一个位置的指针
- 去引用对于客户端来讲变得完全透明,只需要沿着指针连搜索
- 当实体的当前地址找到后,更新客户端的引用
- 扩展性问题(地理可扩展性):
- 较长的传播链很脆弱,容易断开
- 实体的定位开销比较大
基于宿主位置的方法
- 广播和转发指针的使用的主要缺点是可扩展性的问题,且容易受到链断开的影响
- 单层模式:让宿主机记录实体的位置
- 实体的宿主地址注册在命名服务上
- 宿主机注册实体的外部地址
- 客户端需要先与宿主机联系,然后与外部地址联系
基于宿主机的方法存在的问题
- 宿主机需要伴随实体的整个生命周期
- 宿主机的地址是固定的=>如果实体对象永久迁移会带来不必要的问题
- 较差的地域可扩展性(实体可能就在客户端旁边)
注意:实体永久移动可以通过DNS解决
分布式散列表
- 众多节点组织成环形结构
- 每一个节点被赋予一个由m位构成的标识符
- 每一个实体被赋予一个唯一的m位的健值
- 键值为k的实体存储在满足id>=k的最小标识符节点上,成为k的后继者,succ(k)
无扩展性搜索方法
- 令每一个节点记录它的邻居,并且进行线性的搜索
Chord指状表(finger table)
- 每一个节点p维护一个最多含有\(m\)个元素的指状表:\(FT_p[i]=succ(p+2^{i-1})\)
- 要查找键值\(k\),结点p将请求转发给在p的指状表中索引为j的结点q,其中
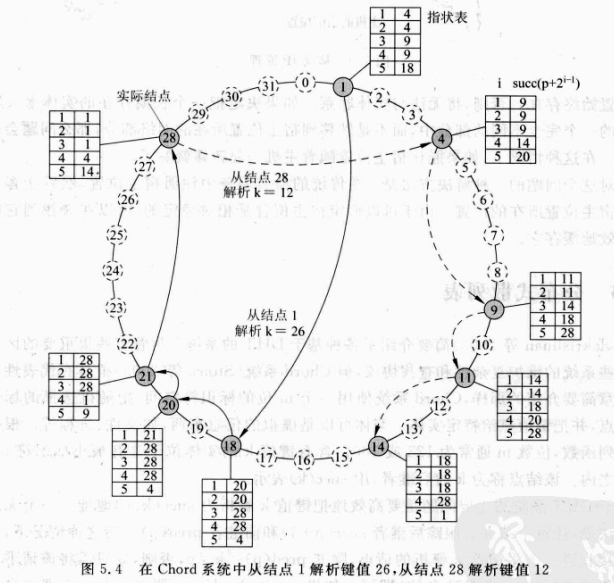
假设结点p要加入,只需与已有系统中的任意节点联系,并请求查找succ(p+1)。一旦标识了该节点,p就可以将自己插入到环中。
这里每个结点需要定期运行一个进程来与succ(q+1)联系,并请求返回pred(succ(q+1))。若q=pred(succ(q+1)),则其信息与后继者一致。
存在问题
- 覆盖网络中的节点之间的组织结构可能导致在底层互联网上的异常的消息传输:如节点p和节点succ(p+1)实际距离非常远
解决方法
- 基于拓扑的节点标识符赋值:其思想是在标识符赋值时,两个邻近节点所赋予的标识符也是靠近的,在Chord系统中存在严重问题
- 邻近路由:节点维护一个转发请求的可选列表。每个节点有多个后继者,查询时选择最近的一个。例如:对于节点\(p\),\(FT_p[i]\)指向\([p+2^{i-1},p+2^i-1]\)区间内的第一个节点,但是也可以指向其他节点,选择距离最 近的一个邻节点选择,优化路由表,使得选择最近的节点作为邻结点
分层方法
创建一个大规模的搜索树,底层网络被划分为多个分层的域,每个域由一个目录结点表示
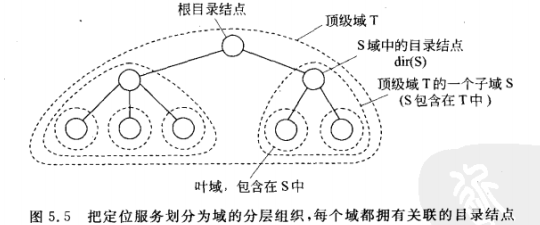
树的组织结构:不变量
- 实体E的地址存储在叶节点或者中间节点上
- 中间结点包含了指向其孩子节点的指针,当且仅当根植于孩子节点的子树存储有实体的地址
- 根节点知道所有实体的地址
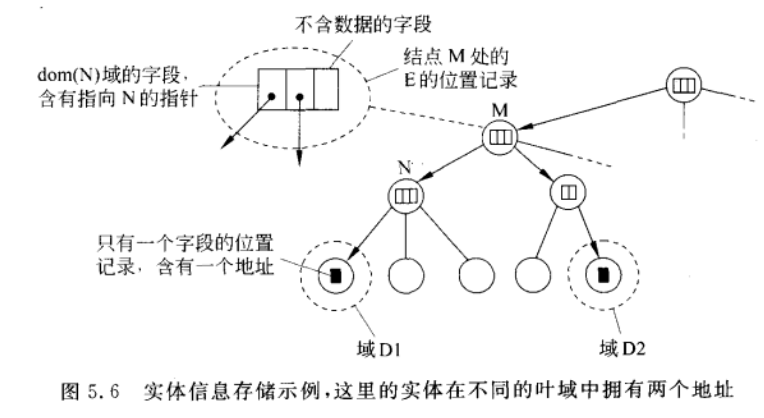
树结构的查询操作基本原理
- 开始在一个叶节点上搜索
- 如果节点知道实体E=>继续搜索下游指针,否则回退到父节点
- 向上搜索的过程最终会以到达根节点而停止
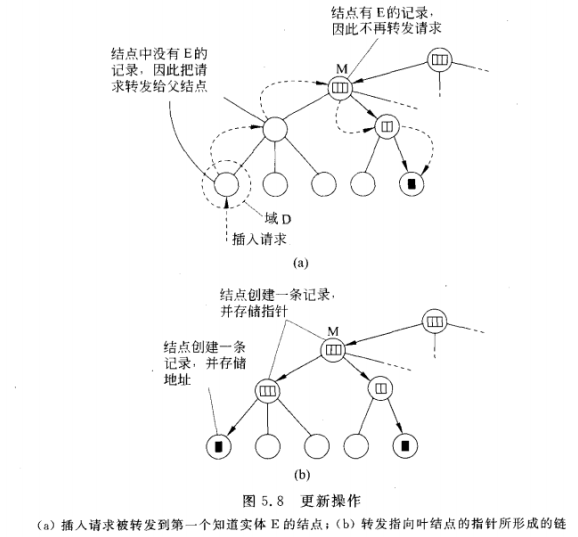
插入实体E:递归过程
- 插入请求被转发到知道实体E地址的第一个结点
- 建立一条从第一个知道实体E地址的结点到实体E的指针链
结构化命名
名称解析
给定一个路径名,查找出存储在由该名称所指向的节点中的任何信息,查询名称的过程称为名称解析。
名称解析-闭包机制(closure mechanism):知道如何启动以及在何处启动名称解析通常称为闭包机制
- www.distributed-systems.net:从DNS服务器开始
- /home/maarten/mbox:从本地的NFS服务器开始
- 222.200.145.180:把消息路由到特定的P地址
链接(Name linking)
- 硬链接(Hard link):我们所描述的路径名即用于在命名图中按照特定路径搜索节点的名字就是“硬链接”
- 软链接(Soft link):允许一个节点包含另外一个节点名字,用叶节点表示实体,而不是存储实体的地址和位置,该节点存储绝对路径名。
- 首先解析N的名字
- 读取N的内容返回名字
- 利用返回的名字进行名字解析
挂接点与挂载点
命名解析也可以应用于合并不同的命名空间,通过挂载的方法透明地实现;将另异空间的节点标识符与当前命名空间的节点相关联
- 外部命名空间:需要访问的命名空间
- 挂接点:在当前命名空间中用于存储节点标识符的目录节点成为挂接点
- 挂载点:外部名称空间中的目录节点称为挂载点;挂载点是命名空间的“根”
通过网络挂载
- 访问协议的名称
- 服务器名称
- 外部名称空间中的挂载点名称
命名空间实现
名称通常组织为名称空间(namespace)
三层名称空间
跨越多个机器的分布式命名解析过程与命名空间管理是通过将命名图分布在多个节点上实现的
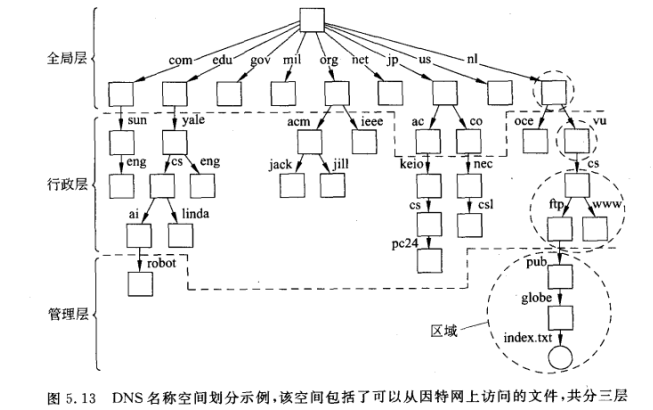
- 全局层:由最高级别的节点构成,即由根节点以及其他逻辑上靠近根节点的目录节点组成。特点是:稳定,目录表很少改变,可以代表组织或者组织群。
- 行政层:由那些在单个组织内一起被管理的目录节点组成。行政层中的目录节点所具有的特点是代表属于同一组织或行政单位的实体组;相对稳定,但是比全局层的目录变化频繁
- 管理层:由经常改变的节点组成。如代表本地主机的节点及本地文件系统等,由终端用户维护
可用性问题
- 全局层要求具有很高的可用性
- 行政层可用性要求最高
- 管理层的可用性要求不高
性能问题
- 使用缓冲机制可以增加全局层命名解析的性能
- 使用高性能服务器来运行命名服务器
扩展性问题
- 规模可扩展性
- 我们需要保证命名服务器每秒钟可处理大量的请求=>高层次的服务器面临较大的挑战
- 假定(至少在全局层和行政层)节点的内容几乎不发生变化。我们可以应用扩展备份将节点的内容映射到多个服务器,从最近的服务器上开始命名解析
观察发现很多节点的一个很重要的属性是代表实体的地址是可以访问的,但是复制节点会让大规模传统的命名服务器不适合用于定位移动实体
命名解析
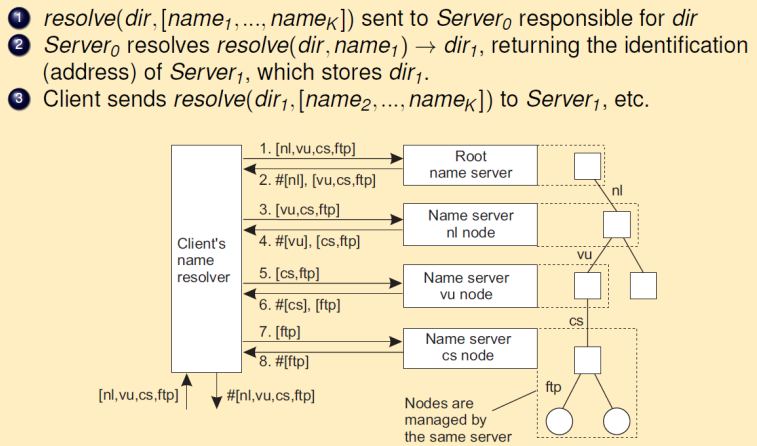
迭代命名解析
名称解析程序将完整的名称转发给根服务器,根服务器会尽力返回能解析的部分,然后客户继续将剩下的路径名转发到下一台名称服务器,该服务器再解析一部分。名称的每一个部分都通过客户向不同的名称服务器进行解析得到
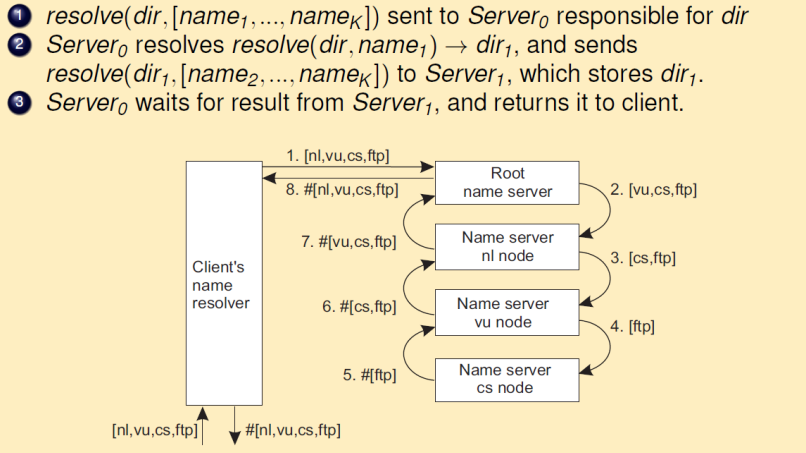
递归命名解析
客户将名称解析请求发送到名称服务器后,名称服务器会把结果传递给它找到的下一台 服务器,下一台服务器如果故需要的话会继续转发,直至完整的名称解析完成,然后返回客户。
比较
- 递归
- 缺点:对名称服务器要求高
- 优点:缓存有效,减少通信开销
- 迭代
- 不容易使用缓存策略进行优化
DNS域名解析系统本质
- 命名空间被组织成分层结构,每一个节点有一个显式的进入边
- 域(domain):子树
- 域名:指向域根节点的路径名字,可以是绝对的也可以是相对的