Hongzheng Chen Blog
分布式系统(9) - 共识
Jan 10th, 2020 0详情可见
Amir H. Payberah, Distributed Systems Consensus
共识:使所有非故障进程就由谁来执行命令达成一致,而且在有限的步骤内就达成一致。
有一些结点提出了一些值或动作,并传送给其他结点,所有结点都应决定是否接受或者回绝这些值。
共识协议分类
- 失效容错
- 泛洪:准确检测失效
- 最终检测到失效:Pasox、Raft、ZAB
- 拜占庭容错
- BFT、PBFT、PoW
共识的需求
- 安全性
- 合法性(validity):只有一个被提出的值会被选择
- 一致性(agreement):没有两个正确的结点选择了不同的值
- 正直性(integrity):一个结点最多选择一次
- 活性(liveness)
- 终止(termination):每一个正确的结点最终总会选择一个值
泛洪
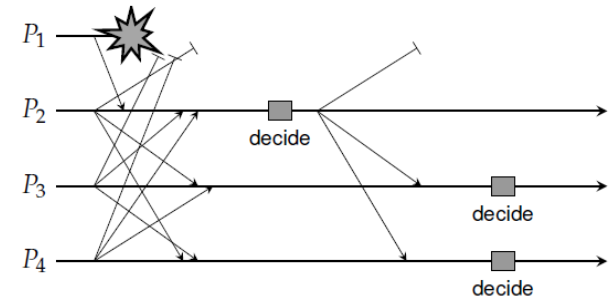
只有获得所有进程提交的命令才做出决定
- P2 获得所有进程提交的命令,因此作出决定
- P3 可能已经检测到 P1 失效,但是不知道 P2 是否也检测到了失效,也就是说 P3 不知道自己的信息是否与P2一致,因此不做决定
任意失效语义下的共识
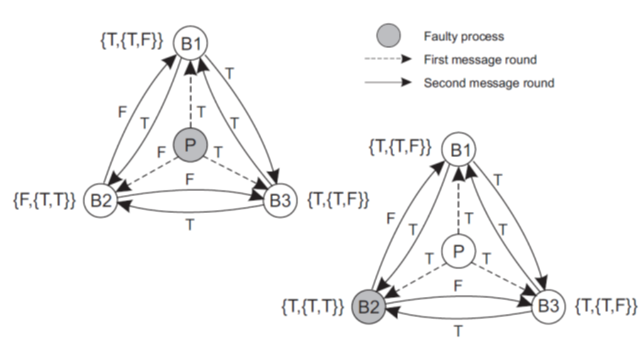
需要\(3k+1\)个进程才能保证共识
两阶段提交(2PC)
系统充满了一切未知,包括并发进程、未知时序、失效等
比如要约朋友聚餐
- 给每个人打电话询问某天晚上是否可以(voting)
- 如果可以,每一个朋友都要返回ACK(commit)
- 可以就要保留slot
- 需要记下每个人的决策,在commit/abort阶段告知没有办法联系上的那些人
- 如果有一个人不行,那么告知其他人取消(abort)
两种类型参与者
- 协调者(coordinator):开始事务,对commit/abort负责
- 参与者(participant)
进而有两阶段提交协议:
- 准备(prepare)阶段
- 协调者告知每一个参与者可以提交(VOTE_REQUEST)
- 参与者需要准备提交:锁上对象,然后VOTE_COMMIT告知已准备好
- 提交(commit)阶段
- 协调者收集所有选票,如果全部yes,那么GLOBAL_COMMIT
- 只要有一个no,就GLOBAL_ABORT
有限状态机:
- 协作者:INIT->WAIT->ABORT/COMMIT
- 参与者:INIT->READY->ABORT/COMMIT
崩溃及恢复
所有结点都需要有日志记录
协作者失效:
- 没有在磁盘上发现commit,则abort,恢复之后重新发送VOTE_REQUEST
- 如果发现commit(已经做出表决,只要记录表决结果就可以了),恢复时重发这个决定
参与者失效
- INIT:没有问题:参与者还不知道发送的信息
- READY:参与者正在等待提交或者终止的信息。恢复后,参与者需要知道它要采取的动作 => 利用日志记录协作者的决定
- ABORT: 此时状态是幂等的,重新执行一遍
- COMMIT: 此时状态也是幂等的,重新执行一遍
即使添加了恢复系统,2PC也不是真正容错的(safe but not live),因为只要有一个机器崩溃了,它都会导致阻塞(blocked)。
三阶段提交协议
两节点提交的一个问题在于当协作者崩溃时,参与者不能做出最后的决定,处于阻塞状态,进而有三阶段提交协议
- 协作者:INIT->WAIT->ABORT-/PRECOMMIT-COMMIT
- 参与者:INIT->READY->ABORT-/PRECOMMIT-COMMIT
PAXOS
Fischer-Lynch-Paterson (FLP)在下面这篇论文
M.J. Fischer, N.A. Lynch, and M.S. Paterson, Impossibility of distributed consensus with one faulty process, Journal of the ACM, 1985
中证明了在一个异步系统中只要有一个进程不可靠,就不存在这样的协议保证在有限时间内所有进程都能达成一致(保证安全性和活性)。但它没有说明的是,在实际中如何尽可能接近理想情况(总是安全且活的)。
目前唯一的完全安全的(completely-safe)且很大程度上是活的(largely-live)共识协议,由Lamport提出
I L. Lamport, The part-time parliament, ACM Transactions on Computer Systems, 1998
包括三个角色(一个结点可同时充当多种角色):
- 提出者(proposer):提出值给acceptor,相当于2PC中的参与者
- 接受者(acceptor):考虑提出者提出的值,并作出accept/reject决策,相当于2PC中的协调者
- 学习者(learner):学习选择的值
Paxos包括四个阶段:
- (a)准备阶段(prepare)
- proposer选择提议数字 \(n\) ,发送prepare请求给大多数acceptor
- (b)许诺阶段(promise)
- 若acceptor收到prepare请求有着比 \(n\) 大的数字,它回复yes,同时保证(promise)不再接受任何提议小于 \(n\) 的数字
- (a)接受阶段(accept)
- proposer从大多数接收者中接收到yes,则它发送accept请求给这些acceptor
- (b)已接受阶段(accepted)
- 若acceptor收到accept请求 \(n\) ,则它接收这个值(除非它已经回应了一个更大的值)

单一提议(proposal)下,接受占大多数的值。可以有多个提议,多个接受者,但选择出来的提议都应有相同值。
应用:
- Google:Chubby
- Yahoo:Zookeeper
- UW:Scatter
RAFT (Replicated And Fault Tolerant)
Diego Ongaro and John Ousterhout (Stanford), In Search of an Understandable Consensus Algorithm, ATC, 2014 (Best paper)
Paxos虽然非常接近理论峰点,但是可理解性太弱,很难实现,存在以下问题:
- 不完备
- 只在单一值上同意
- 没有解决活性问题
- 低效
- 需要两轮才能选出一个值
因此提出了RAFT,更易理解更易实现。
关于RAFT完整例子过程见https://raft.github.io/
RAFT通过分解(decomposition)将复杂的过程化简为简单的过程
- Leader选举
- 选择一个server成为leader
- 发现崩溃则选择新的leader
- 日志复制
- leader接收客户发来的命令,将其添加到日志
- leader复制日志到其他服务器上,复写(overwrite)不一致
- 安全性
- 保持日志一致
- 只有有着最新日志的服务器可以成为leader
三个成员:Leader、Follower、Candidate
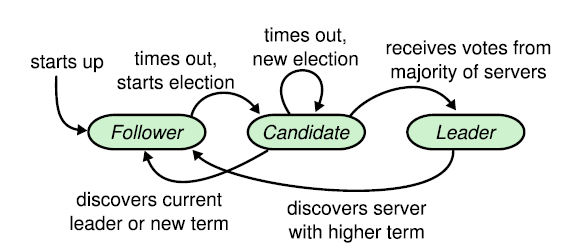
强化leader的地位(strong leader),把整个协议可以清楚的分割成两个部分,并利用日志的连续性做了一些简化:
- Leader在时,只由Leader向Follower同步日志
- Leader挂掉了,Leader election(随机时钟),转移Leader (memebership changes)
以上三点也是原始论文中提及的最大特性。