并行编程-CUDA
CUDA(Compute Unified Device Architecture)主要用于GPU上的编程,让SIMD能够对应用更加通用
GPU与CUDA简介
GPU利用Moore定律
- 增加片上并行性及DRAM带宽
- 为图形应用提升灵活性和性能
- 加速通用数据并行任务
CUDA的目标:
- 可扩展性:任意顺序执行的独立块,线性加速比
- SIMD编程性:充分利用硬件架构,但CPU的SIMD往往很难使用,CUDA抽象提供编程性
CUDA GPU是流多处理器(streaming multiprocessors, SM)的集合,每一个SM都是一个SIMD执行流水的集合(scalar processors),共享控制逻辑、寄存器堆、L1 cache。
Nvidia GPU架构演变
- Tesla (2006)
- Fermi (2010)
- Kepler (2012)
- 提供二级缓存一致性
- Maxwell (2014)
- Pascal (2016)
- 支持NVLink
- Volta (2017)
- Turing (2018)
安装
- https://developer.nvidia.com/cuda-downloads
- https://docs.nvidia.com/cuda/cuda-quick-start-guide/index.html
注意:现在WSL还不支持GPU!
Hello World
由于GPU一般作为协处理器,故CPU与GPU常构成异构系统,其中CPU为host,GPU为device。
典型CUDA程序执行流程如下:
- 分配host内存,并进行数据初始化;
- 分配device内存,并从host将数据拷贝到device上;
- 调用CUDA的核函数(kernel function)在device上完成指定的运算;
- 将device上的运算结果拷贝到host上;
- 释放device和host上分配的内存。
#include <iostream>
#include <math.h>
// Kernel function to add the elements of two arrays
__global__
void add(int n, float *x, float *y)
{
for (int i = 0; i < n; i++)
y[i] = x[i] + y[i];
}
int main(void)
{
int N = 1<<20;
float *x, *y;
// Allocate Unified Memory – accessible from CPU or GPU
cudaMallocManaged(&x, N*sizeof(float));
cudaMallocManaged(&y, N*sizeof(float));
// initialize x and y arrays on the host
for (int i = 0; i < N; i++) {
x[i] = 1.0f;
y[i] = 2.0f;
}
// Run kernel on 1M elements on the GPU
add<<<1, 1>>>(N, x, y);
// Wait for GPU to finish before accessing on host
// default asynchronous, different from OpenMP
cudaDeviceSynchronize();
// Check for errors (all values should be 3.0f)
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(y[i]-3.0f));
std::cout << "Max error: " << maxError << std::endl;
// Free memory
cudaFree(x);
cudaFree(y);
return 0;
}
基本语法
__global__:核函数,在device上线程中并行执行的函数,从host中调用(一些特定的GPU也可以从device上调用),返回类型必须是void,不支持可变参数参数,不能成为类成员函数,只能访问设备内存。注意用__global__定义的kernel是异步的,这意味着host不会等待kernel执行完就执行下一步__device__:在device上执行,仅可以从device中调用,不可以和__global__同时用__host__:在host上执行,仅可以从host上调用,一般省略不写,不可以和__global__同时用,但可和__device__,此时函数会在device和host都编译
内存操作
cudaError_t cudaMalloc(void** devPtr, size_t size);cudaFree(void*)cudaError_t cudaMemcpy(void* dst, const void* src, size_t count, cudaMemcpyKind kind):kind控制复制的方向cudaMemcpyHostToHost, cudaMemcpyHostToDevice, cudaMemcpyDeviceToHost及cudaMemcpyDeviceToDevicecudaError_t cudaMallocManaged(void **devPtr, size_t size, unsigned int flag=0):自CUDA 6.0开始,统一管理内存,自动进行数据传输
层次结构
CUDA编程模型分为4级层次结构(同样可以map到其他硬件上)
- Stream = list of grids (whole GPU)
- Grid = \(2^32\) thread blocks
- Thread Block = up to 1024 cuda threads
- Cuda Thread: SIMD lane
- Warps: logical SIMD width
每一个cuda线程都有自己的控制流、PC、寄存器、堆栈,能够访问GPU任意全局内存地址
threadIdx.{x,y,z}
blockIdx.{x,y}
Kernel上的两层线程组织结构如下(2-dim)
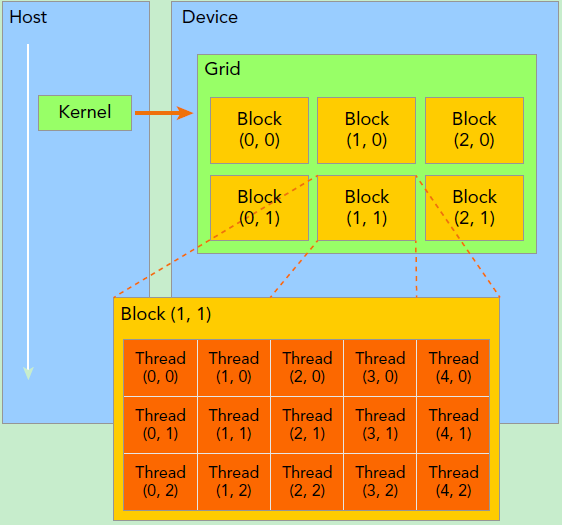
一个线程需要两个内置的坐标变量(blockIdx,threadIdx)来唯一标识,都是dim3变量。<<<grid,block>>>代表网格、线程块数目。
关于dim3的结构类型
dim3是基于uint3定义的矢量类型,相当于由3个unsigned int型组成的结构体。uint3类型有三个数据成员unsigned int x; unsigned int y; unsigned int z;- 可使用于一维、二维或三维的索引来标识线程,构成一维、二维或三维线程块(block)。
- 相关的几个内置变量
threadIdx,顾名思义获取线程thread的ID索引;如果线程是一维的那么就取threadIdx.x,二维的还可以多取到一个值threadIdx.y,以此类推到三维threadIdx.z。blockIdx,线程块的ID索引;同样有blockIdx.x,blockIdx.y,blockIdx.z。blockDim,线程块的维度,同样有blockDim.x,blockDim.y,blockDim.z。gridDim,线程格的维度,同样有gridDim.x,gridDim.y,gridDim.z。
- 对于一维的
block,线程的threadID = threadIdx.x - 对于大小为
(blockDim.x, blockDim.y)的二维blockint i = blockIdx.x * blockDim.x + threadIdx.x;int j = blockIdx.y * blockDim.y + threadIdx.y;
- 对于大小为
(blockDim.x, blockDim.y, blockDim.z)的三维block,线程的threadID = threadIdx.x+threadIdx.y*blockDim.x+threadIdx.z*blockDim.x*blockDim.y - 对于计算线程索引偏移增量为已启动线程的总数,如
stride = blockDim.x * gridDim.x; threadId += stride
dim3 grid(3, 2);
dim3 block(5, 3);
kernel_fun<<< grid, block >>>(prams...);
// Thread(1,1)
// threadIdx.x = 1
// threadIdx.y = 1
// blockIdx.x = 1
// blockIdx.y = 1
- 每一个线程都有私有的寄存器,64/128KB的寄存器堆会划分到每一个线程上
- 每一个线程块都有一块共用内存(on-chip)
- 每一个网格共用一块大的全局共享内存(同时有一个768KB的共享L2)
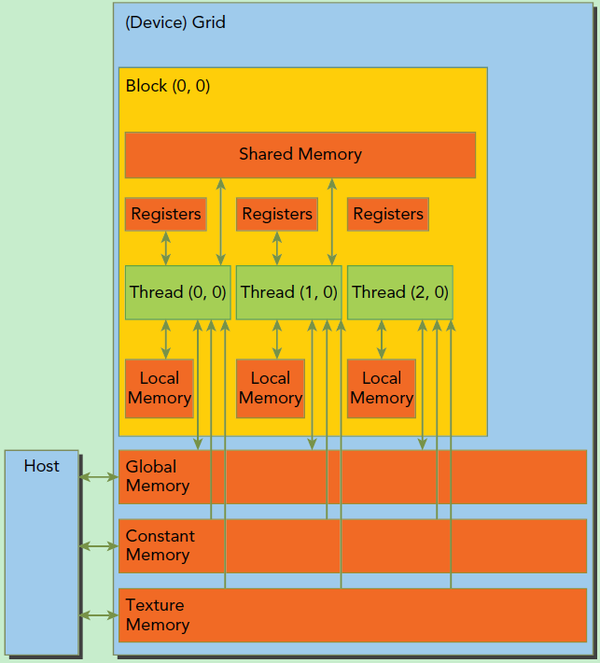
| 变量声明 | 存储器 | 作用域 | 生存周期 |
|---|---|---|---|
int var |
寄存器 | 线程 | 线程 |
int array_var[100] |
寄存器/本地 | 线程 | 线程 |
__shared__ int shared_var |
共享 | 线程块 | 线程块 |
__device__ int global_var |
全局 | 全局 | 应用程序 |
__constant__ int constant_var |
常量 | 全局 | 应用程序 |
深拷贝
- 在结构体中不使用指针,而使用一个index表明数据位置
- 需要传输一个数组的dataElem时,只需两次拷贝
- 一次拷贝
dataElem数组
- 一次拷贝数据
all_names - 数据(
name)在内存空间中连续struct dataElem{ int prop_0; int prop_1; int name_pos, name_len; } char* all_names;
常量内存
- 存储与GPU DRAM中(与全局内存一样)
- 每个SM上有专用的片上缓存
- 常量缓存中读取的延迟比常量内存中低的多
- 在运行时设置
__constant__ int const_var[16];
__global__ void kernel(){
int i = blockIdx.x;
int value = const_var[i%16];
}
__constant__ int const_var[16];
__global__ void kernel(){
int i = blockIdx.x * blockDim.x + threadIdx.x;
int value = const_var[i%16];
}
常量内存的最佳访问模式
- 基于blockIdx访问
- 所有线程访问同一内存(广播访问),无串行访问,只需要一次内存读取
- 线程块中其他线程所需数据也同样会命中缓存
常量内存的最差访问模式
- 基于threadIdx访问
- 线程访问多个不同内存,需要串行访问,需要16次内存读取
- 线程块中其他线程所需数据可能不会命中缓存
纹理内存
- 数据均为只读,不能在设备端代码中修改
- 声明全局纹理引用
texture<Datatype, Type, ReadMode> tex - 调用过程
- 分配内存空间→绑定纹理→核函数调用→解除绑定→释放内存
cudaBindTexture()、cudaBindTexture2D()cudaUnbindTexture()
- 分配内存空间→绑定纹理→核函数调用→解除绑定→释放内存
- 与全局内存对比:分配内存空间->核函数调用->释放内存
#define N 1024 texture<float, 1, cudaReadModeElementType> tex; __global__ void kernel() { int i = blockIdx.x * blockDim.x + threadIdx.x; float x = tex1Dfetch(tex, i); } int main() { float *buffer; cudaMalloc(&buffer, N*sizeof(float)); cudaBindTexture(0, tex, buffer, N*sizeof(float)); kernel <<<grid, block >>>(); cudaUnbindTexture(tex); cudaFree(buffer); }
只读缓存
- 使用内部函数
__ldg()代替标准指针解引用,并且强制通过只读数据缓存加载__global__ void kernel(int *buffer) { int i = blockIdx.x * blockDim.x + threadIdx.x; int x = __ldg(&buffer[i]); } int main() { int *buffer; cudaMalloc(&buffer, sizeof(int)*N); kernel <<< grid, block >>>(buffer); cudaFree(buffer); } - 使用全局内存的限定指针
- 使用
const __restrict__表明数据应该通过只读缓存被访问__global__ void kernel(const int* __restrict__ buffer){ int i = blockIdx.x * blockDim.x + threadIdx.x; int x = buffer[i]; } int main() { int *buffer; cudaMalloc(&buffer, sizeof(int)*N); kernel << <grid, block >> >(buffer); cudaFree(buffer); }
- 使用
- 常量缓存更适用于统一读取
- 线程束中的每一个线程都访问相同的地址
- 只读缓存更适用于分散读取
- 线程束中的每一个线程访问不同地址
共享内存
读写速度非常快,带宽>1TB/s
存储体(bank)和访问模式
- 共享内存被分为32个同样大小的内存模型(存储体)
- 不同存储体可同时被访问
- 访问模式
- 并行访问:多个地址访问多个存储体
- 串行访问:多个地址访问同一存储体
- 广播访问:单一地址读取单一存储体
- 存储体冲突(bank conflict)
- 多个地址访问同一个存储体(串行)
- 广播访问不引发存储体冲突
- 只发生在同一个线程束的线程中
- 32个存储体与32个线程
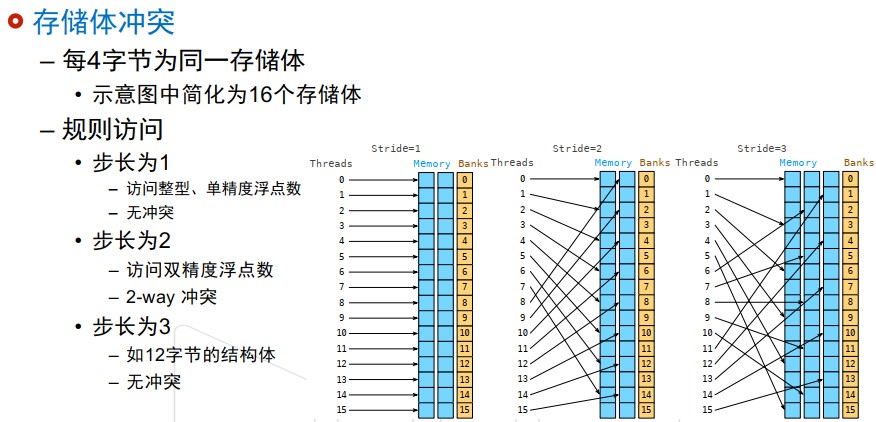
可通过修改步长来消除存储体冲突(会导致消耗内存增加)。
编译运行
- 编译器
nvcc - 性能分析器
nvprof - 查看GPU信息
nvidia-smi
范例
- 用法举例:
CHECK(cudaMalloc((void**)&a, n_bytes));#define CHECK(call) \ { \ const cudaError_t error = call; \ if (error != cudaSuccess){ \ printf("Error: %s:%d, ", __FILE__, __LINE__); \ printf("code:%d, reason: %s \n", \ error, cudaGetErrorString(error)); \ exit(1); \ } \ } - 向量相加,每个block开m个线程(32),共开n/m个block(要判断是否越界),block按1D方式组织(这样每个线程只做一个加法可能工作量太小了)
__global__ void vector_add(int *a, int* b, int* c, int n){ int tid = blockDim.x * blockIdx.x + threadIdx.x; if (tid < n){ c[tid] = a[tid] + b[tid]; } } int divup(int n, int m){ return (if (n%m) ? (n/m+1) : (n/m)); } vector_add<<< divup(n,m), m>>>(a, b, c); - 矩阵相加,如果用二维grid/block,会导致block中线程访问的内存空间不连续,且在x和y维度上都可能出现余数,因此使用一维grid/block会比较好
__global__ void matrix_add(int *A, int *B, int *C, int n, int m){ int tid = blockDim.x * blockIdx.x + threadIdx.x; if ( tid<n*m ){ C[tid] = A[tid] + B[tid]; } } matrix_add<<< divup(n*m, block_size), block_size >>>(A, B, C, n, m); - 六阶中心差分估计一阶偏导\(f'(x)\approx c_0(f(x+3h)-f(x-3h))+c_1(f(x+2h)-f(x-2h))+c_2(f(x+h)-f(x-h))\)
- 存在大量重复的全局内存访问(每个大小为BDIM的block所需全局内存访问次数为BDIM*6)
- 解决方案:一次性将全局内存读入至共享内存
__global__ void stencil(float *in, float *out){ __shared__ float smem[BDIM+2*RADIUS]; //thread index to global memory int tid = blockIdx.x*blockDim.x + threadIdx.x; //index to shared memory int sid = threadIdx.x + RADIUS; //copy to shared memory smem[sid] = in[tid]; if (threadIdx.x < RADIUS) { smem[sid-RADIUS] = in[tid-RADIUS]; smem[sid+BDIM] = in[tid+BDIM]; } __syncthreads(); float tmp = 0.0f; for(int i = 1; i <=RADIUS; ++i){ tmp += c[i]*(smem[sid+i]-smem[sid-i]); } out[tid] = tmp; }
参考资料
- An Even Easier Introduction to CUDA, https://devblogs.nvidia.com/even-easier-introduction-cuda/
- Grossman and McKercher, Professional CUDA C Programming
- CUDA Education, https://developer.nvidia.com/cuda-education
- CUDA编程入门极简教程 - 小小将的文章 - 知乎,https://zhuanlan.zhihu.com/p/34587739
- CUDA-“从入门到放弃”,https://www.jianshu.com/p/34a504af8d51