Hongzheng Chen Blog
深度学习框架与图分析框架的异同
Jan 31st, 2019 0什么是框架(Framework)?
- 对某个特定领域的各种算法进行抽象
- 抽取其中大量重复利用的单元成为算子
- 在现有编程语言(Python/C++)基础上提供API接口
- 注意尚未达到编程语言的级别,如果连语法(syntax)也一并规定,那就变成领域特定语言(Domain Specific Language, DSL)
简而言之,框架是大量可重用的基础设施/库的集合,而语言需添加语法元素
| 深度学习框架 | 图框架 | |
|---|---|---|
| 算子 | 卷积conv 池化pooling 激活relu |
收集gather 应用apply 分发scatter |
| 自定义函数 | forward |
process_message |
| 现有框架 | Tensorflow (Google) Pytorch (Facebook) MXNet (Amazon) |
Pregel (Google) Giraph (Facebook) Spark (Apache) |
注意上表中的内容只是举例,还有很多算子、函数和框架并未列出
框架的好处
- 统一算子并提供API,在这些算子的基础上搭建上层建筑就好(有点C++标准库的感觉)
- 一定程度上规定了用户的行为,优化变得简单,只需对算子进行优化即可
- 可以利用自己熟悉的语言进行操作,无需学习新的语法语义;所谓调包实际上也是这个道理,因为只用查API就可以快速实现算法
大一统!
全栈编译器(compiler stack)!
- 深度学习框架大一统的编译器:TVM (Tensor Virtual Machine)
作用是将不同深度学习框架上写的模型/计算图,映射到不同的硬件上(下图来自陈天奇在TVM Conference上的演讲
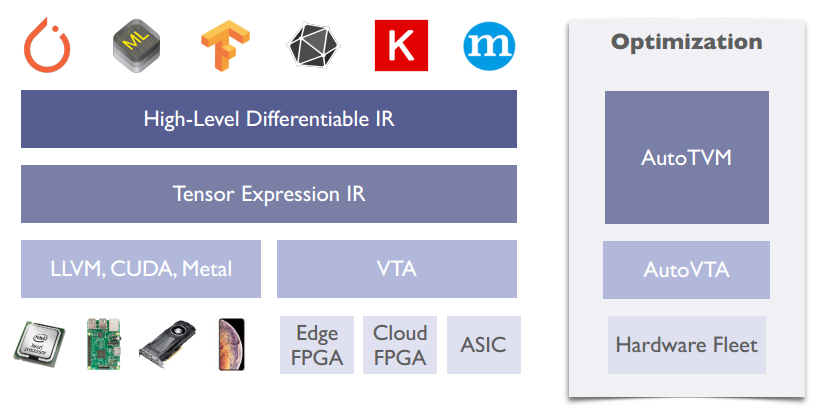
注意TVM并不是把整个框架映射到硬件上,而是将这些框架训练出来的模型映射到硬件上。 这里的模型其实就相当于算法。
前提是模型必须先训练(train)好,参数都已经固定,然后才可以通过TVM编译到不同硬件上跑推断(inference)[3]。
做法是在tensorflow或pytorch中save_model。
当然,现在TVM也在尝试将未训练的模型编译到硬件上进行训练(这要添加优化器),理论上也是可行的。
- 图框架大一统的编译器:Graph Virtual Machine… 这是一个无人涉足的领域…
TVM的思路是我现在有一堆深度学习模型,想要deploy到不同硬件上,那么就抽取这些模型的共同特征(计算图)统一进行优化,然后像llvm一样再分配到不同硬件上。
而对于图来说,我现在有一堆图算法,想要deploy到不同硬件上,那么就抽取这些算法的共同特征(算子)统一进行优化,然后再分配到不同硬件上。
说到编程语言…
深度学习界几乎没有人想要造一门新的DSL,猜想可能的原因:
- Python大法好!加上各种库已经非常强了
- 写Tensorflow几乎就在写一门新的语言…
这其实也说明DSL和框架的区别不是很大。
而图分析这边,CSAIL在2018年发布了GraphIt,比原有state-of-the-art的框架的性能高出几倍。
这则说明DSL和框架的区别还是有的,规范了语法语义(实际上是规范用户行为),就可以更方便更好地进行编译优化。
参考资料
- https://www.quora.com/What-is-the-difference-between-a-programming-language-and-a-framework
- https://stackoverflow.com/questions/24725562/domain-specific-language-dsl-vs-frameworks
- https://discuss.tvm.ai/t/dose-tvm-support-training-models/225
- http://composition.al/blog/2017/04/30/what-isnt-a-high-performance-dsl/