Hongzheng Chen Blog
Tensor Virtual Machine (TVM)
Feb 8th, 2019 0TVM与LLVM对比
- TVM (Tensor Virtual Machine, 2018):针对不同框架(前端),面向不同硬件(后端)
- LLVM (Low-Level Virtual Machine, 2003):针对不同语言(前端),面向不同硬件(后端),最核心部分为LLVM IR,提供模块化可重用的编译器和工具链技术,重点在于优化器
- Tapir 往LLVM添加了并行元素
TVM
TODO
VTA
简介
VTA (Versatile Tensor Accelerator)与TPU类似,是针对Tensor的硬件加速器
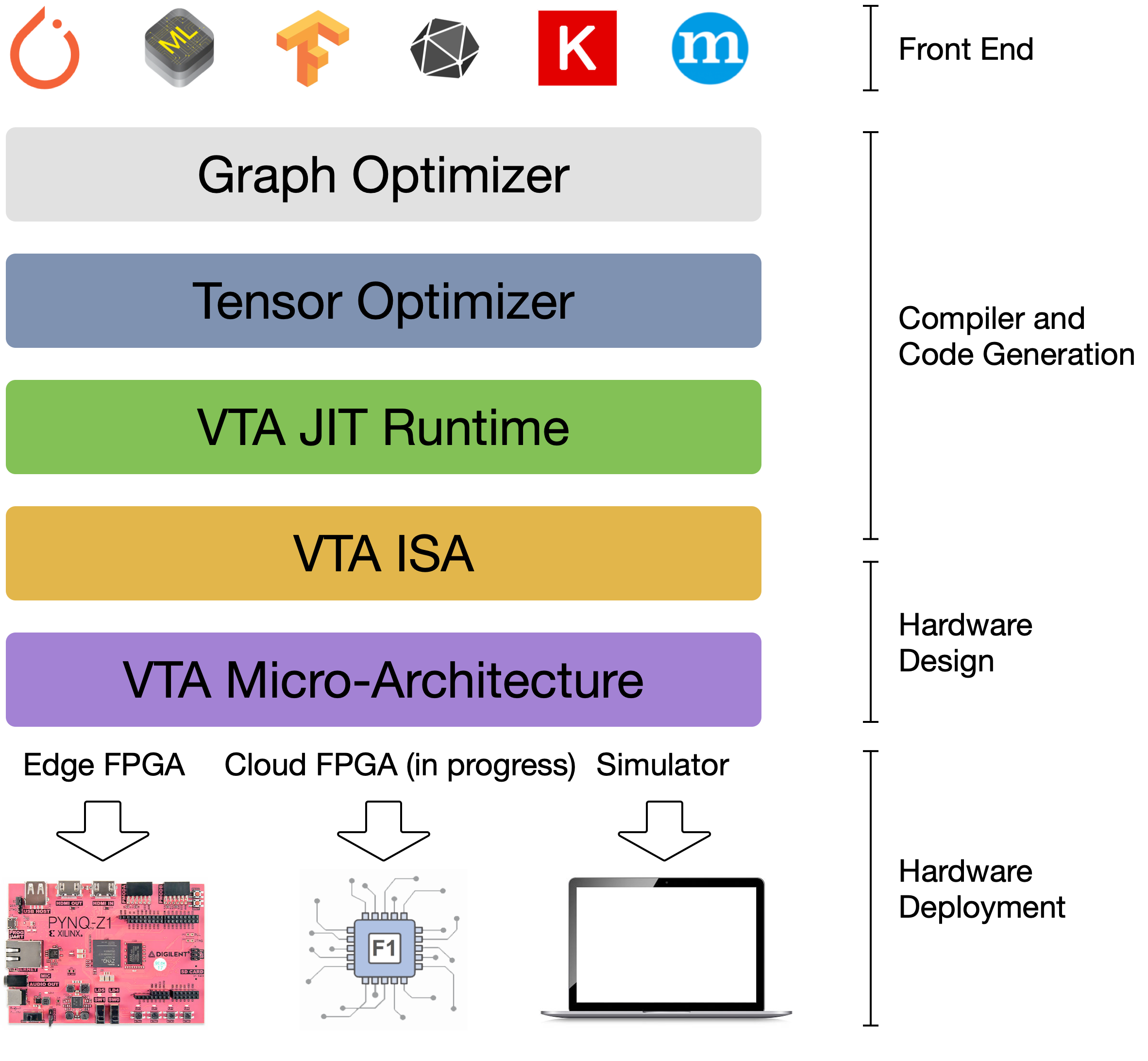
VTA全栈设计
- NNVM:graph优化
- TVM:tensor优化
- VTA JIT Runtime
- VTA ISA
- VTA Micro-Architecture
编译运行
VTA目前用C++写,然后通过Vivado HLS编译为比特流。
TVM调用VTA时将预先编译好的比特流写到板上,即目前TVM并不支持HLS直接由上层框架编译为Verilog。 而这个是由Pynq的特性决定的,可由Python直接编译上板,免去繁琐后端流程。
也就是说VTA已经将设计的部分解决,进而没HDL/HLS什么事;TVM要做的不过是进行任务调配,将计算任务调度到FPGA上即可。 关于设计与计算的差异可见高层次综合。
实际计算的编译流程如下
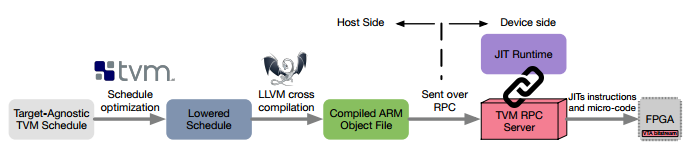
JIT Runtime实际上就类似于指令提取器(instruction fetcher),通过RPC控制DMA传输数据给FPGA
TVM的未来
TVM在2018年末开了第一届TVM会议,目前可以看到他们布的局已经很大了,相关方向的人都被他们请去演讲了。
现在看到比较有意思的talk:
- TVM Stack Overview – Tianqi Chen, UW
- VTA Open & Flexible Deep Learning Accelerator – Thierry Moreau, UW
- Spatial: A Language and Compiler for Application Accelerators – Kunle Olukotun/Raghu Prabhakar, Stanford & SambaNova
- PlaidML Stripe: Polyhedral IR + Model-guided Optimization – Brian Retford, Intel
- Relay: a high level differentiable IR – Jared Roesch, UW
- Build Your Own VTA Design with Chisel – Luis Vega, UW
- Supporting TVM on RISC-V Architectures – Jenq-Kuen Lee, NTHU, Taiwan
- AutoScheduler for TVM – Lianmin Zheng, SJTU
参考资料
- Tianqi Chen (UW), et al., TVM: An Automated End-to-End Optimizing Compiler for Deep Learning, OSDI, 2018
- Thierry Moreau (UW), et al., VTA: An Open Hardware-Software Stack for Deep Learning, arxiv:1807.04188v1, 2018
- Tao B. Schardl (MIT), et al., Tapir: Embedding Fork-Join Parallelism into LLVM’s Intermediate Representation, PPoPP best paper, 2017
- https://github.com/dmlc/tvm/issues/151
- Deep Learning的IR“之争” - 唐杉的文章 - 知乎 https://zhuanlan.zhihu.com/p/29254171