Hongzheng Chen Blog
分布式深度学习-基本概念
May 11th, 2019 0这篇文章在三年前就已经写过,但三年后深度学习的世界发生了翻天覆地的变化,越来越多大模型的出现使得分布式训练成为不可或缺的一部分。正好我现在也要进行相关的工作,因此还是重新整理更新一下内容,力求覆盖到领域的最新进展。本文将主要介绍三种基本的并行模式:数据并行、模型并行和流水线并行。
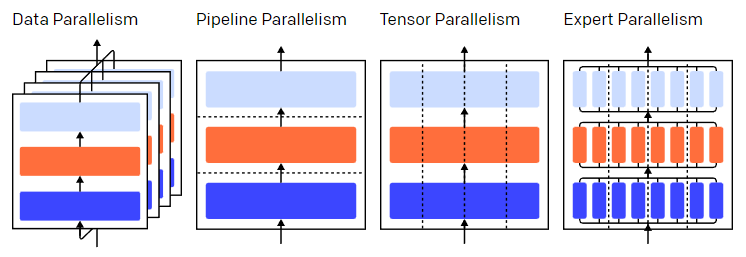
目前分布式学习的工作通常会将这三种并行模式统称为3D parallelism:
- 数据并行 (Data Parallelism)
- 模型/张量并行 (Model/Tensor Parallelism),注意这个术语在这几年的发展中产生了一些概念上的转变,现在其实人们所说的模型并行更多是指张量并行
- 流水线并行 (Pipeline Parallelism):理论上来讲也是模型并行的一种方式,只是在时间域上进行了设备的复用
数据并行 (Data Parallelism)
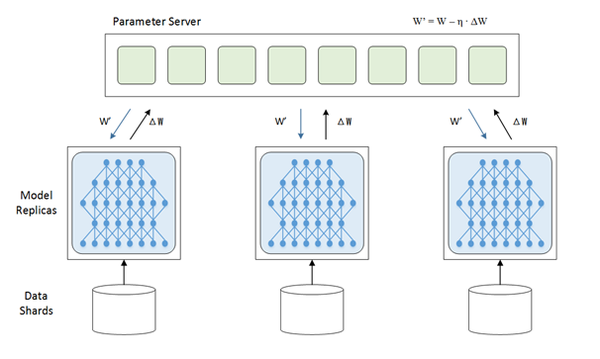
数据并行是在batch的维度上进行划分,将不同sub-batch分配到不同的设备上进行计算。一个典型的例子是参数服务器 (parameter server),每个设备存储同一份模型,然后不同的节点取不同的数据,各自完成前向和后向的梯度计算,这是worker干的事情。然后每一个worker将各自算得的梯度送到master即参数服务器上,由参数服务器进行更新操作,再将更新后的模型传回各个节点。
模型/张量并行 (Model/Tensor Parallelism)
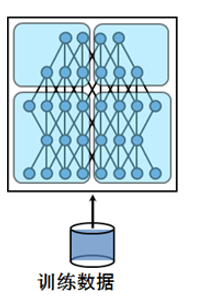
以前的模型并行是指将层划分到不同的设备上进行并行计算(如下图所示,最早被AlexNet采用);而现在的模型并行更多指张量并行,即对模型参数进行划分,参数分配到不同的设备上。
张量并行则涉及到不同的分片 (sharding)方法,现在最常用的都是1D分片,即将张量按照某一个维度进行划分(横着切或者竖着切)。后面也有更高维的分片方法,可参见尤洋的Colossal-AI。
Megatron-LM采用的则是非常直接的张量并行方式,对权重进行划分后放至不同GPU上进行计算。
流水线并行 (Pipeline Parallelism)
而流水线并行实际上也是模型并行的一种方式,最开始将不同层划分到不同GPU上后,完全可以在各阶段 (stage)串行执行的同时,在每一个新的时间步喂进一个新的数据,从而提升吞吐量。即每一个GPU上放一层(或某几层),然后依次传播。第一个数据读入(t1),由第一个GPU算第一层;第二个数据读入(t2),第一个GPU算第二个数据的第一层,第二个GPU算第一个数据的第二层,以此类推。
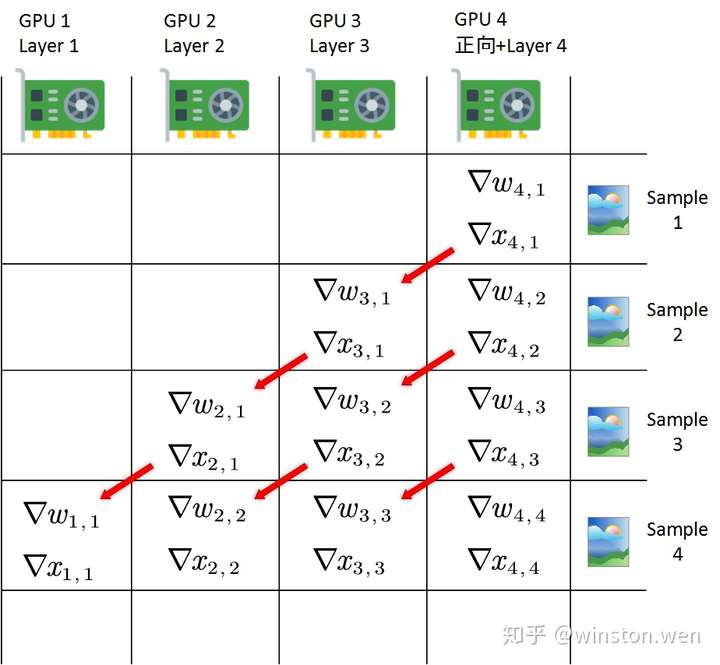
GPipe、PipeDream、1F1B等都是基于流水线并行的框架。
参考资料
- 分布式机器学习里的 数据并行 和 模型并行 各是什么意思? - 李哲龙的回答 - 知乎 https://www.zhihu.com/question/53851014/answer/158794752
- 深度学习的模型并行是什么原理? - winston.wen的回答 - 知乎 https://www.zhihu.com/question/55480951/answer/540737527
- https://openai.com/blog/techniques-for-training-large-neural-networks/
- https://colossalai.org/docs/concepts/paradigms_of_parallelism/