图表示学习(4)- 图神经网络加速器
这是图表示学习(representation learning)的第四部分——图神经网络加速器,主要涉及HyGCN [HPCA’20]和GraphACT [FPGA’20]两篇文章。
目前(截止至2020年3月10日),图神经网络加速器的文章共3篇,除了上述两篇还有DAC’20一篇尚未放出全文。
之所以大部分加速器都做成推理引擎,是因为推理端好做,只有前传的操作,不需要涉及到反向传播。
HyGCN1
GraphDynS[MICRO’19]2的原班人马,对GCN的抽象还是类似的
\[\begin{cases} a_v^{(k)}&=Aggregate(h_u^{(k-1)}:u\in\{N(v)\}\cup\{v\})\\\\ h_v^{(k)}&=Combine(a_v^{(k)}) \end{cases}\]主要针对无向图,推理过程,简单的MLP更新。
通过实验发现,对于大多数benchmark,Agg占据了90%以上的时间。
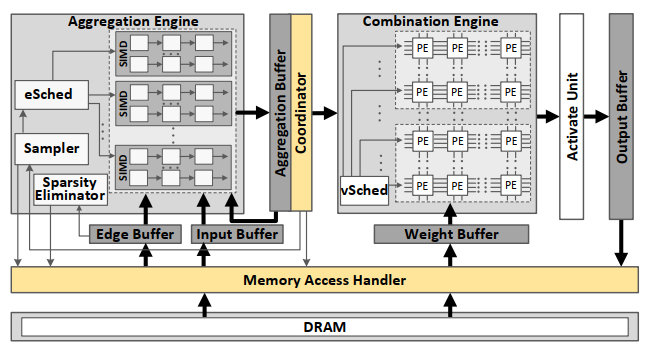
聚合部分采用了图计算的遍历引擎,更新部分则用了TPU非常经典的systolic array架构,充分发挥各自的优势(所谓的混合hybrid架构)。
实验在自研的模拟器上完成,用Verilog写RTL代码,并用Synopsys编译器以TSMC 12nm制程编译上模拟器。最大数据集为Reddit,0.23M个顶点,114M条边,602个特征,972MB大小。比较对象是PyG(但没有写版本号),工作站环境是2个Intel Xeon E5 CPU、1块Nvidia V100 GPU、378GB内存。实验结果比PyG-CPU快了1509x(PyG本来就没有开CPU的并行优化吧…),比PyG-GPU快了6.5x。
GraphACT3
Resources
- Fengbin Tu, Neural Networks on Silicon, https://github.com/fengbintu/Neural-Networks-on-Silicon
- Tutorial on hardware architectures for DNNs, http://eyeriss.mit.edu/tutorial.html
References
-
Mingyu Yan (ICT), Lei Deng, Xing Hu, Ling Liang, Yujing Feng, Xiaochun Ye, Zhimin Zhang, Dongrui Fan, and Yuan Xie (UCSB), HyGCN: A GCN Accelerator with Hybrid Architecture, HPCA, 2020 ↩
-
Mingyu Yan, Xing Hu, Shuangchen Li, Abanti Basak, Han Li, Xin Ma, Itir Akgun, Yujing Feng, Peng Gu, Lei Deng, Xiaochun Ye,, Zhimin Zhang, Dongrui Fan, and Yuan Xie, Alleviating Irregularity in Graph Analytics Acceleration: a Hardware/Software Co-Design Approach, MICRO, 2019 ↩
-
Hanqing Zeng, Viktor Prasanna (USC), GraphACT: Accelerating GCN Training on CPU-FPGA Heterogeneous Platforms, FPGA, 2020 ↩