Hongzheng Chen Blog
Pynq & Zynq SoC Tutorial
Jan 19th, 2021 0由于毕业论文打算进行FPGA加速器的设计,希望能够打通计算机系统栈从上到下的各个层次,因此本文将记录Ultra96-V2这款SoC的使用。
基本配置
Zynq SoC主要由processing system (PS)和programming logic (PL)两部分构成。
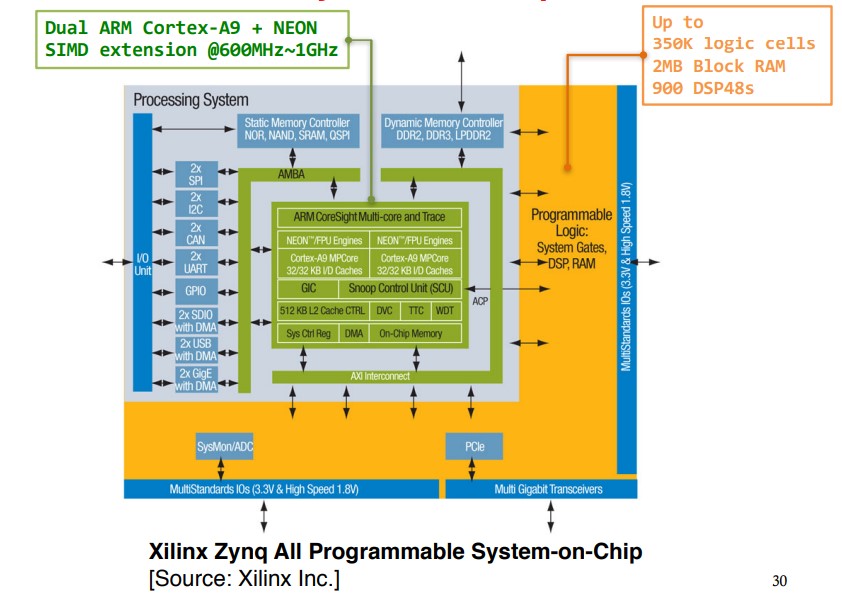
Arm通常被认为时处理系统(processing system, PS),用于支持软件程序或操作系统;而FPGA相当于可编程逻辑(programming logic, PL),用来实现高速逻辑、算术和数据流子系统。
其中的外设,也就是所谓的IP核(Intellectual Property),既可以从Xilinx的库中获得,又可从开源项目中得到,或者自己创造,最终集成起来形成系统设计。
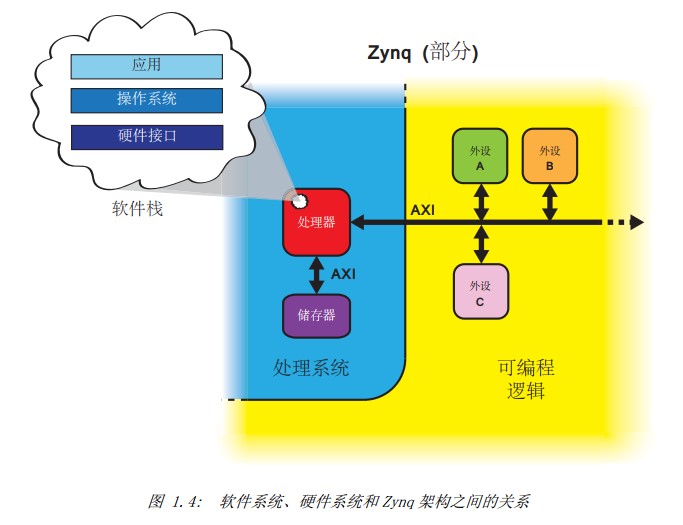
事实上,Zynq的处理系统里并非只有ARM处理器,还有一组相关的处理资源,形成一个应用处理器单元(Application Processing Unit, APU)
Ultra96 v2的基本配置如下,由于连接线没有提供,因此最好上淘宝购买【4.0x1.7mm 5V转12V升压线】和【USB转MicroUSB线】。
- Delkin 16 GB microSD card + adapter
- Micron 2 GB (512M x32) LPDDR4 Memory
- Xilinx Zynq UltraScale+ MPSoC ZU3EG A484
- Application Processor Unit (APU): Processor Core Quad-core ARM® Cortex™-A53 MPCore™ up to 1.5GHz
- Memory w/ECC L1 Cache 32KB I / D per core, L2 Cache 1MB, on-chip Memory 256KB
- Real-Time Processor Unit (RPU): Processor Core Dual-core ARM Cortex-R5 MPCore™ up to 600MHz
- Memory w/ECC L1 Cache 32KB I / D per core, Tightly Coupled Memory 128KB per core
- Application Processor Unit (APU): Processor Core Quad-core ARM® Cortex™-A53 MPCore™ up to 1.5GHz
Pynq
Pynq (Python productivity for Xilinx Zynq)目的是让开发者更易对嵌入式系统进行编程,而不用采用综合工具,通过以下三点实现:
- 可编程的逻辑电路都以硬件库(libraries)的形式呈现,称为覆盖(overlays)。软件工程师能够直接选择合适的覆盖来实现他们的应用,用API访问。尽管创造新的覆盖依然需要硬件知识,但是一旦完成,就可以被多次使用。
- Pynq用Python作为嵌入式处理器和覆盖的编程语言。
- Pynq开源,希望能够面向所有计算平台和操作系统,通过浏览器端(jupyter)实现。用Jupyter Notebook+局域网可建立起主机(host)和SoC之间的联系,方便编程与通信。
烧写SD卡
开机环境配置可参考Getting Started一文。
从Pynq官网下载Ultra96v2的镜像文件,解压出.img,并写入原装的Micro SD卡。如果SD卡里本来有东西,则需要先按照如下方式格式化、清除分区并烧写:
- 用Win+R打开cmd并输入
diskpart - 输入
list disk,查看所有磁盘,注意避免选错磁盘(16G SD卡显示应该为14G) - 依据大小选中对应磁盘
select disk x - 输入
clean删除所有分区 - Windows下用win32diskimage写入镜像文件
启动
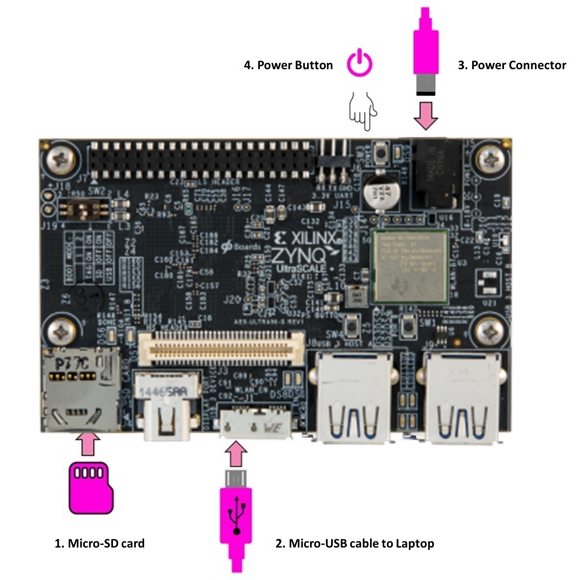
- 插入Micro-SD卡
- 插入USB线
- 插入电源线
- 按下SW4按钮开机
- USB串口会自动在电脑上安装驱动
- 在电脑上访问 http://192.168.3.1:9090 即可登入jupyter notebook
- 密码为xilinx
- 其他操作与正常的notebook一致
Overlay
自定义Overlay需要用Vivado HLS设计生成IP核,并烧写入FPGA的片上逻辑。
使用HLS设计IP核
参照Pynq官方文档,设计简单的加法器,下面为函数头文件及对应的testbench。
// kernel.h
#ifndef __KERNEL_H__
#define __KERNEL_H__
#include <ap_int.h>
#include <ap_fixed.h>
#include <hls_stream.h>
typedef ap_int<32> bit32;
typedef ap_uint<32> ubit32;
void test(int a, int b, int& c);
#endif
// main.cpp
#include "kernel.h"
void test(int a, int b, int& c) {
#pragma HLS INTERFACE ap_ctrl_none port=return
#pragma HLS INTERFACE s_axilite port=a
#pragma HLS INTERFACE s_axilite port=b
#pragma HLS INTERFACE s_axilite port=c
c = a + b;
}
// test.cpp
#include <iostream>
#include <cassert>
#include "kernel.h"
using namespace std;
int main() {
int a = 3;
int b = 2;
int c = 0;
test(a, b, c);
assert(c == 5);
cout << "Pass!" << endl;
}
同时将下面脚本放在同一目录下,调用vivado_hls -f run.tcl运行,会生成IP核。
(如果要执行cosim,可能需要设置一下编译器头文件,参见Vivado HLS in a Nutshell)
#########
# run.tcl
#########
# Project name
set hls_prj out.prj
# Open/reset the project
open_project ${hls_prj} -reset
# Top function of the design is "top"
set_top test
# Add design and testbench files
add_files main.cpp
add_files -tb test.cpp
open_solution "solution1"
# Use Zynq device
# set_part {xczu3eg-sbva484-1-e}
set_part {xczu3eg-sbva484-1-i} # ultra96-v2
# Target clock period is 10ns
create_clock -period 10
# Directives
############################################
# Simulate the C++ design
csim_design -O
# Synthesize the design
csynth_design
# Co-simulate the design
#cosim_design
# Implement the design
export_design -format ip_catalog
exit
在impl/misc/src/xtest_hw.h文件里可以查看各个端口的起始地址。
生成比特流
由于Vivado本身并不包含所有的FPGA板卡,因此需要先手动添加Ultra96-v2的描述文件,见此文及此文,即下面两条指令。
git clone https://github.com/Avnet/bdf
sudo cp -r bdf/ultra96v2 /tools/Xilinx/Vivado/2020.1/data/boards/board_files
- 打开Vivado,创建新RTL project(暂不添加source),添加板卡为ultra96-v2
- 点击Create Block Design
- 添加Zynq UltraScale+ MPSoC IP核
- 在Tools-Settings-IP-Repository中添加IP核的自定义目录,将整个HLS project文件夹添加进去即可,会自动检测出对应的IP核
- 在Block Design界面重新添加Test(因为上面HLS的top函数为test)的IP核,点击并更名为adder(记住名字,这在之后的Pynq中会用到)
- 点击Run Block Automation和Run Connection Automation
- 可能需要对Zynq的另一个时钟手动连线,与第一个时钟连在一起即可(或者再点一次Run Connection Automation)
- 右击Sources-Design Sources里的项目名,对该项目生成顶层HDL wrapper(会变成一个
.v文件) - 直接点Bitstream generation,会自动运行Synthesis和Implementation
- 将对应的
.tcl、.bit、.hwh文件拷贝出来,注意这几个文件都是必须的,尽管在Pynq读入overlay时只需指定bitstream的地址,但是其会自动检查其他相关文件- 回到block design页面,菜单File-Export-Export Block Design,得到
adder.tcl - 将生成的bitstream拷贝出来,
vivado/adder.runs/impl_1/design_1_wrapper.bit - 将生成的
.hwh文件拷贝出来,vivado/adder.srcs/sources_1/bd/design_1/hw_handoff/design_1.hwh
- 回到block design页面,菜单File-Export-Export Block Design,得到
可以利用下面的Makefile将必要的文件拷贝到当前目录下。
PROJECT_NAME = adder
copy:
cp out.prj/solution1/impl/misc/drivers/test_v1_0/src/xtest_hw.h xtest_hw.h
cp vivado/$(PROJECT_NAME).srcs/sources_1/bd/$(PROJECT_NAME)/hw_handoff/$(PROJECT_NAME).hwh $(PROJECT_NAME).hwh
cp vivado/$(PROJECT_NAME).runs/impl_1/$(PROJECT_NAME)_wrapper.bit $(PROJECT_NAME).bit
cp vivado/$(PROJECT_NAME).tcl $(PROJECT_NAME).tcl
在Pynq中导入overlay
将上述文件通过jupyter拷贝入SoC,创建一个新的notebook,然后就可以测试overlay是否正常运作了。(下面Overlay的初始化只需用到.bit和.hwh两个文件)
from pynq import Overlay
overlay = Overlay("base.bit")
在notebook中使用overlay?可以得到overlay的详细信息,用overlay.register_map可以看到所有端口信息。
add_ip = overlay.add # get module
# 1st method
# add_ip.register_map
add_ip.register_map.a = 3
add_ip.register_map.b = 4
add_ip.register_map.c # 7
# 2nd method
# check the address in the HLS-generated Verilog code
add_ip.write(0x10, 4)
add_ip.write(0x18, 5)
add_ip.read(0x20) # 9
如无意外,上述代码就可以通过FPGA的硬件电路执行了。
进阶
AXI端口
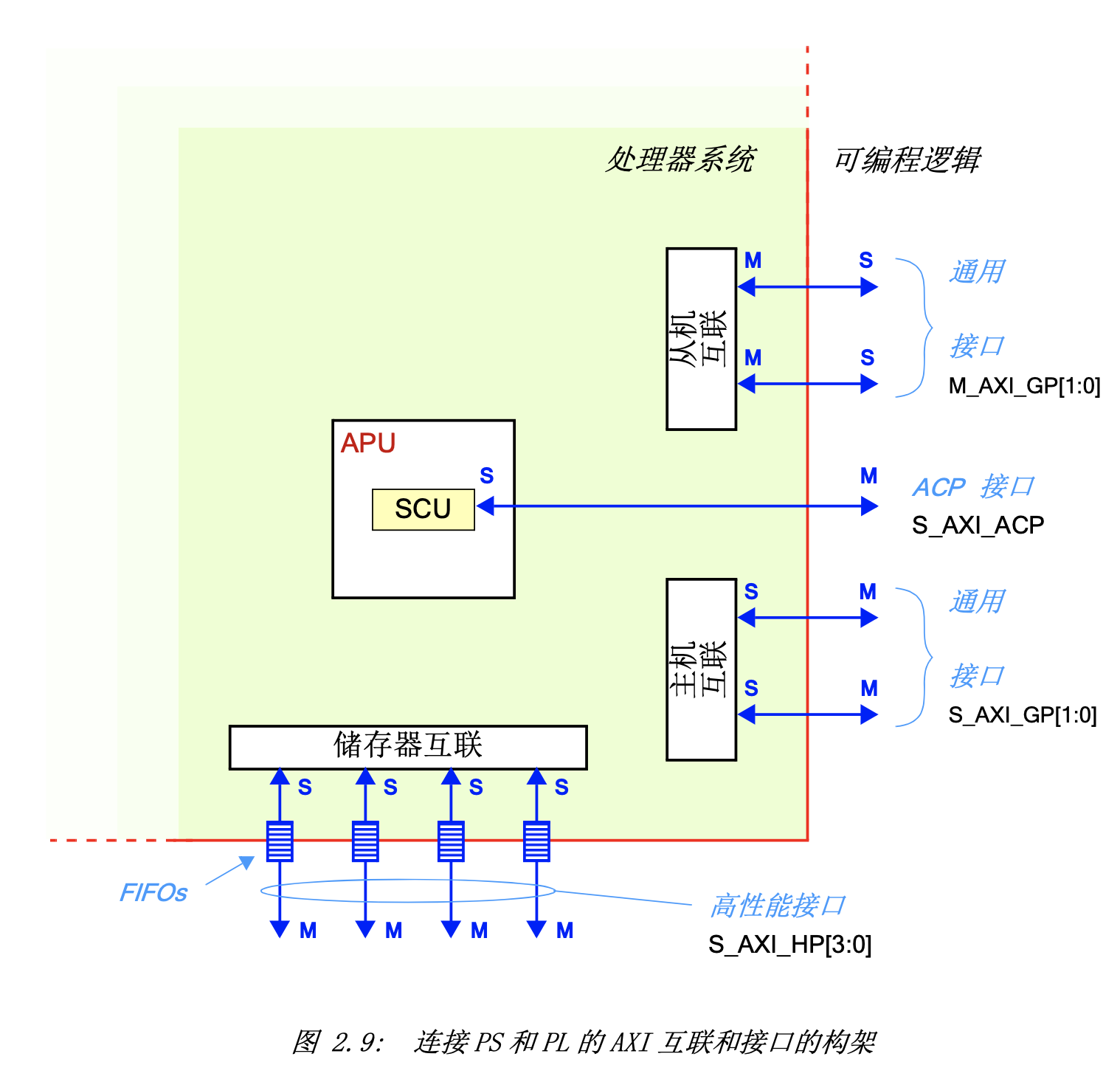
主机(Master, M)是控制总线并发起会话的,而从机(Slave, S)是做响应的。
向量传输
下面的程序将数组in_arr读入,加1后再放到out_arr中输出,使用MMIO (Memory-Mapped IO)的方式访问(PS与PL共用内存地址)。
注意HLS pragma的写法:
m_axi为主机AXI协议,可以传大量数据,但需要CPU进行控制。depth指明数据传输量,port指明变量名,offset=slave代表地址偏移量依次递增,bundle代表将哪些变量端口捆绑在一起,如果bundle名称相同,则说明这些变量共用同一个传输端口。s_axilite为从机AXI轻量协议,通常只能传简单的数据
#include <ap_int.h>
#include <ap_fixed.h>
#include <hls_stream.h>
typedef ap_int<32> bit32;
typedef ap_uint<32> ubit32;
void test(bit32 in_arr[10], bit32 out_arr[10]) {
#pragma HLS INTERFACE m_axi depth=10 port=in_arr offset=slave bundle=INPUT
#pragma HLS INTERFACE m_axi depth=10 port=out_arr offset=slave bundle=OUTPUT
#pragma HLS INTERFACE s_axilite register port=return bundle=CTRL
for (int i = 0; i < 10; ++i) {
#pragma HLS pipeline
out_arr[i] = in_arr[i] + 1;
}
}
经过Vivado HLS进行编译后,导出IP核。前面这一步跟之前的类似,关键在于下面Vivado内进行的Block Design (BD)。(不得不说,这一部分的相关教程几乎没有,因此我也是看了不少FPGA的设计范例才最终摸索出来应该怎么进行设计。)
主要步骤如下:
- 搜索添加Zynq IP核(刚添加时只有下图中Zynq UltraScale+ MPSoC的模块)
- 添加HLS project路径后,搜索添加刚生成的HLS IP。由于我们的top函数为test,因此生成出来的模块就叫Test。然后点击该IP,左侧会出现Block Properties一栏,修改名称为
test,这是后面Pynq导入时需要用到的名称。观察该IP核可以看到,我们在HLS里的输入端口INPUT被综合成了AXI端口m_axi_INPUT_r,而输出端口OUTPUT被综合成m_axi_OUTPUT_r,控制端口则是s_axi_CTRL。 - (重要!)添加两个AXI Smart Connecter,命名为
axi_smc_0和axi_smc_1,并双击将slave端口数目改为1,作为与PS(Zynq)通信的中转模块,分别手动连线。在连线前还需双击Zynq IP,调出2个高性能通信端口S_AXI_HPx_FPD。m_axi_INPUT_r连接第一个SMC的输入端,第一个SMC的输出端连接PS的S_AXI_HP0_FPD,同理第二个SMC。(这一步也是我一开始没有做的,导致有部分输出端口闲置,功能不完善) - 手动将重要的线连接后即可交由自动化程序将剩余工作完成,点击Run Block Automation和Run Connection Automation,可能后者需要执行两次。
- 最终可以获得完整的模块设计图,如下参考。

后段综合步骤与adder的设计相同,在此不再赘述。导出.hwh、.tcl、.bit文件,传到板上。
接下来是Pynq的部署,首先需要查看HLS生成的硬件端口偏移地址,参见xtest_hw.h。
0x00主要是控制信号,第0位用来控制整个模块的启动与终止,对应bd里PS的外围设备ps8_0_axi_periph中的M00_AXI及PL的s_axi_CTRL端口,也即说明了控制命令的流动。0x10和0x18则是两个数据输入输出端口,对应bd的m_axi_INPUT_r和m_axi_OUTPUT_r,用于传输PS内存地址,也即PL执行时会到这两个地址去读写数据。
// ==============================================================
// Vivado(TM) HLS - High-Level Synthesis from C, C++ and SystemC v2020.1.1 (64-bit)
// Copyright 1986-2020 Xilinx, Inc. All Rights Reserved.
// ==============================================================
// CTRL
// 0x00 : Control signals
// bit 0 - ap_start (Read/Write/COH)
// bit 1 - ap_done (Read/COR)
// bit 2 - ap_idle (Read)
// bit 3 - ap_ready (Read)
// bit 7 - auto_restart (Read/Write)
// others - reserved
// 0x04 : Global Interrupt Enable Register
// bit 0 - Global Interrupt Enable (Read/Write)
// others - reserved
// 0x08 : IP Interrupt Enable Register (Read/Write)
// bit 0 - Channel 0 (ap_done)
// bit 1 - Channel 1 (ap_ready)
// others - reserved
// 0x0c : IP Interrupt Status Register (Read/TOW)
// bit 0 - Channel 0 (ap_done)
// bit 1 - Channel 1 (ap_ready)
// others - reserved
// 0x10 : Data signal of in_arr_V
// bit 31~0 - in_arr_V[31:0] (Read/Write)
// 0x14 : reserved
// 0x18 : Data signal of out_arr_V
// bit 31~0 - out_arr_V[31:0] (Read/Write)
// 0x1c : reserved
// (SC = Self Clear, COR = Clear on Read, TOW = Toggle on Write, COH = Clear on Handshake)
#define XTEST_CTRL_ADDR_AP_CTRL 0x00
#define XTEST_CTRL_ADDR_GIE 0x04
#define XTEST_CTRL_ADDR_IER 0x08
#define XTEST_CTRL_ADDR_ISR 0x0c
#define XTEST_CTRL_ADDR_IN_ARR_V_DATA 0x10
#define XTEST_CTRL_BITS_IN_ARR_V_DATA 32
#define XTEST_CTRL_ADDR_OUT_ARR_V_DATA 0x18
#define XTEST_CTRL_BITS_OUT_ARR_V_DATA 32
Python执行完整代码如下。注意之前的参考样例会使用Xlnk来分配内存地址,但是Pynq官方说这个特性将会在后面的版本中被废除,因此下面采用的是allocate方法。
from pynq import allocate
from pynq import Overlay
import numpy as np
import time
# 1. Allocate memory on PS
in_arr = allocate(shape=(10,),dtype=np.int32)
out_arr = allocate(shape=(10,),dtype=np.int32)
# 2. Initialize numpy array
np_in = np.array([-3,-1,1,3,5,7,9,11,13,15],dtype=np.int32)
np_out = np.zeros((10,), dtype=np.int32)
# 3. Copy data to the allocated location
np.copyto(in_arr,np_in)
np.copyto(out_arr,np_out)
# 4. Load in overlay
overlay = Overlay("axi_test.bit")
print("Bitstream loaded")
ip = overlay.test # this name is that specified in block design
# 5. Tell PL the allocated address on PS
ip.write(0x10, in_arr.device_address) # check HLS generated file
ip.write(0x18, out_arr.device_address)
# As another method, using register_map to set address is also allowed
# 6. Start execution
ip.write(0x00, 0x1)
isready = ip.read(0x00)
while (isready == 1): # wait PL to finish
isready = ip.read(0x00)
# 7. Read results
np.copyto(np_out,out_arr)
# 8. Test final results
correct_res = np.array([-2,0,2,4,6,8,10,12,14,16],dtype=np.int32)
print(np.array_equal(np_out,correct_res))
最终输出结果为True就证明完整的Pynq流程跑通啦!
直接内存访问 (Direct Memory Access, DMA)
DMA相比起MMIO则是一种更加高效的内存访问方式,不需要CPU介入,但需要引入额外的IP核。
先在HLS头文件中定义数据结构如下(axis_t也包含在<ap_axi_sdata.h>头文件中,但亲测不太奏效,会导致DMA永远在等待),注意除了data,还需要有一个控制信号last,用于写入DMA时告诉DMA是否是最后一个元素。last信号会被HLS自动识别并综合为后端硬件可识别的代码。
struct axis_t{
ap_int<32> data;
ap_int<1> last;
};
同时可以添加模版函数,方便读写操作。hls::stream为<hls_stream.h>中的模版,专门用来做流数据传输(虽然数组也可以做,但是在cosim阶段没有办法识别死锁等错误)。
template<class T>
inline void axis_read(hls::stream<axis_t>& in_arr, T* out_arr, std::size_t size) {
for (int i = 0; i < size; ++i) {
#pragma HLS loop_tripcount max=10
axis_t tmp = in_arr.read();
out_arr[i] = tmp.data;
}
}
template<class T>
inline void axis_write(T* in_arr, hls::stream<axis_t>& out_arr, std::size_t size) {
for (int i = 0; i < size; ++i) {
#pragma HLS loop_tripcount max=10
axis_t tmp;
tmp.data = in_arr[i];
if (i == size - 1)
tmp.last = 1; // be careful
else
tmp.last = 0;
out_arr.write(tmp);
}
}
主函数如下,axis即为AXI流(stream)数据传输,注意hls::stream要通过传引用方式传递。
void test(hls::stream<axis_t>& in_stream, hls::stream<axis_t>& out_stream) {
#pragma HLS INTERFACE axis port=in_stream bundle=INPUT
#pragma HLS INTERFACE axis port=out_stream bundle=OUTPUT
#pragma HLS INTERFACE s_axilite register port=return bundle=CTRL
int in_arr[10];
int out_arr[10];
axis_read<int>(in_stream, in_arr, 10);
for (int i = 0; i < 10; ++i) {
#pragma HLS pipeline
out_arr[i] = in_arr[i] + 1;
}
axis_write<int>(out_arr, out_stream, 10);
}
然后就可以通过Vivado HLS综合并导出IP核,再从Vivado中导入进行block design。
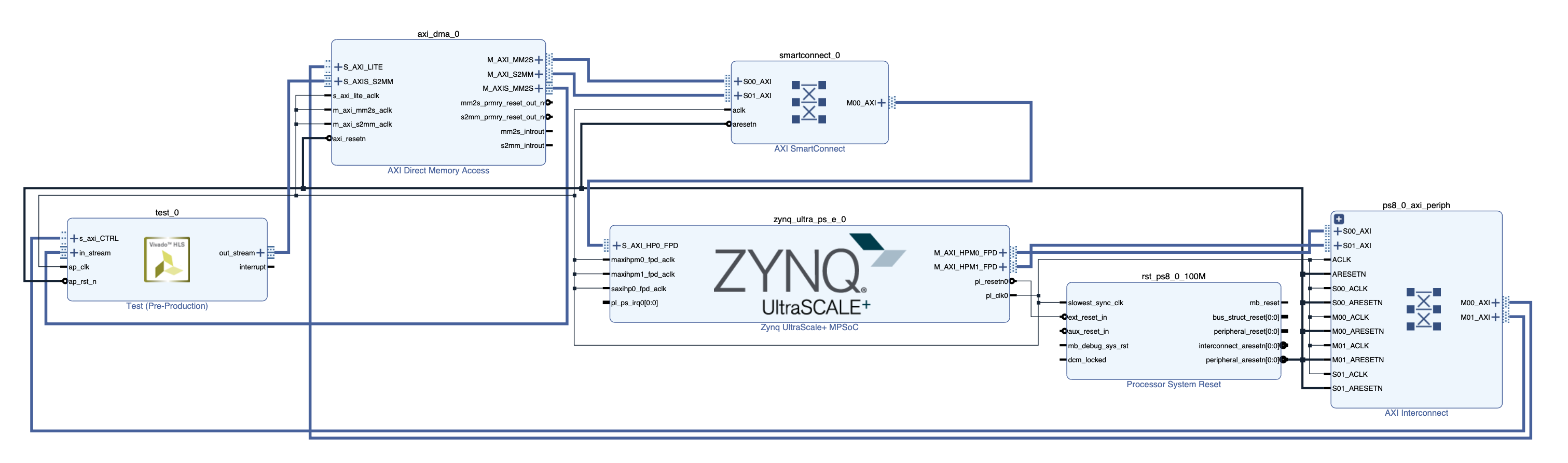
需要手动配置的几个点:
- 把AXI DMA IP核中的Enable Scatter Gather Engine给去掉,即去除右端无用的端口显示
- 每个AXI DMA IP有一进一出的读写端口,
S_AXI_LITE为控制端口S_AXIS_S2MM连接自定义IP核的输出,M_AXIS_MM2S连接自定义IP核的输入端M_AXI_MM2S和M_AXI_S2MM连接AXI SMC,再(自动)连入PS
- 将Zynq的
S_API_HP0_FPD调出来,用于DMA IP的连接
后端综合后,可按以下步骤在pynq内部署运行。
from pynq import allocate
from pynq import Overlay
import numpy as np
import time
in_arr = allocate(shape=(10,),dtype=np.int32)
out_arr = allocate(shape=(10,),dtype=np.int32)
np_in = np.array([-3,-1,1,3,5,7,9,11,13,15],dtype=np.int32)
np_out = np.zeros((10,), dtype=np.int32)
np.copyto(in_arr,np_in)
np.copyto(out_arr,np_out)
overlay = Overlay("dma_test.bit")
print("Bitstream loaded")
ip = overlay.test_0
# dma data transfer
dma = overlay.axi_dma_0
dma.sendchannel.transfer(in_arr)
dma.recvchannel.transfer(out_arr)
# start execution
ip.write(0x00, 0x1)
isready = ip.read(0x00)
while (isready == 1):
isready = ip.read(0x00)
# finally wait for ending
dma.sendchannel.wait()
dma.recvchannel.wait()
print("Done transfering data")
print(out_arr)
注意DMA数据传输及等待的顺序,需要开始执行,最后才wait。
出现的问题
一般csim和cosim没有问题,就要想想是不是deploy出了问题
- 执行后
0x00一直不变为0- 连线问题
- 传输进空数组
- 看看是不是
tlast=1后还有数据在传输
dma.recvchannel.wait()一直在等待:注意需要按照上面代码段的执行顺序,先传完数据,开始执行,最后再等待- 结果浮点数值不正确:pynq中使用numpy时记得声明类型,不能是
np.float,而要写np.float32,似乎是编码方式不太一样 - 死循环:while/if
- 写pynq buffer崩溃:逐个逐个写以避免,同时注意最后一个元素
参考资料
- https://github.com/jgoeders/dac_sdc_2020
- http://zedboard.org/sites/default/files/documentations/Ultra96-V2-GSG-v1_1.pdf
- https://www.fpgadeveloper.com/2018/03/create-a-custom-pynq-overlay-for-pynq-z1.html/
- The Zynq Book, http://www.zynqbook.com/, Chinese edition
参考范例
- Pynq Community
- Matmul Tutorial (Pynq Z1)
- Pynq Accelerator
- Pynq HLS Tutorial
- SkyNet
- FracBNN
- Pynq-HelloWorld
- SpMV
关于DMA实现
- Q&A: Load data to IP via DMA
- How to write an IP with an array as a parameter to a function
- [hls::stream
with tlast](https://forums.xilinx.com/t5/High-Level-Synthesis-HLS/hls-stream-lt-data-t-gt-with-tlast/td-p/683836) - Implementation and Significance of TLAST in AXI-Stream Interface
- Pynq DMA