Hongzheng Chen Blog
HLS Examples
Jun 5th, 2021 0本文记录HLS的一些优化实例,摘自PP4FPGA一书。
有限冲击响应(Finite Impulse Response, FIR)
相当于1D卷积,N-tap的FIR为
\[y[i]=\sum_{j=0}^{N-1}h[j]\cdot x[i-j]\]其中$h$为系数,$x$为输入信号
优化策略:
- 循环分裂(fission),将
shift_reg和累加acc拆开成两个循环,可以各自做优化 - 循环展开(unroll),将累加拆成4个并行数组访问共同读,注意补边界情况
- 循环流水(pipeline)
- 读操作需要2个时钟周期,第1个时钟读地址,第2个时钟读数据
- 在每个循环开始前会占用1个时钟周期来判断是否满足循环条件,但由于latency算的是操作之间寄存器数目,因此时钟周期又会减去1
稀疏矩阵向量乘(SpMV)
void spmv(int rowPtr[NUM ROWS+1], int columnIndex[NNZ],
DTYPE values[NNZ], DTYPE y[SIZE], DTYPE x[SIZE])
{
L1: for (int i = 0; i < NUM ROWS; i++) {
DTYPE y0 = 0;
L2: for (int k = rowPtr[i]; k < rowPtr[i+1]; k++) {
#pragma HLS unroll factor=8
#pragma HLS pipeline
y0 += values[k] ∗ x[columnIndex[k]];
}
y[i] = y0;
}
}
- cosim可以给出不规则循环的迭代次数
- 部分展开,同时将跨循环依赖的变量拉出来单独算,即缩短critical path
- 下面给出了例子,但每个L2循环都可能做冗余计算
const static int S = 7;
void spmv(int rowPtr[NUM ROWS+1], int columnIndex[NNZ],
DTYPE values[NNZ], DTYPE y[SIZE], DTYPE x[SIZE])
{
L1: for (int i = 0; i < NUM ROWS; i++) {
DTYPE y0 = 0;
L2_1: for (int k = rowPtr[i]; k < rowPtr[i+1]; k += S) {
#pragma HLS pipeline II=S
DTYPE yt = values[k] ∗ x[columnIndex[k]];
L2_2: for(int j = 1; j < S; j++) {
if(k+j < rowPtr[i+1]) {
yt += values[k+j] ∗ x[columnIndex[k+j]];
}
}
y0 += yt;
}
y[i] = y0;
}
}
前缀和
\(out_{n}=out_{n-1}+in_n\)
基本实现in和out均需2个时钟周期进行读操作,因此pipeline出来的II=2
#define SIZE 128
void prefixsum(int in[SIZE], int out[SIZE]) {
out[0] = in[0];
for(int i = 1; i < SIZE; i++) {
#pragma HLS PIPELINE
out[i] = out[i−1] + in[i];
}
}
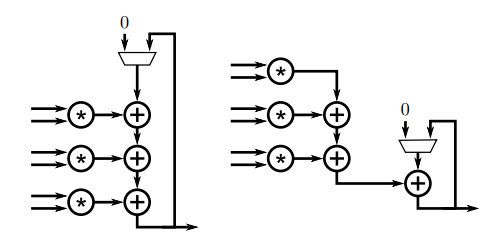
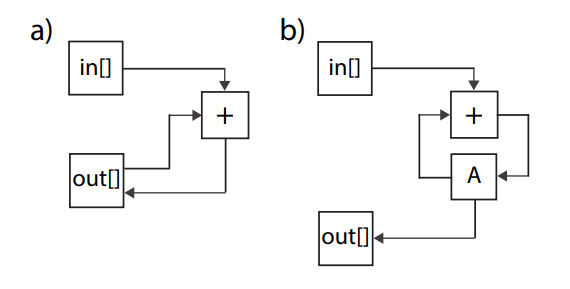
这里II没法为1的原因在于需要从数组中读取前面一次的值,因此可以通过采用单独的局部变量(寄存器)进行累加来避免这样的问题。
#define SIZE 128
void prefixsum(int in[SIZE], int out[SIZE]) {
int A = in[0];
for(int i = 1; i < SIZE; i++) {
#pragma HLS PIPELINE
A = A + in[i];
out[i] = A;
}
}
上面两个代码对应的流程图如下,可以见到critical path变短了。
直方图(Histogram)
void histogram(int in[INPUT SIZE], int hist[VALUE SIZE]) {
int val;
for(int i = 0; i < INPUT SIZE; i++) {
#pragma HLS PIPELINE
val = in[i];
hist[val] = hist[val] + 1;
}
}
可以通过更改数据集预设条件,从而达到II=1
// Precondition: hist[] is initialized with zeros.
// Precondition: for all x, in[x] != in[x+1]
void histogram(int in[INPUT SIZE], int hist[VALUE SIZE]) {
#pragma HLS DEPENDENCE variable=hist inter RAW distance=2
int val;
int old = −1;
for(int i = 0; i < INPUT SIZE; i++) {
#pragma HLS PIPELINE
val = in[i];
assert(old != val);
hist[val] = hist[val] + 1;
old = val;
}
}
显然上述的precondition太强了,事实上我们可以直接在代码中体现两种不同情况,只有当前一循环写入的位置与当前循环写入的位置相同才存在依赖关系,此时可以用局部变量来进行累加,避免不必要的内存访问。
void histogram(int in[INPUT SIZE], int hist[VALUE SIZE]) {
int acc = 0;
int i, val;
int old = in[0];
#pragma HLS DEPENDENCE variable=hist intra RAW false
for(i = 0; i < INPUT SIZE; i++) {
#pragma HLS PIPELINE II=1
val = in[i];
if(old == val) {
acc = acc + 1;
} else {
hist[old] = acc;
acc = hist[val] + 1;
}
old = val;
}
hist[old] = acc;
}
采用MapReduce方案,可以进一步提升并行度
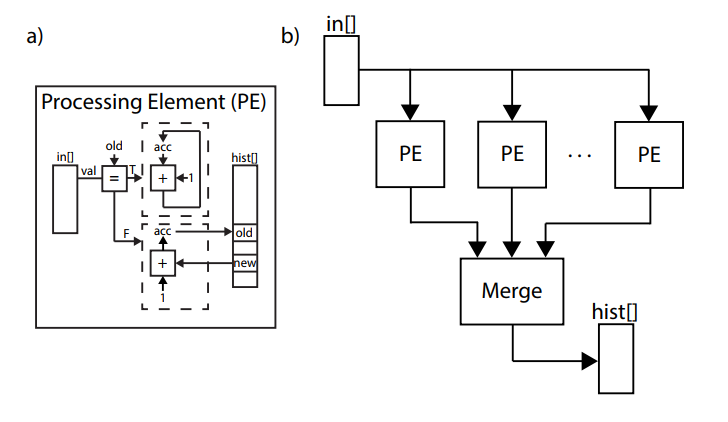
void histogram_map(int in[INPUT SIZE/2], int hist[VALUE SIZE]) {
#pragma HLS DEPENDENCE variable=hist intra RAW false
for(int i = 0; i < VALUE SIZE; i++) {
#pragma HLS PIPELINE II=1
hist[i] = 0;
}
int old = in[0];
int acc = 0;
for(int i = 0; i < INPUT SIZE/2; i++) {
#pragma HLS PIPELINE II=1
int val = in[i];
if(old == val) {
acc = acc + 1;
} else {
hist[old] = acc;
acc = hist[val] + 1;
}
old = val;
}
hist[old] = acc;
}
void histogram_reduce(int hist1[VALUE SIZE], int hist2[VALUE SIZE], int output[VALUE SIZE]) {
for(int i = 0; i < VALUE SIZE; i++) {
#pragma HLS PIPELINE II=1
output[i] = hist1[i] + hist2[i];
}
}
//Top level function
void histogram(int inputA[INPUT SIZE/2], int inputB[INPUT SIZE/2], int hist[VALUE SIZE])f
#pragma HLS DATAFLOW
int hist1[VALUE SIZE];
int hist2[VALUE SIZE];
histogram_map(inputA, hist1);
histogram_map(inputB, hist2);
histogram_reduce(hist1, hist2, hist);
}
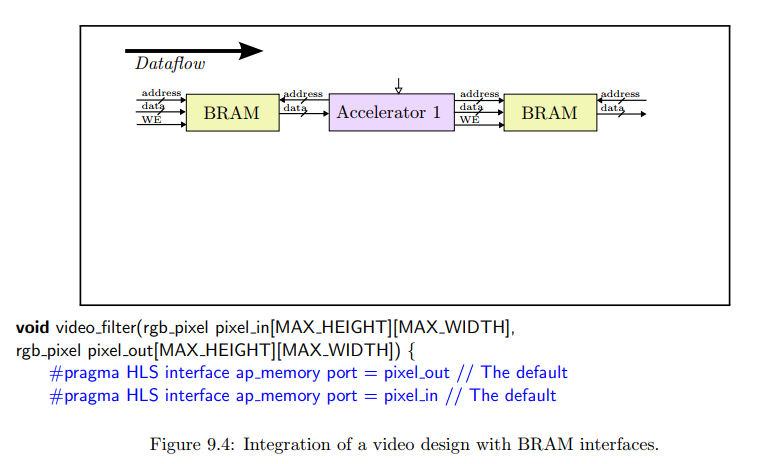
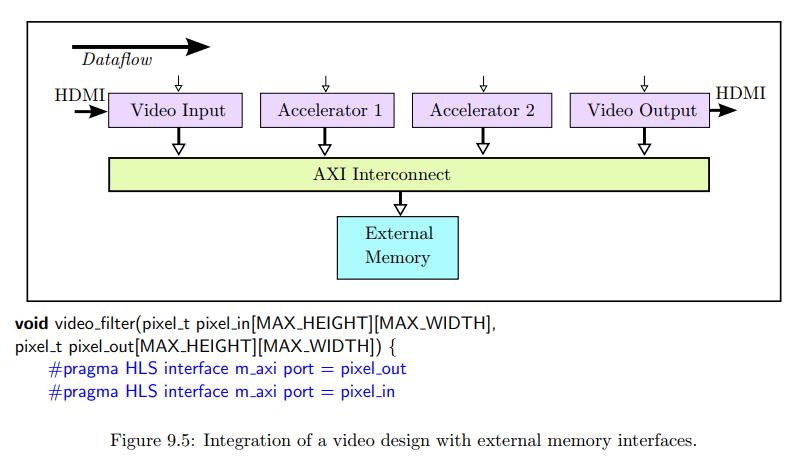
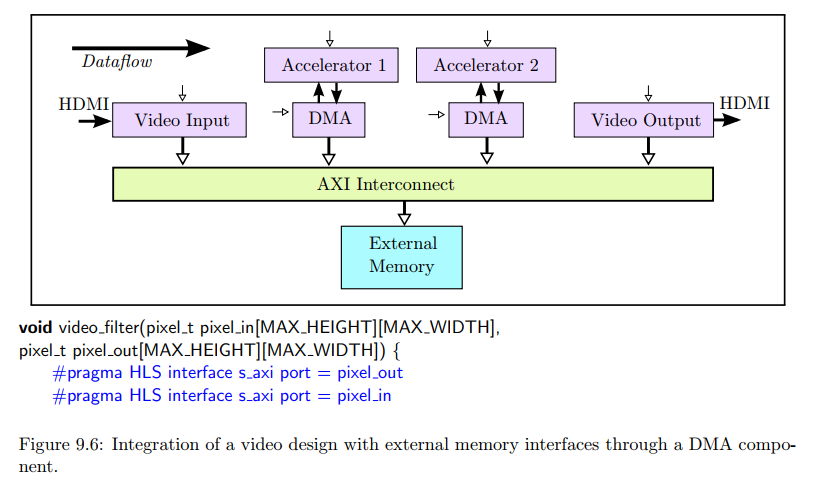
Video Systems