Hongzheng Chen Blog
NSDI'23 Attendence Summary
Apr 17th, 2023 0NSDI’23, a conference focused on networked systems design and implementation, was held in late April in Boston, MA. Thanks to my paper on a GNN system that I worked on during my undergraduate internship at ByteDance, I was fortunate enough to receive the USENIX travel grant to attend the conference. While I did not have the opportunity to review all of the papers beforehand, I will provide summaries of the sessions that I attended in this post.
Learning with GPUs (9:10 am–10:30 am)
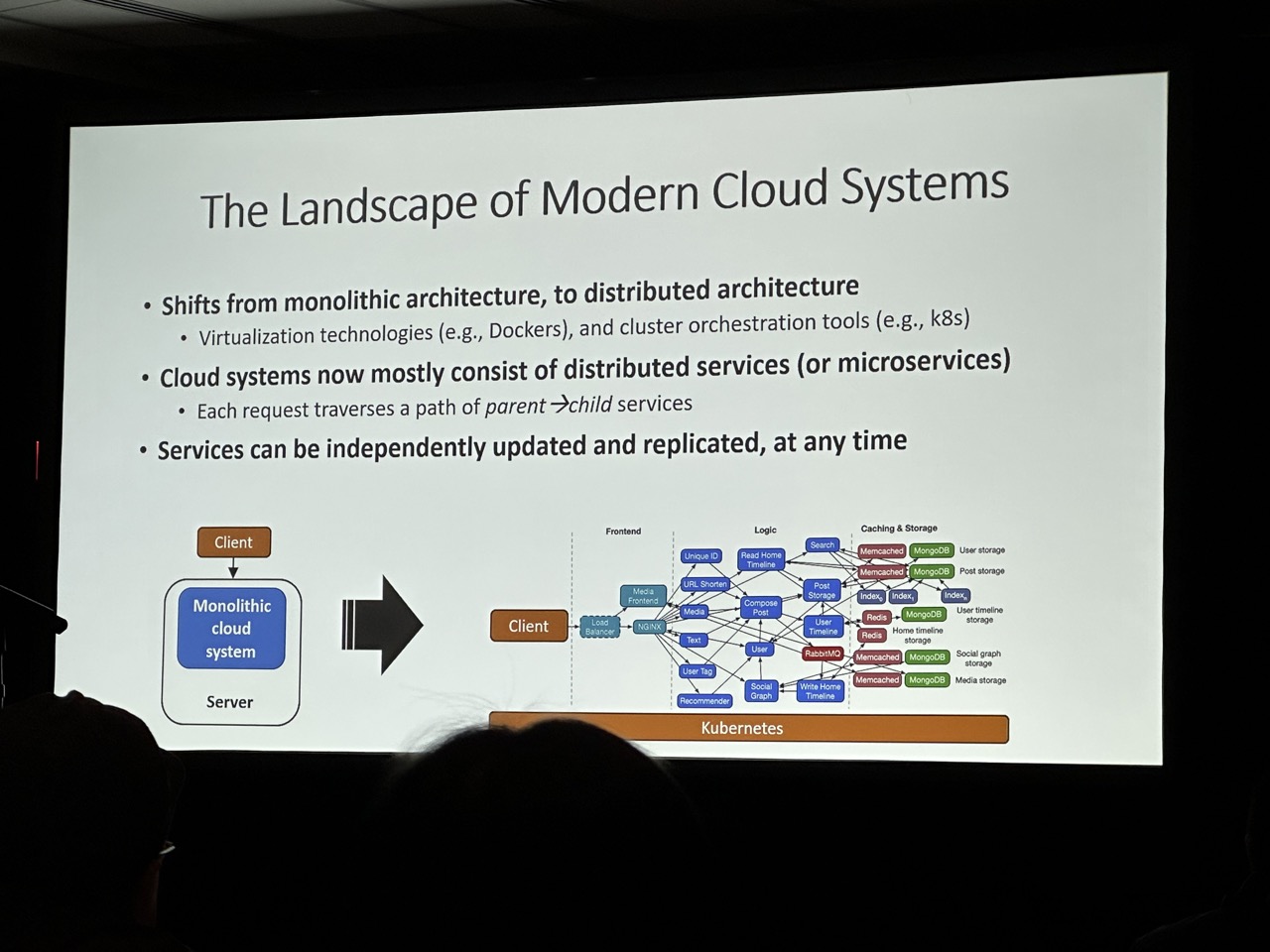
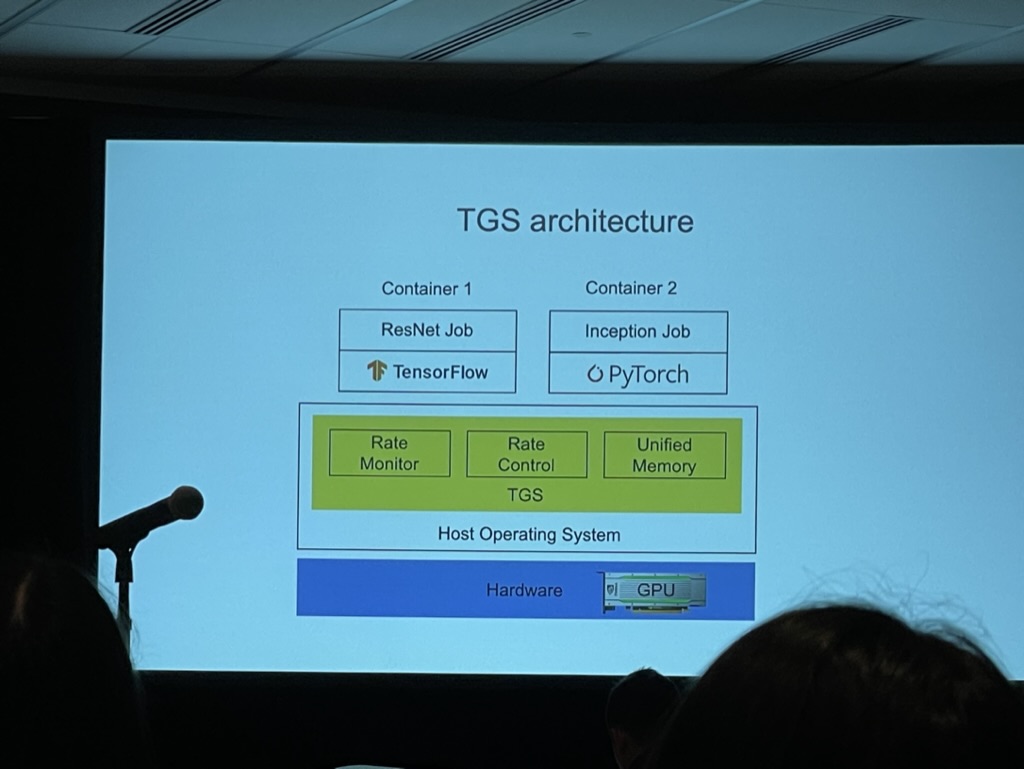
Transparent GPU Sharing in Container Clouds for Deep Learning Workloads
Bingyang Wu and Zili Zhang, Peking University; Zhihao Bai, Johns Hopkins University; Xuanzhe Liu and Xin Jin, Peking University
https://www.usenix.org/conference/nsdi23/presentation/wu
- Low utilization: The container may monopolize the GPU.
- GPU sharing
- Application solution: AntMan [OSDI’20] -> require modifying the DL framework, lack of transparency
- OS-layer solution: NVIDIA MPS, MIG -> low utilization, performance isolation

ARK: GPU-driven Code Execution for Distributed Deep Learning
Changho Hwang, KAIST, Microsoft Research; KyoungSoo Park, KAIST; Ran Shu, Xinyuan Qu, Peng Cheng, and Yongqiang Xiong, Microsoft Research
https://www.usenix.org/conference/nsdi23/presentation/hwang
Mainly reduce the memory access overhead from GPU.


BGL: GPU-Efficient GNN Training by Optimizing Graph Data I/O and Preprocessing
Tianfeng Liu, Tsinghua University, Zhongguancun Laboratory, ByteDance; Yangrui Chen, The University of Hong Kong, ByteDance; Dan Li, Tsinghua University, Zhongguancun Laboratory; Chuan Wu, The University of Hong Kong; Yibo Zhu, Jun He, and Yanghua Peng, ByteDance; Hongzheng Chen, ByteDance, Cornell University; Hongzhi Chen and Chuanxiong Guo, ByteDance
This work is from my ByteDance group, and I am fortunate to be part of the team. I think the optimizations we made are very intuitive. We mainly consider sampling-based GNNs. Our findings showed that not only does accessing the graph structure contribute significantly to the final performance, but access to node features can also degrade performance. Since graph features are typically large and stored on remote CPU machines, we implemented a dynamic cache engine on the GPU to avoid repeated reads, and a simple cache replacement policy for the features.
To ensure locality of the graph structure, we developed a partition algorithm to split the graph across multiple machines. However, we encountered a tricky issue as locality and randomness can conflict, and changing the way we sample the graph can affect accuracy. To address this, we came up with a simple algorithm that generates BFS sequences (for locality) and shuffles them (for randomness) to ensure both are maintained.
Lastly, different stages may have contention that makes the pipeline stall, so we need to balance those stages. We create an ILP model and solve it optimally to allocate those resources.
More details can be found in our paper.
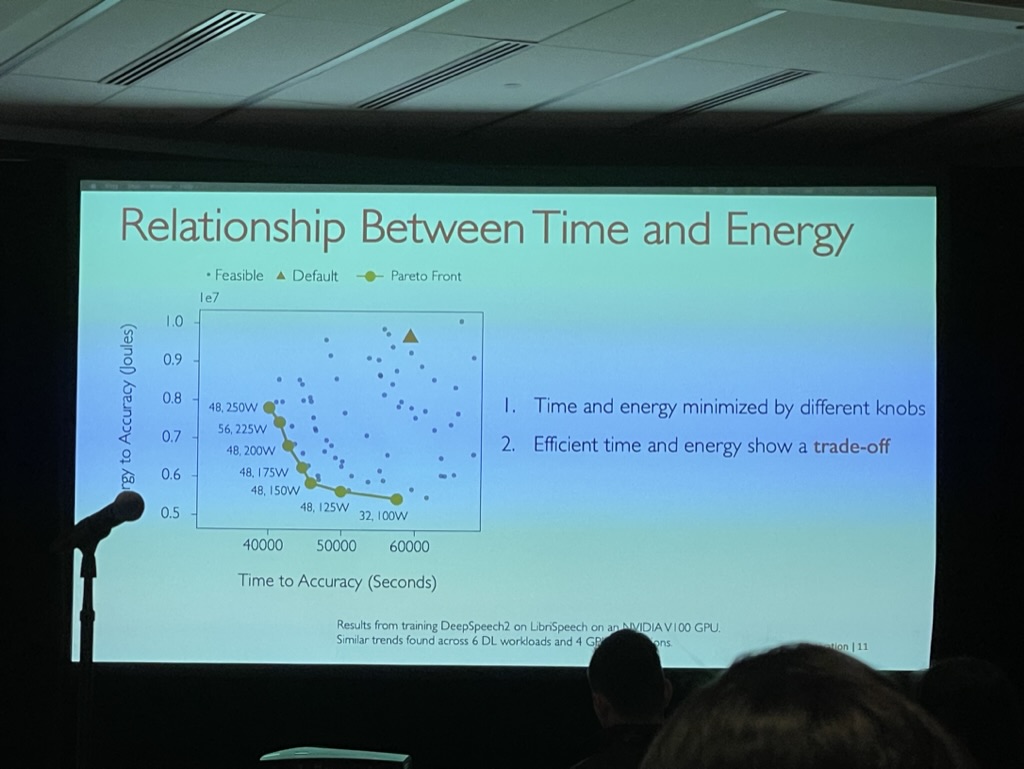
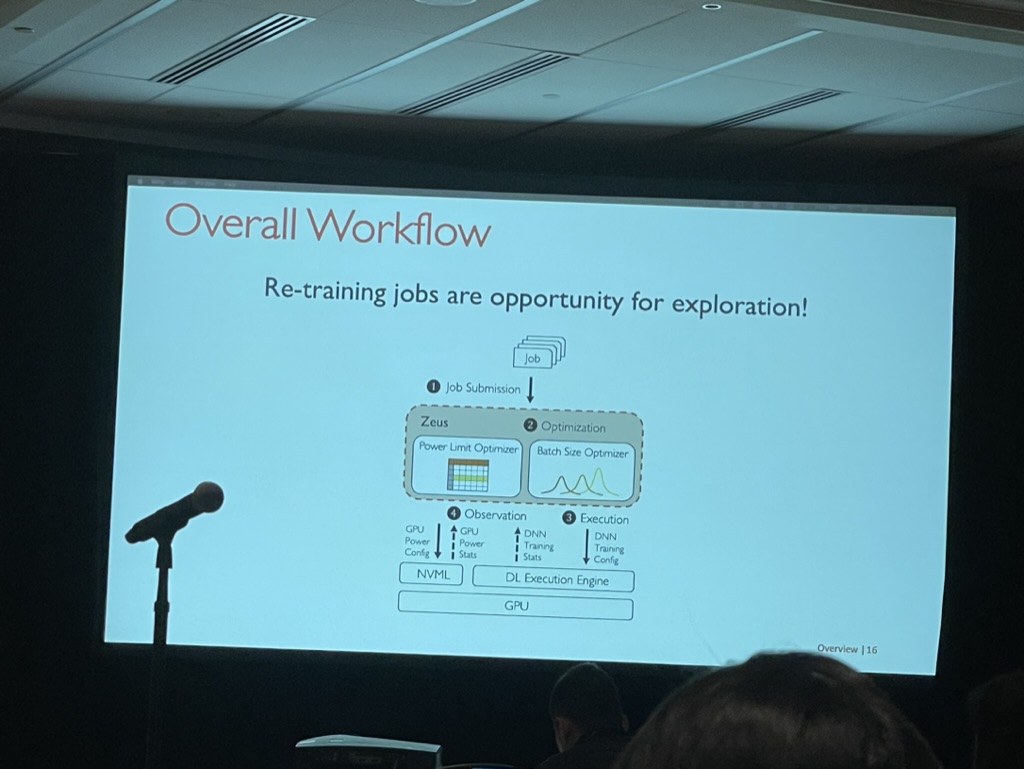
Zeus: Understanding and Optimizing GPU Energy Consumption of DNN Training
Jie You, Jae-Won Chung, and Mosharaf Chowdhury, University of Michigan
The authors of this work claim to have discovered a Pareto frontier between energy and performance that can be explored when retraining or finding the best configuration of a model. They even demonstrated their framework during their presentation using a stable diffusion model.
While their work is intriguing, it does pose a bit of a challenge. Reducing energy consumption typically results in lower utilization and performance. Although energy consumption is an important issue, it remains to be seen whether this framework will be widely adopted for trading energy.
RPC and Remote Memory (11:00 am–12:20 pm)
Remote Procedure Call as a Managed System Service
Jingrong Chen, Yongji Wu, and Shihan Lin, Duke University; Yechen Xu, Shanghai Jiao Tong University; Xinhao Kong, Duke University; Thomas Anderson, University of Washington; Matthew Lentz, Xiaowei Yang, and Danyang Zhuo, Duke University
Instead of using RPC as a library, this work proposes to use RPC as a system service.

The Benefit of Hindsight: Tracing Edge-Cases in Distributed Systems
Lei Zhang, Emory University and Princeton University; Zhiqiang Xie and Vaastav Anand, Max Planck Institute for Software Systems; Ymir Vigfusson, Emory University; Jonathan Mace, Max Planck Institute for Software Systems

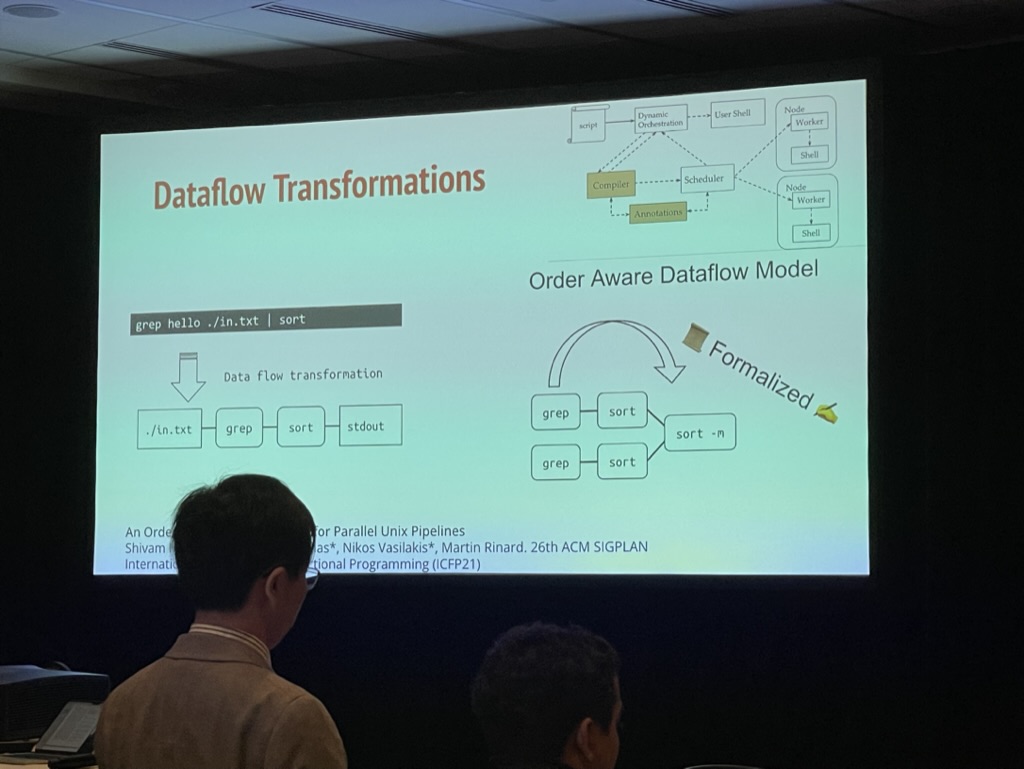
DiSh: Dynamic Shell-Script Distribution
Tammam Mustafa, MIT; Konstantinos Kallas, University of Pennsylvania; Pratyush Das, Purdue University; Nikos Vasilakis, Brown University
A parallel compiler for shell scripts.
Cloud (3:50 pm–5:10 pm)
SkyPilot: An Intercloud Broker for Sky Computing
Zongheng Yang, Zhanghao Wu, Michael Luo, Wei-Lin Chiang, Romil Bhardwaj, Woosuk Kwon, Siyuan Zhuang, Frank Sifei Luan, and Gautam Mittal, UC Berkeley; Scott Shenker, UC Berkeley and ICSI; Ion Stoica, UC Berkeley
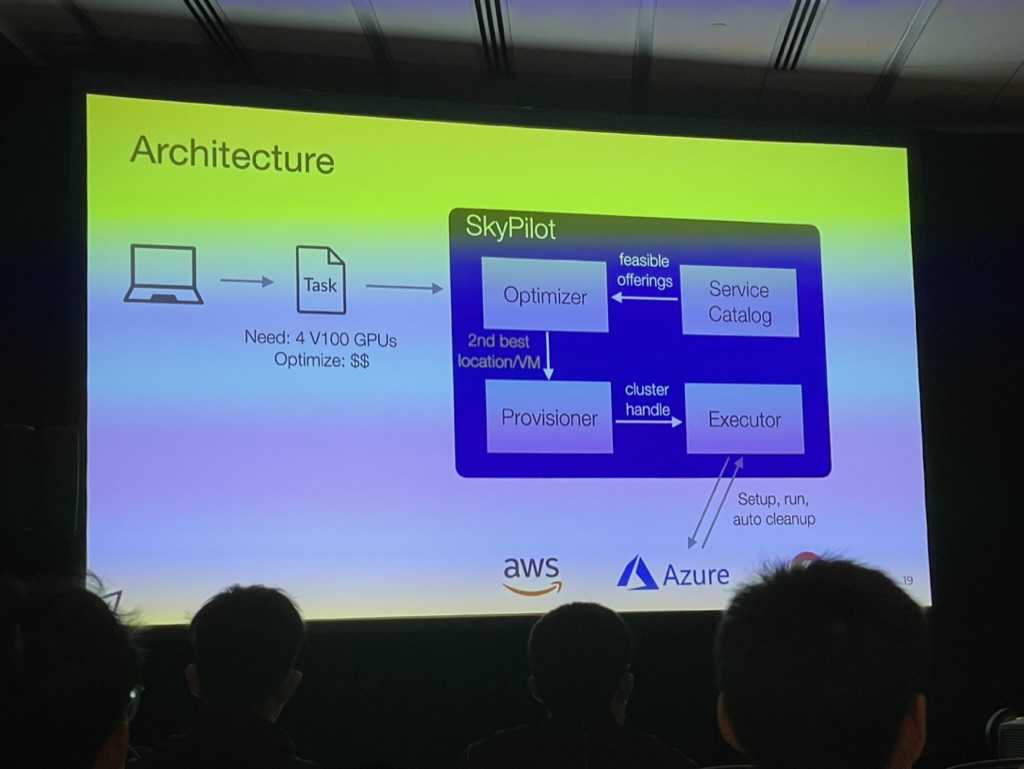
I heard many people discussing sky computing during the conference. I am not sure whether people will buy this idea. It seems the engineering effort is more than its research novelty. It actually poses lots of requirement on the users and cloud providers.
Bamboo: Making Preemptible Instances Resilient for Affordable Training of Large DNNs
John Thorpe, Pengzhan Zhao, Jonathan Eyolfson, and Yifan Qiao, UCLA; Zhihao Jia, CMU; Minjia Zhang, Microsoft Research; Ravi Netravali, Princeton University; Guoqing Harry Xu, UCLA

Very interesting work. Many people wanted to reduce the bubble in the pipeline, but this work says that we cannot reduce the bubble in the pipeline, then we can just embrace it. Since devices are idle during these bubbles, this approach can effectively reduce energy consumption. I also spoke with the Zeus author, who mentioned that they are exploring a similar idea to reduce energy consumption by dragging the fastest device to the slowest one.
I asked the author about the usability issue, and they mentioned their work is based on DeepSpeed, so there is no need to change the model.
Systems for Learning (Tuesday, 10:50 am–12:10 pm)
TopoOpt: Co-optimizing Network Topology and Parallelization Strategy for Distributed Training Jobs
Weiyang Wang, Moein Khazraee, Zhizhen Zhong, and Manya Ghobadi, Massachusetts Institute of Technology; Zhihao Jia, Meta and CMU; Dheevatsa Mudigere and Ying Zhang, Meta; Anthony Kewitsch, Telescent
Miss the talk, will update later.
ModelKeeper: Accelerating DNN Training via Automated Training Warmup
Fan Lai, Yinwei Dai, Harsha V. Madhyastha, and Mosharaf Chowdhury, University of Michigan
https://www.usenix.org/conference/nsdi23/presentation/lai-fan
This work is an interesting exploration of transfer learning, specifically for models with slight architecture differences that make it difficult to reuse parameters from existing pre-trained models. The author proposes a graph matching approach to partially initialize the model, which could potentially reduce training time.

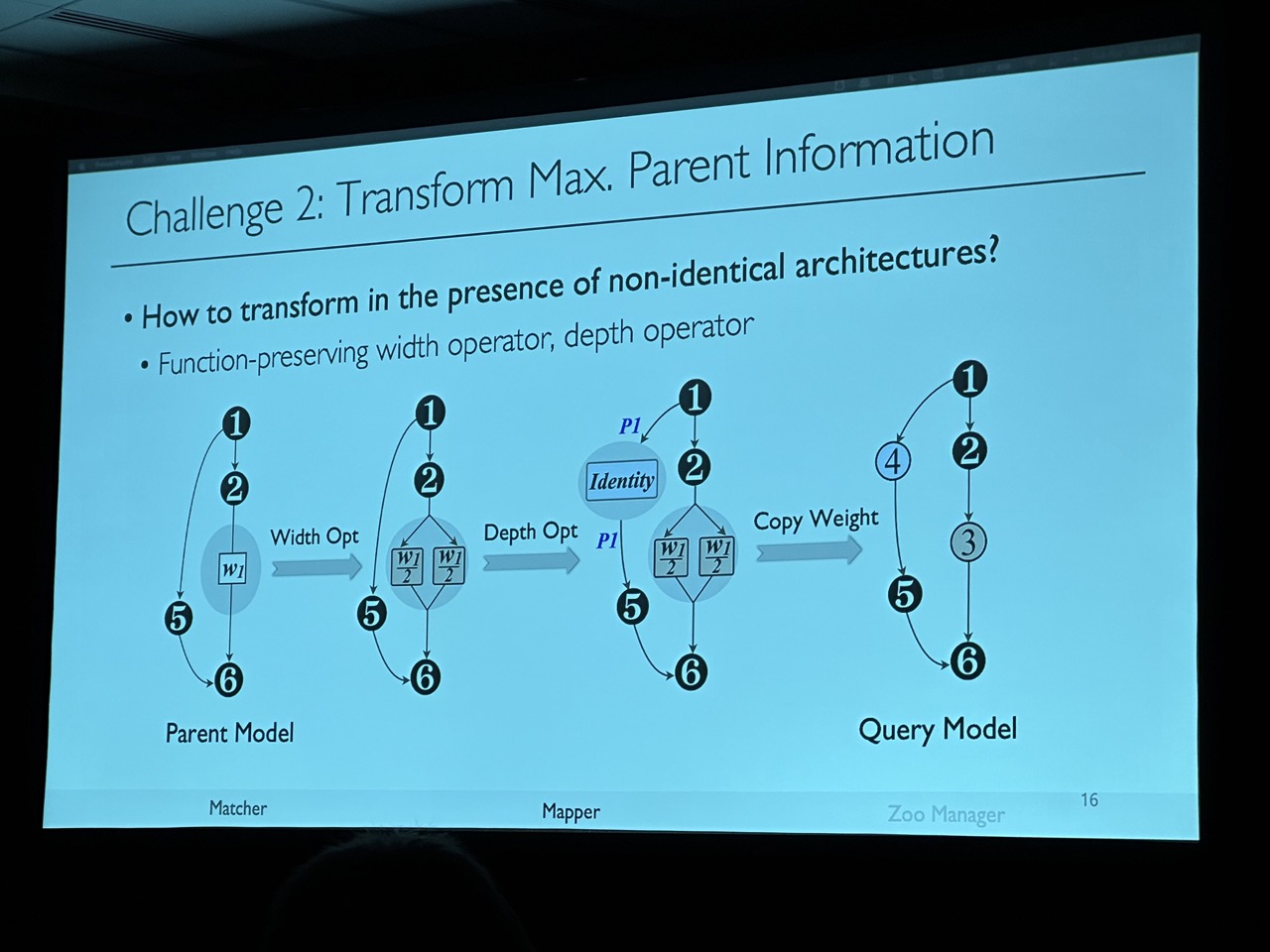
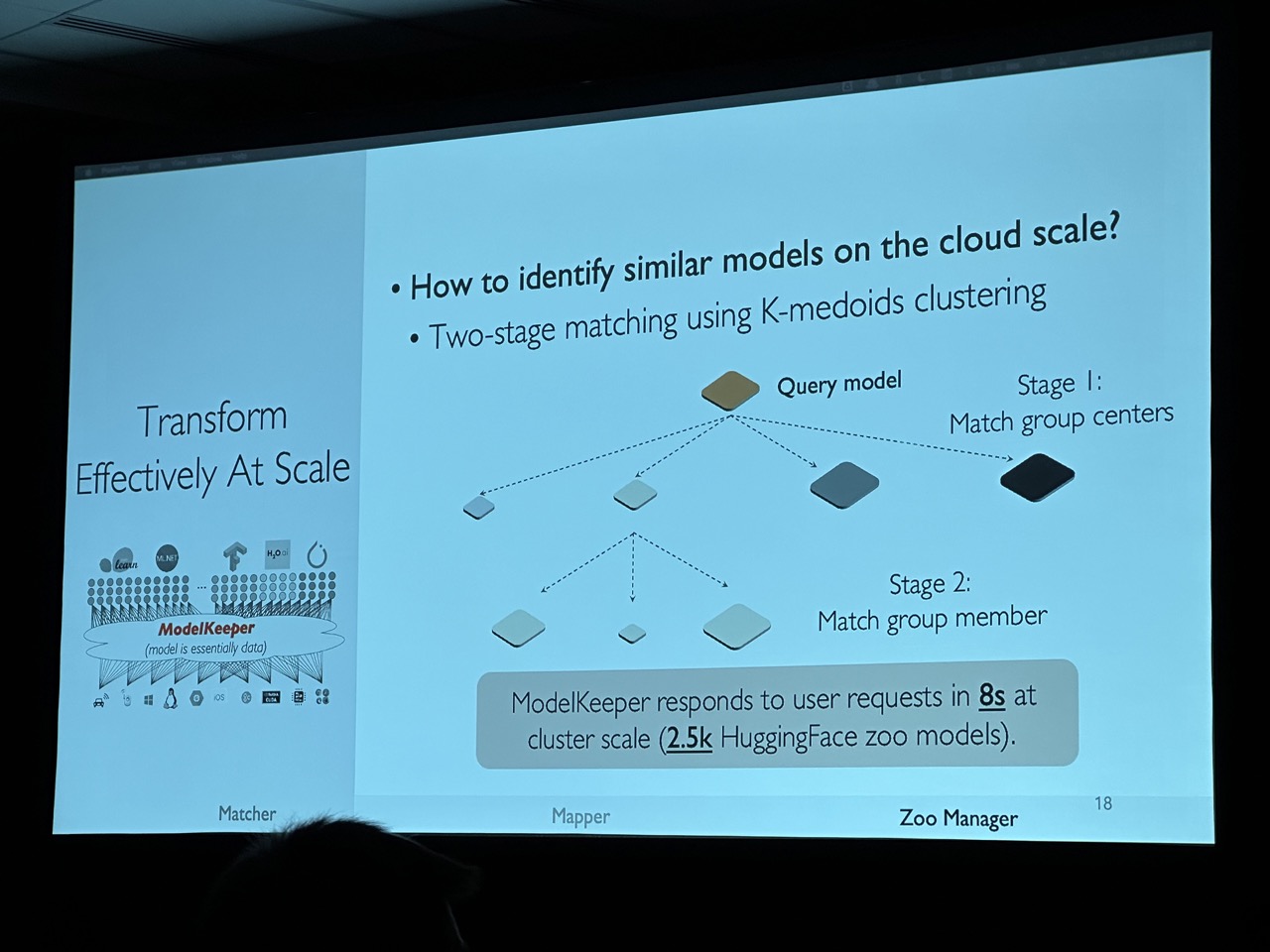
However, I am uncertain about the practicality of this approach. Most models on HuggingFace are quite regular and based on Transformers. Thus, few people are likely to modify the architecture and instead will just use the pre-trained checkpoint for downstream tasks. It’s possible that this approach could benefit more from neural architecture search (NAS) rather than traditional transfer learning.
SHEPHERD: Serving DNNs in the Wild
Hong Zhang, University of Waterloo; Yupeng Tang and Anurag Khandelwal, Yale University; Ion Stoica, UC Berkeley
https://www.usenix.org/conference/nsdi23/presentation/zhang-hong
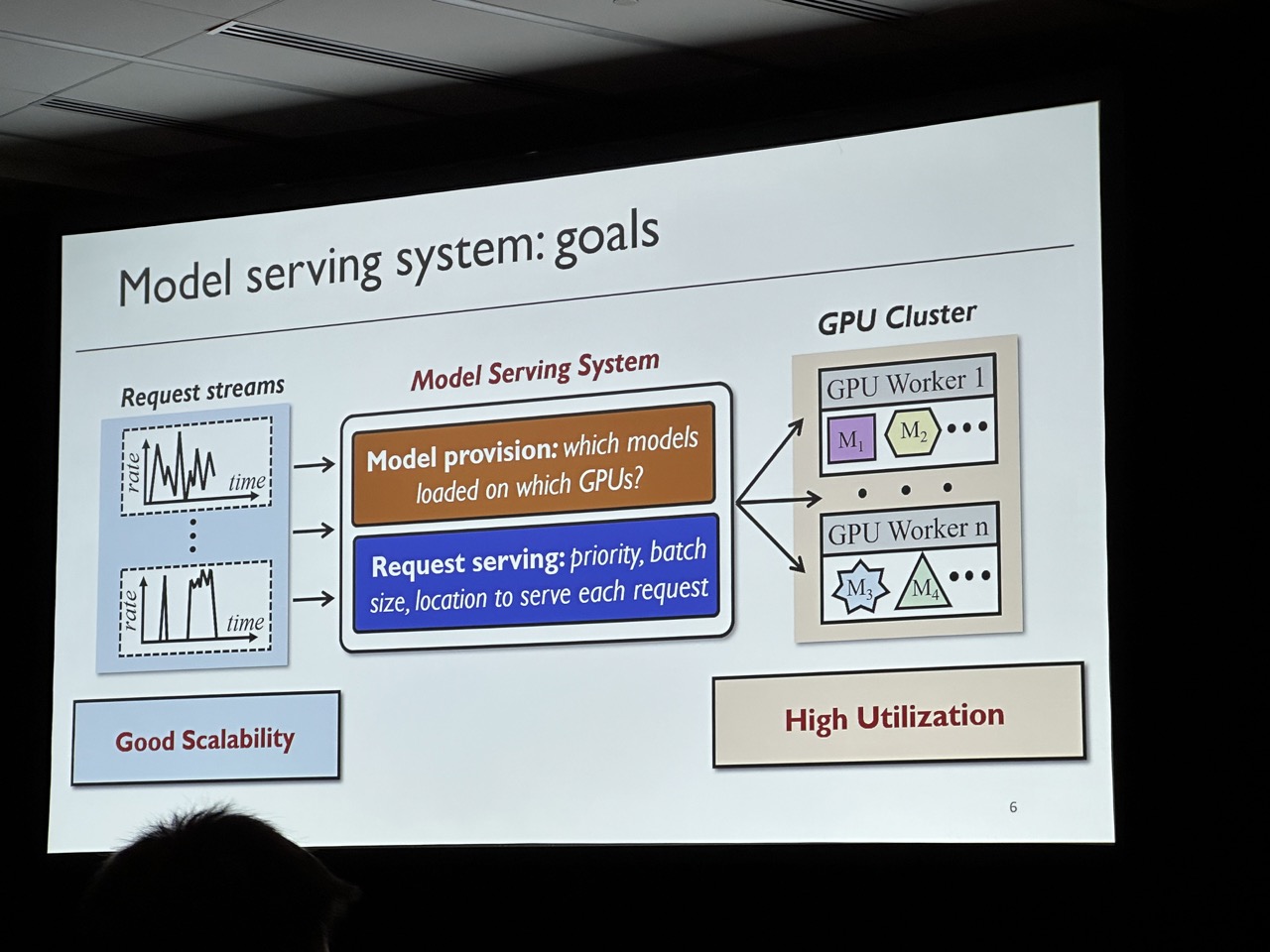
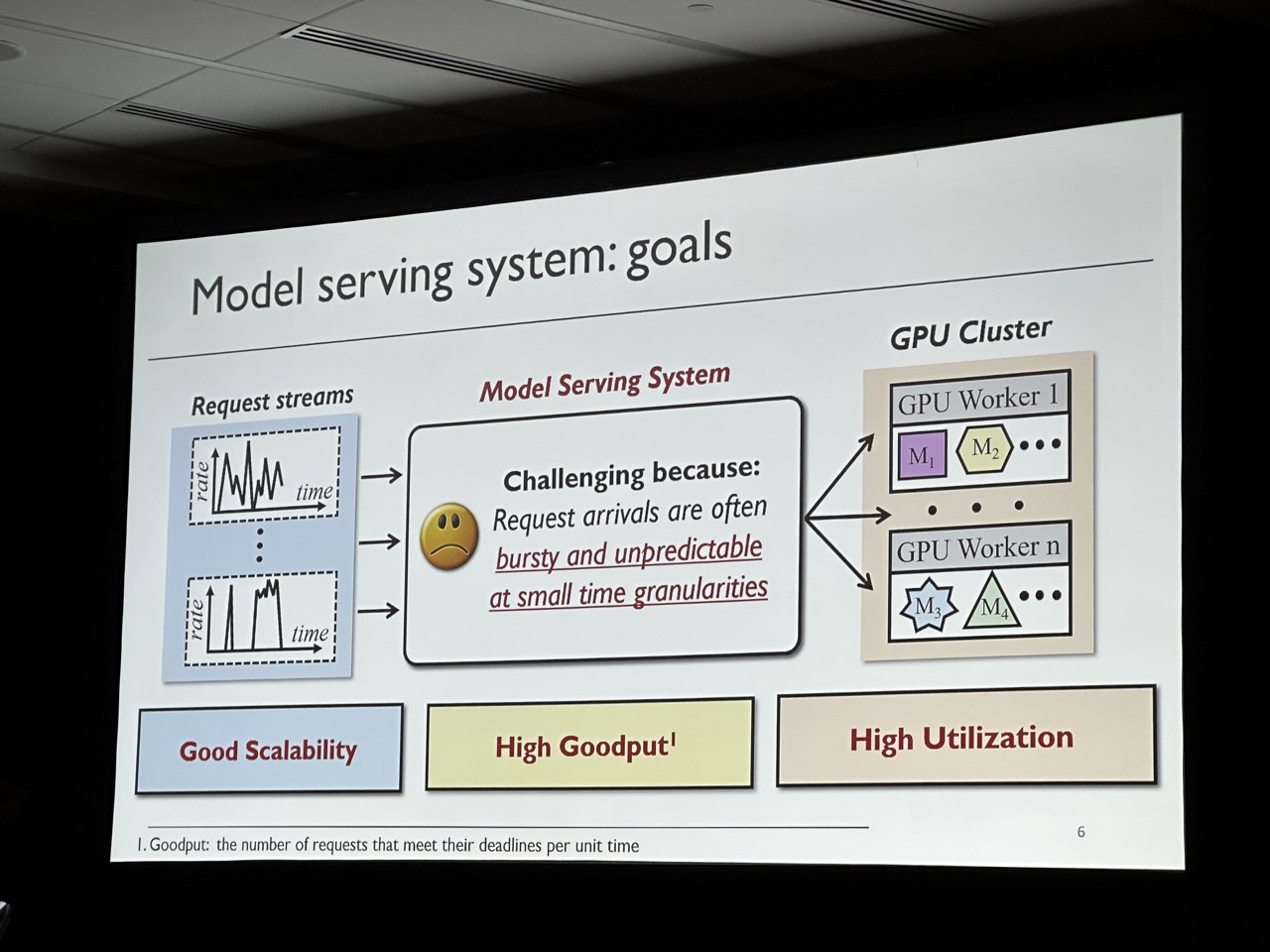
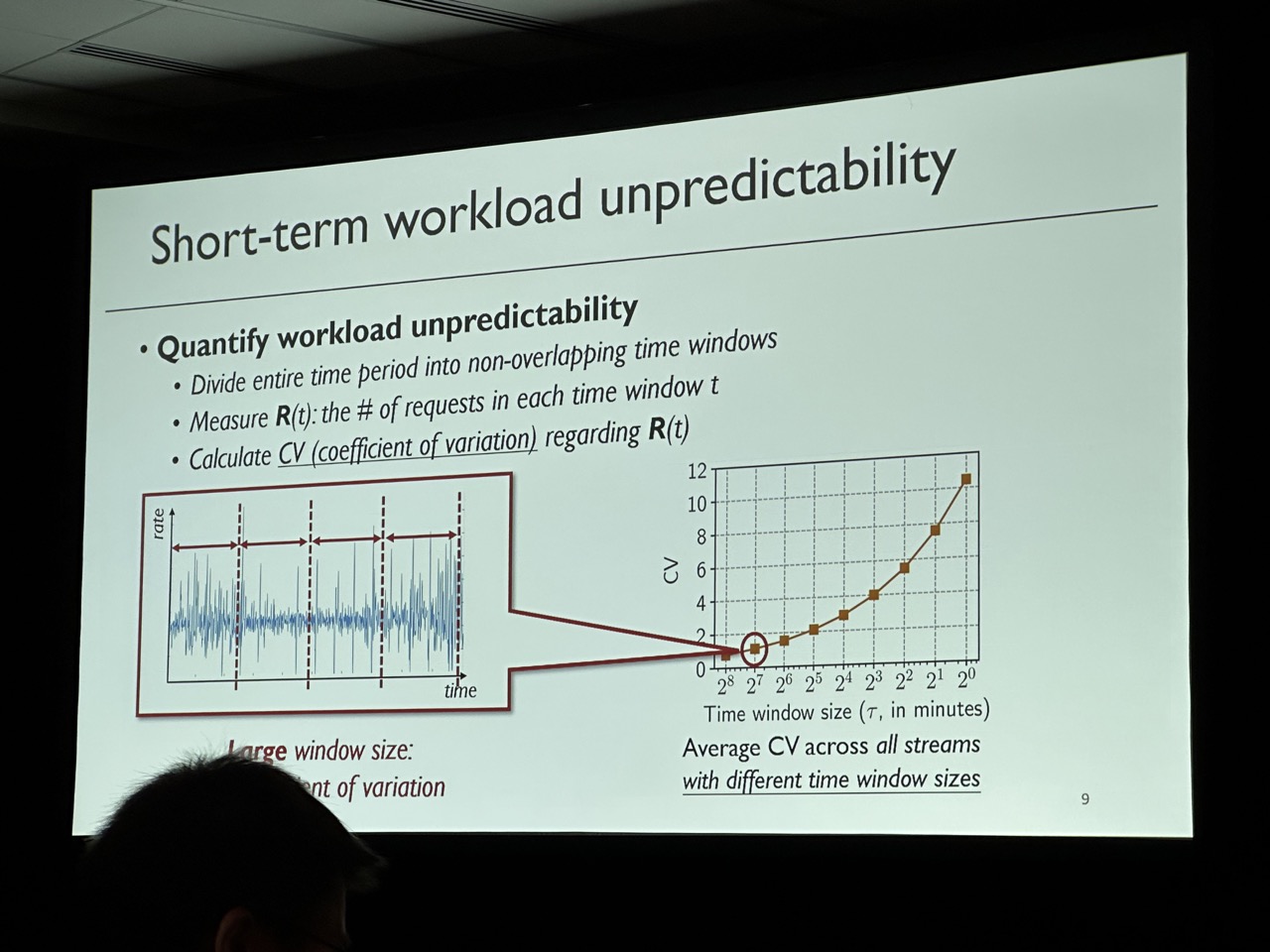
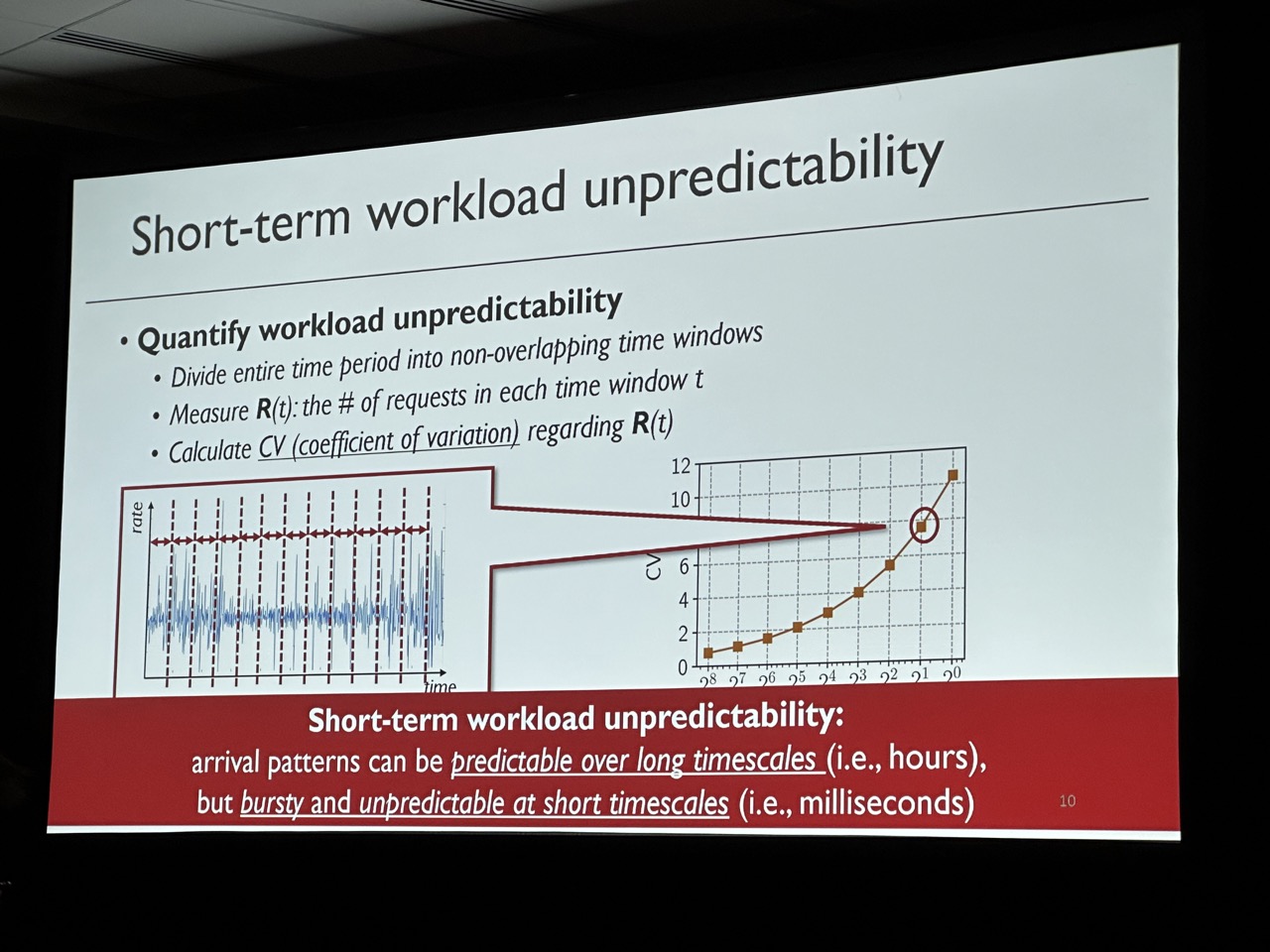
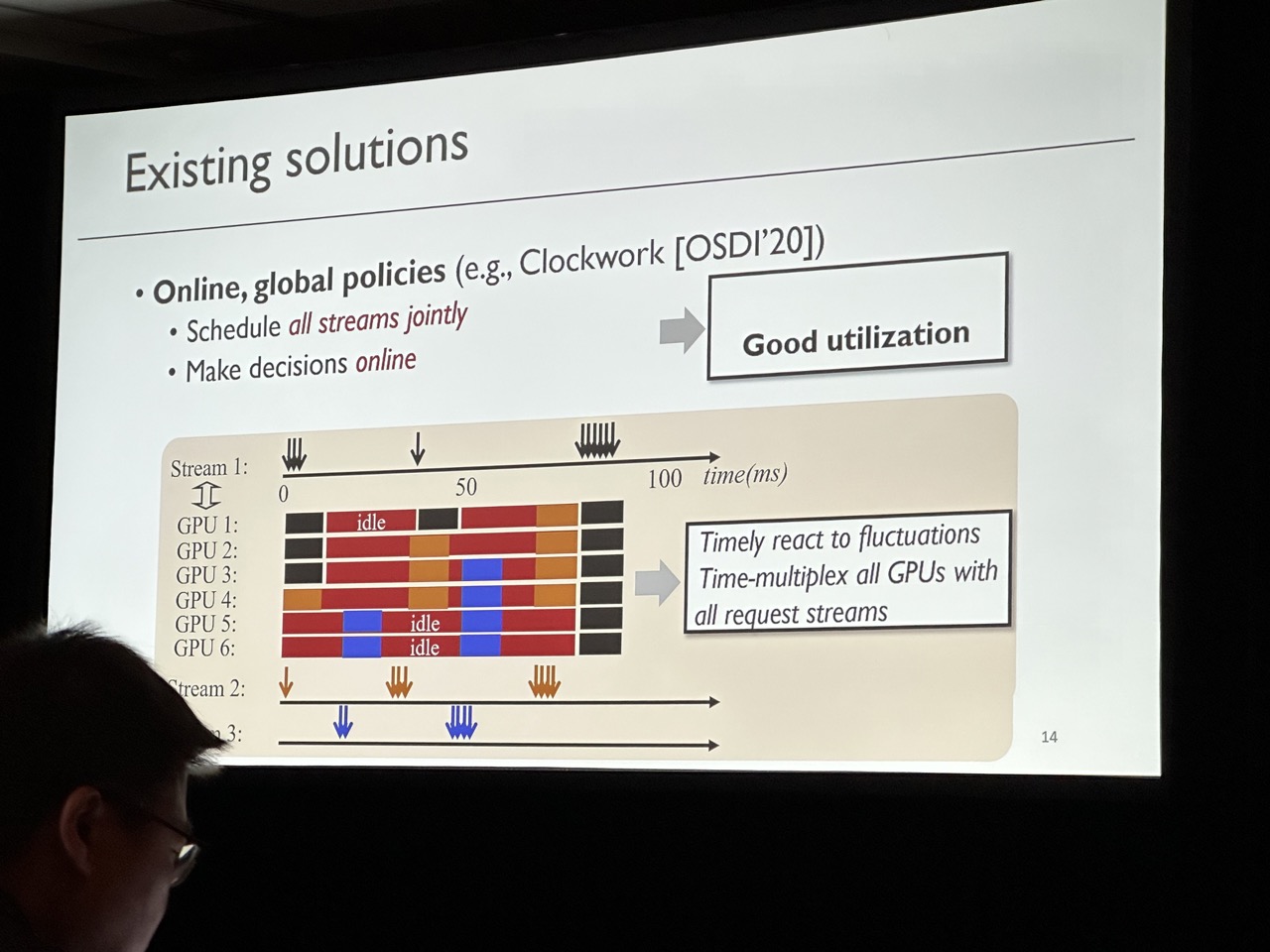
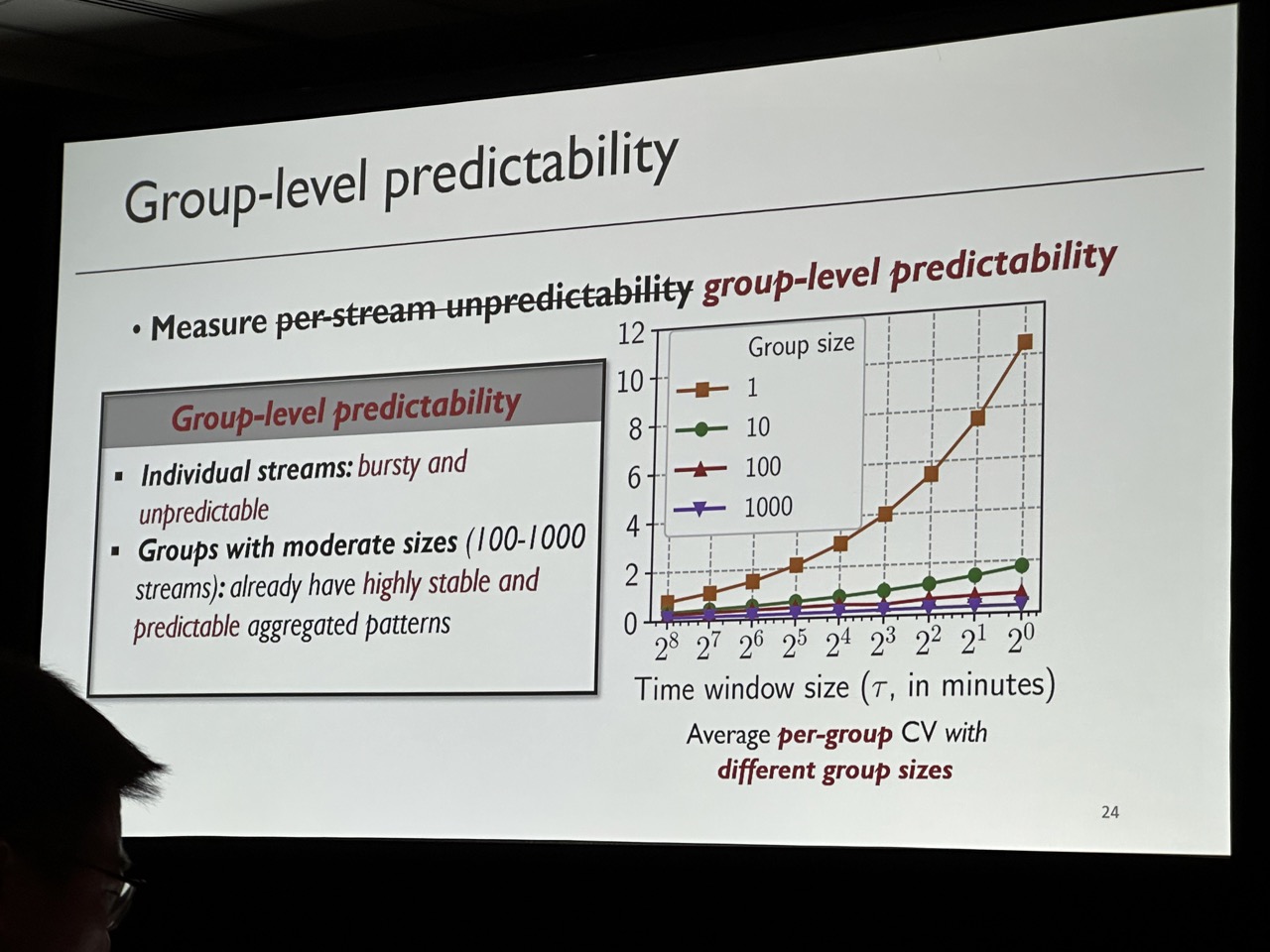
Key goal is to achieve high goodput (i.e., the number of requests that meet their deadlines per unit time). Observation is that although short-term requests are unpredictable, grouping requests in a relatively long-term can be predictable. SHEPHERD provides two algorithms to make the DNN serving have high goodput. Notice this work is mainly focuing on small DNN that can be fit in a single device. For LLM serving, refer to AlpaServe, which has already been accepted by OSDI’23.






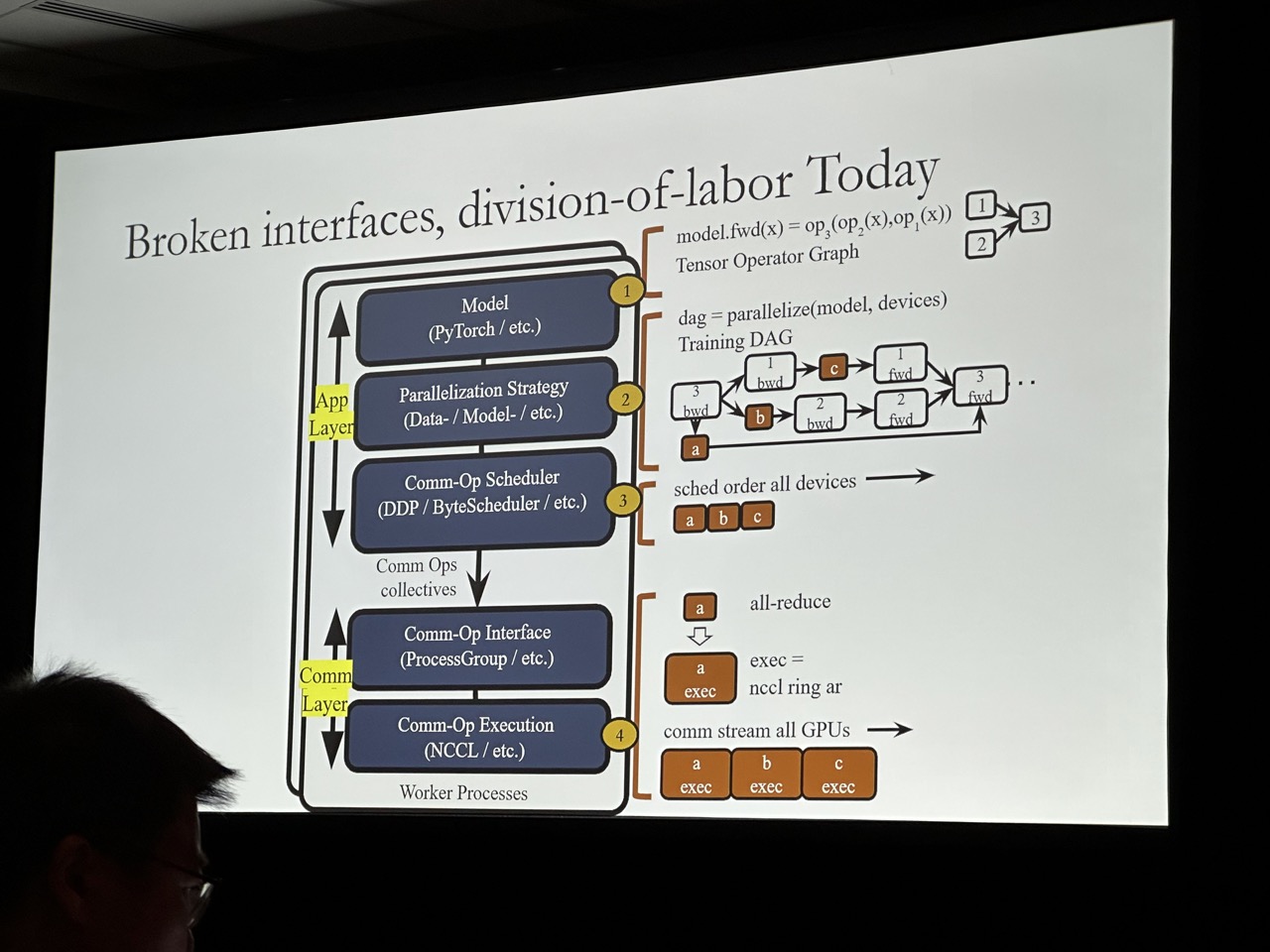
Better Together: Jointly Optimizing ML Collective Scheduling and Execution Planning using SYNDICATE
Kshiteej Mahajan, University of Wisconsin - Madison; Ching-Hsiang Chu and Srinivas Sridharan, Facebook; Aditya Akella, UT Austin

Data (Tuesday, 2:00 pm–3:20 pm)
Arya: Arbitrary Graph Pattern Mining with Decomposition-based Sampling
Zeying Zhu, Boston University; Kan Wu, University of Wisconsin-Madison; Zaoxing Liu, Boston University
Key idea is to decompose a complicated pattern into multiple simple subpatterns, e.g. 5-house -> triangle and square. Use LP solver to find the best decomposition, and conduct approximate pattern matching. Similar work from ASPLOS’23, DemoMine.
FLASH: Towards a High-performance Hardware Acceleration Architecture for Cross-silo Federated Learning
Junxue Zhang and Xiaodian Cheng, iSINGLab at Hong Kong University of Science and Technology and Clustar; Wei Wang, Clustar; Liu Yang, iSINGLab at Hong Kong University of Science and Technology and Clustar; Jinbin Hu and Kai Chen, iSINGLab at Hong Kong University of Science and Technology
They identify several important operators for cross-silo FL and implement them in FPGA. They use Verilog to implement on-chip controller, which is a harden block. They use FPGA but it is not for its reconfigurability, so that they can achieve more speedup when simulating the results on ASIC.
Making Systems Learn (Tuesday, 3:50 pm–5:10 pm)
On Modular Learning of Distributed Systems for Predicting End-to-End Latency
Chieh-Jan Mike Liang, Microsoft Research; Zilin Fang, Carnegie Mellon University; Yuqing Xie, Tsinghua University; Fan Yang, Microsoft Research; Zhao Lucis Li, University of Science and Technology of China; Li Lyna Zhang, Mao Yang, and Lidong Zhou, Microsoft Research
https://www.usenix.org/conference/nsdi23/presentation/liang-chieh-jan