Hongzheng Chen Blog
ASPLOS'24 Attendence Summary
Apr 28th, 2024 0This year ASPLOS took place in San Diego, California. I am fortunate to have a paper got accepted, which provided me the opportunity to attend and present my work at the conference. This blog post primarily offers a summary of the conference papers, focusing on topics related to my research, including machine learning systems, compilers, accelerators, and hardware synthesis, which appears to have ~50% of the total number of papers presented.
Workshops/Tutorials
There are several interesting workshops and tutorials this year. The workshops were held during the weekend (April 26-27) before the main conference, and I mainly attended the PyTorch 2, LATTE, and the EMC2 workshops.
PyTorch 2
PyTorch 2 marks a significant milestone, representing the most substantial update since the release of PyTorch 1.0. The most advanced feature in PyTorch 2 is the equipment of the compiler, which can be invoked by torch.compile. Additionally, PyTorch 2 is also accepted as a main conference paper this year.
This workshop is mainly about the techniques behind the PyTorch 2 compiler, including the TorchDynamo and TorchInductor.
The PyTorch team really did a good job that all the slides and demo materials are available on their Github repo.
TorchDynamo
This part illustrates the tradeoff between eager mode (usability) and graph mode (performance). As a dynamic-graph-based framework, PyTorch’s highly Pythonic nature traditionally complicates performance optimization.

The core concept of TorchDynamo involves utilizing a JIT compiler for code that is simpler to optimize, while reverting to the standard Python runtime for more complex (non-graph) code. The following figure illustrates how the JIT compiler works.
TorchDynamo hooks into the frame evaluation API in CPython (PEP 523) to dynamically modify Python bytecode right before it is executed. It rewrites Python bytecode to extract sequences of PyTorch operations into an FX Graph which is then compiled with a customizable backend. It creates this FX Graph through bytecode analysis and is designed to mix Python execution with compiled backends to get the best of both worlds — usability and performance.
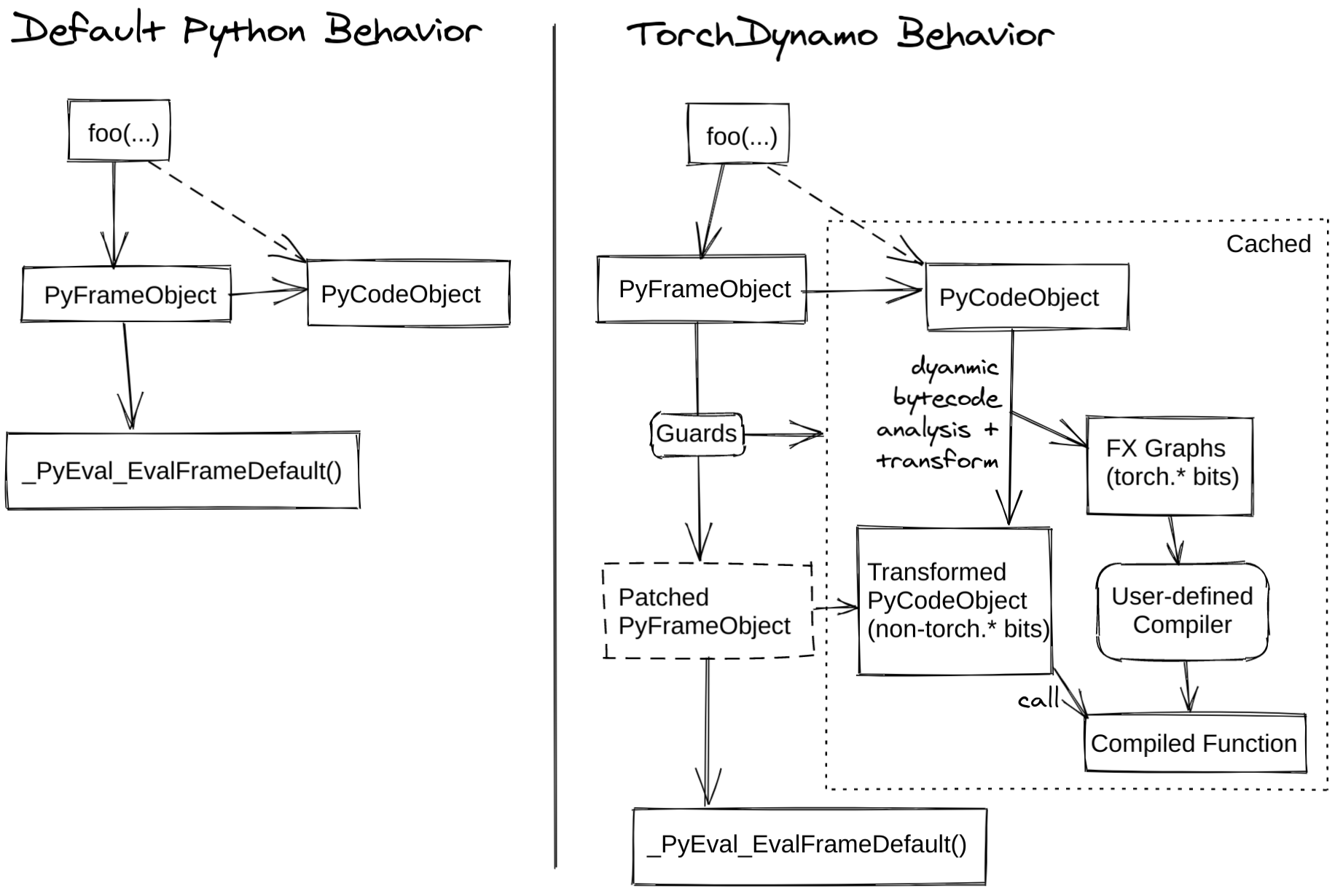
This mechanism also allows users to directly work on the extracted FX graph, and integrate their own backend compiler for further optimization. For debugging, TorchDynamo also provides an easy way (i.e., TORCH_LOGS=...) to inspect the optimizations inside. Please refer to this document for more details.
TorchInductor
TorchInductor is the backend for optimized kernel generation.

It has a loop-level IR that disentangles what’s being computed from the manner in which it’s computed, which is quite similar to TVM/Halide, but Inductor directly uses keyword variables to define those optimizations.
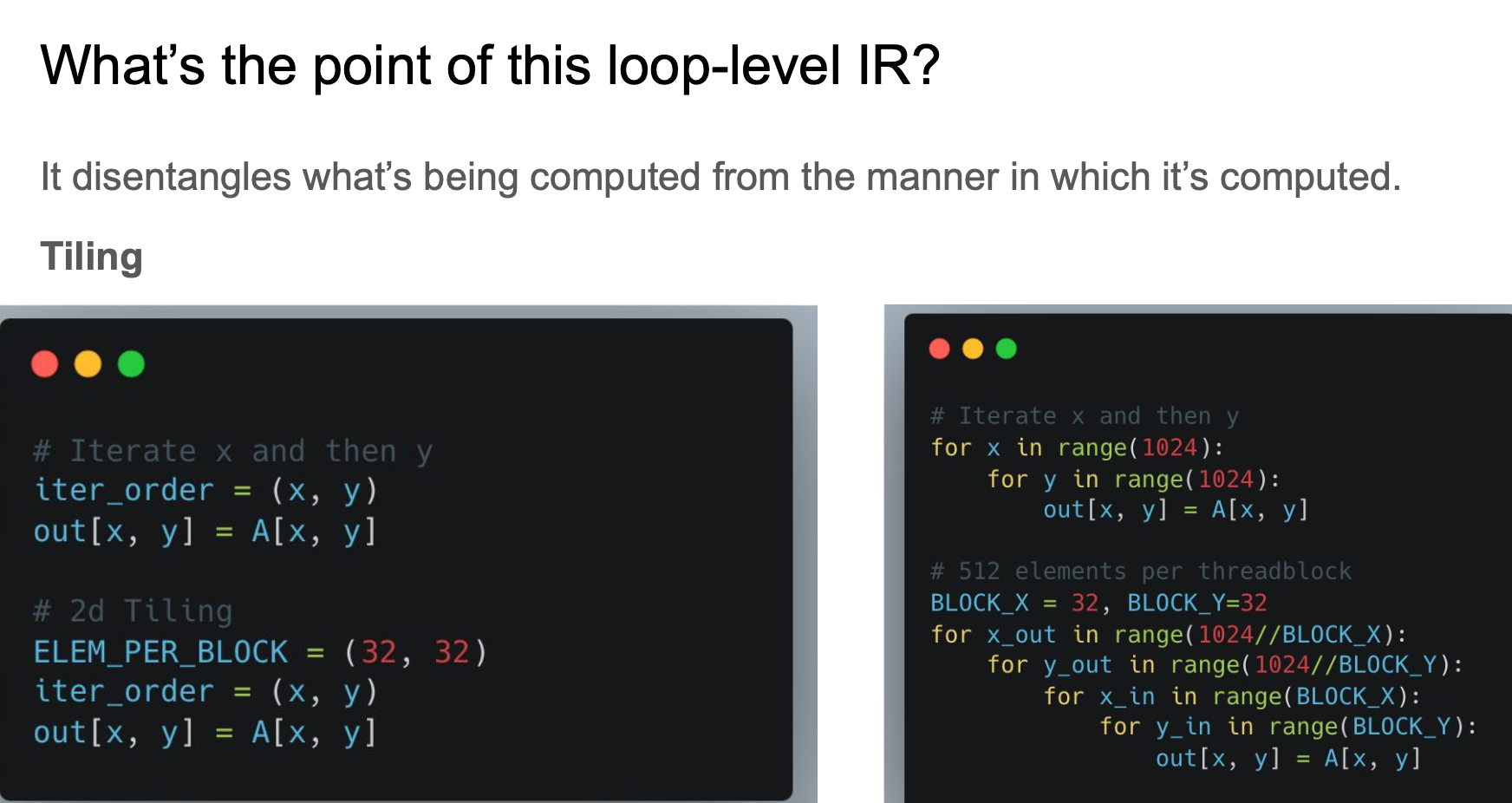
The compilation of TorchInductor has four steps:
- Lower FX graph to loop-level IR
- Memory planning
- Scheduling and loop fusion
- Codegen
Details can be found in their slide. Here I only briefly mention their backend codegen. TorchInductor uses Triton as their GPU backend, and directly generate Triton source code for the optimized (fused) kernel.

I asked the PyTorch team about their choice to generate Triton source code rather than utilizing the MLIR-based Triton IR. Jason Ansel, the lead author of the PyTorch 2 paper, explained that the decision was primarily driven by usability considerations. Triton source code is human-readable, maintainable, and offers greater stability, as its API undergoes fewer changes. In contrast, since the development of TorchInductor began, the Triton IR has already undergone FOUR revisions.
Crazy Research Ideas
This session presented by Jason Ansel and Horace He. , I found to be the most interesting, valuable, and grounded. Unfortunately, they did not release the slides on their website, so I have compiled the images together and shared them here (PDF file).
They mentioned two practical ML system research from academia. The first one is Triton that can really challenge the CUDA ecosystem and has been integrated as a default backend of PyTorch. Interestingly, despite its integration and significance, the Triton paper was initially rejected several times by top-tier system conferences like ASPLOS and PLDI before finally being published at a second-tier conference.
The second project, FlashAttention, has become a core component of attention modules in modern Transformers. It essentially rewrites the attention (softmax) function mathematically and implements kernel fusion on GPUs – a simple yet groundbreaking enhancement overlooked by systems researchers and industry engineers. Despite its apparent simplicity, as evidenced when Tri Dao visited our school last year for a job talk and faced skepticism from many professors, the FlashAttention kernel has been quietly integrated into various LLM systems, proving that even ‘trivial’ ideas can be transformative.
What sets Triton apart is its tile-based programming model, illustrated in the comparison below.

Horace also highlighted that while most research defines a search space aiming for an optimal point, such autoschedulers often fail to generalize to new optimizations. Sometime they know the optimal point in advance and just design a search space containing that point. A more effective approach might be using them to discover entirely new optimizations.
Jason emphasized the importance of standardized benchmarking and promoted their benchmarking framework, which can be utilized to run experiments across various models.
Languages, Tools, and Techniques for Accelerator Design (LATTE)
This workshop is mainly about hardware design and programming language research organized by Prof. Adrian Sampson and Rachit Nigam from Cornell. It featured many intriguing talks, though unfortunately, due to a scheduling overlap with the PyTorch 2 workshop, I was only able to attend the sessions on the second day.
The workshop showcased the growing interest among several research groups in harnessing programming language techniques to tackle hardware design challenges. For example, Jonathan Balkind has four workshop paper accepted. Gus Henry Smith (UW) has a paper about how to leverage egraph to handle different stages of hardware synthesis, demonstrating that many problems in this area can be effectively addressed using equality saturation. He also provided a web-hosted demo to illustrate the concept. He also has a main conference paper using another program synthesis technique for technological mapping.
The Mojo language people are also invited to give a keynote talk at the workshop. However, they did not present something really new, and most of the features can be found in their official document and other slide. The key idea is to leverage Python’s type parameters to do meta-programming, which can give users more flexibility creating their own templates and also provide ability for easy auto-tuning.

EMC2: Energy Efficient Machine Learning & Cognitive Computing
This workshop brought together many prominent figures in the field of efficient machine learning to present their research. Their talks and published papers are certainly worth a closer examination. I only listened to the talk presented by Amir Yazdanbakhsh from Google Deepmind, where he talked about how to leverage LLM to optimze programs. They introduced a dataset comprising pairs of original and optimized programs, using the gem5 simulator to generate simulated performance metrics as labeled data. By integrating RAG and fine-tuning, they managed to surpass the performance of manually optimized designs. This paper is published as a spotlight paper at ICLR’24.
Poster Session
The poster session took place on the evening before the main conference. This year ASPLOS has lots of things for the authors to work on, including poster, pre-recorded & in-person lightning talk, and conference talk. The requirement for presenters to participate in each of these elements posed a considerable burden.
With a high number of papers accepted this year, the posters filled the entire meeting room and spilled into the corridor. Locating my own poster board took a considerable amount of time. While it was nearly impossible to view all the posters, the opportunity to engage directly with the authors of particularly interesting papers was invaluable. Despite the challenges, the session was a success, drawing a large audience and facilitating engaging discussions.

Day 1
Opening Remarks
This year, ASPLOS achieved a record turnout with approximately 800 in-person attendees and a significant increase in accepted papers. The program chairs, Madan Musuvathi and Dan Tsafrir, contributed an unprecedented 50 pages of PC messages to the proceedings—far exceeding the usual length of less than 10 pages in previous years. This expansion is largely due to the substantial rise in submissions, which totaled 921 this year, facilitated by the introduction of three submission cycles. To manage this volume, a 272-member program committee was assembled. They also introduced a new algorithm to better match papers with relevant reviewers. Despite these efforts, each committee member was still tasked with reviewing between 15 to 17 papers, indicating a considerable workload.
Out of the numerous submissions, 170 papers were accepted, and 33 underwent a major revision in the fall. The conference was organized into 44 sessions featuring 193 papers, including 23 from ASPLOS’23’s fall revision. With such a dense schedule, the conference had to run four parallel sessions, allotting each presentation 12 minutes followed by 3 minutes for Q&A, making it challenging to attend every session.
More details on the operation of the program committee and the review process can be found in the proceedings. With the trend of increasing submissions, it is anticipated that ASPLOS’25 will exceed 1000 submissions, leading to the introduction of vice program chairs (and Adrian is one of the vice PC!). It appears that ASPLOS is aiming to emulate conferences like NeurIPS by accepting a diverse range of papers within the architecture field.
Keynote
The first keynote I attended was delivered by Amin Vahdat from Google, titled “Societal infrastructure in the age of Artificial General Intelligence.” It was the only keynote that caught my interest, as I found the overall selection and scheduling of keynotes this year to be somewhat lackluster and oddly organized, particularly with two keynotes crammed into the last day, one of which was in the afternoon.
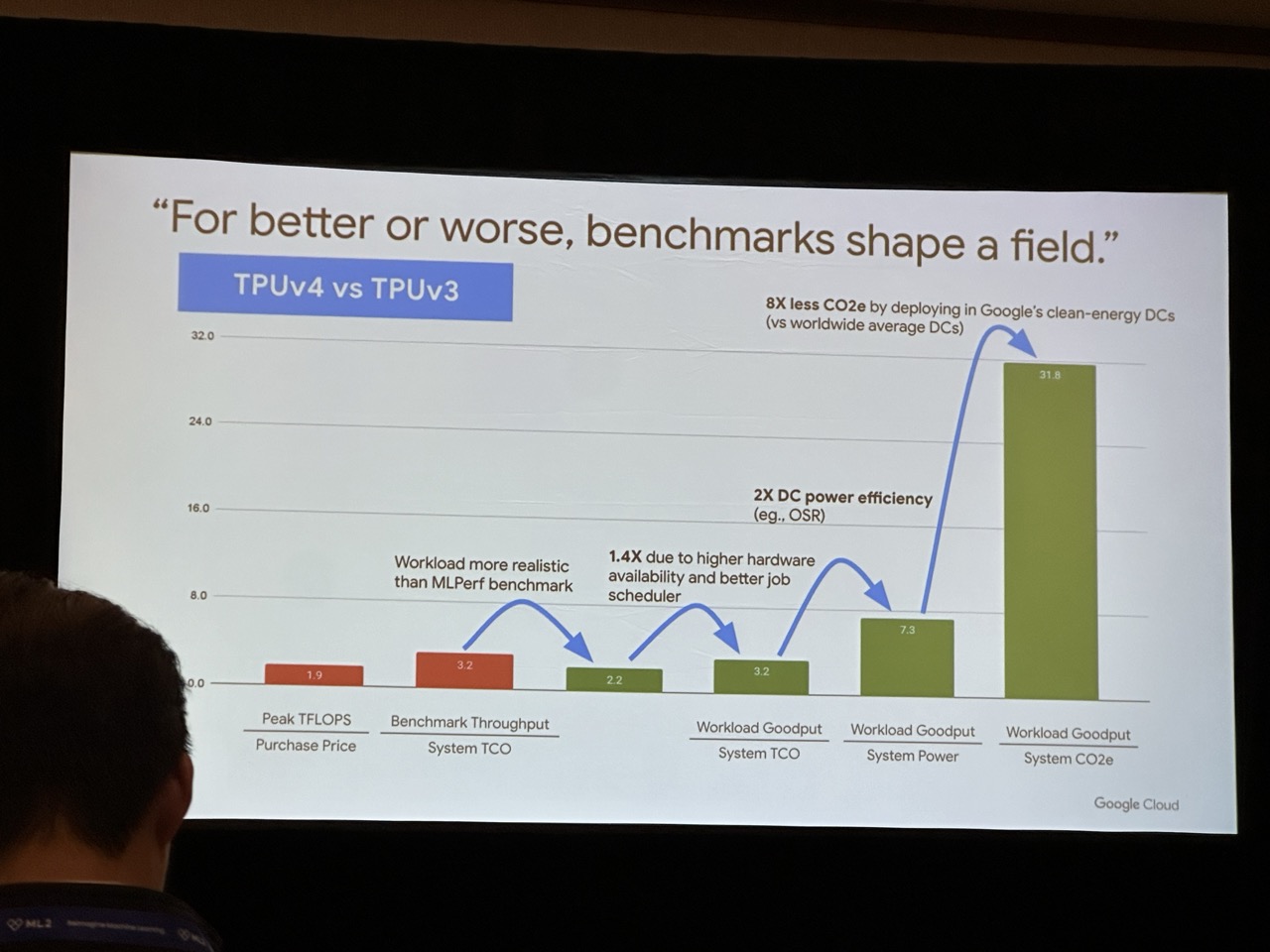
Back to the Google keynote, it is more about the social impact of AI. A key takeaway was their introduction of a new metric for measuring system effectiveness. They proposed shifting from Perf/TCO (Total Cost of Ownership) to Perf/CO2, aiming to foster the development of more sustainable systems.

Lightning Talks
After keynote, it is the lightning talk session. Each paper has 90 second to pitch their work. This session is also very packed. You cannot expect the audience to get some technical details from this 90 seconds, but you can try you best to make the audience remember your work and come to your talk.
Session 1A: Synthesis for Architectures
It is suprising that this year has an entire session for high-level synthesis (HLS).
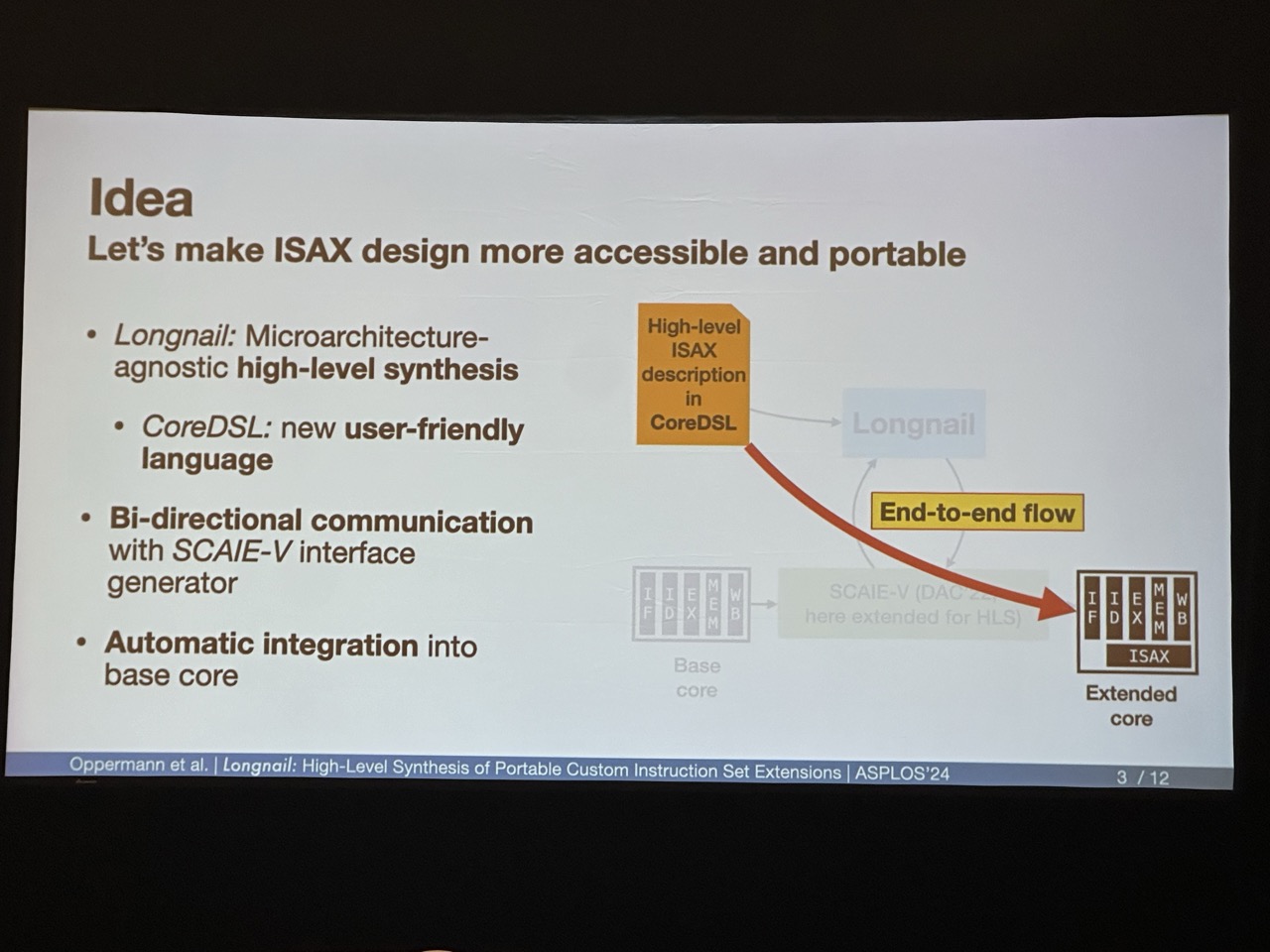
Longnail: High-Level Synthesis of Portable Custom Instruction Set Extensions for RISC-V Processors from Descriptions in the Open-Source CoreDSL Language
Julian Oppermann, Brindusa Mihaela Damian-Kosterhon, Florian Meisel, and Tammo Mürmann (Technical University of Darmstadt);Eyck Jentzsch (MINRES Technologies GmbH);Andreas Koch (Technical University of Darmstadt)
This work is particularly compelling as it introduces an automated tool for extending the RISC-V ISA. The provided CoreDSL diagram illustrates a streamlined process where users simply input the encoding and behavior specifications for a new instruction. The tool, Longnail, then automatically generates the corresponding MLIR code. This code is subsequently integrated with CIRCT to produce RTL code, which can then be seamlessly incorporated into the RISC-V processor architecture. This automation greatly simplifies the task of ISA extension, making it more accessible and efficient.

SEER: Super-Optimization Explorer for High-Level Synthesis using E-graph Rewriting
Jianyi Cheng (University of Cambridge and Intel); Samuel Coward (Imperial College London and Intel); Lorenzo Chelini, Rafael Barbalho, and Theo Drane (Intel)
Jianyi’s work, but unfortunately, he could not come to US due to visa issue, and the talk was presented by Rafael. The key idea is to integrate egraph for HLS code rewriting. Basically this idea is straightforward, but it may suffer from scalability issues since it directly uses the egg solver for egraph extraction.

HIDA: A Hierarchical Dataflow Compiler for High-Level Synthesis
Hanchen Ye, Hyegang Jun, and Deming Chen (University of Illinois Urbana-Champaign)
Hanchen’s work, extension to ScaleHLS, but currently can only support double-buffer for dataflow architecture. Therefore, for large designs, HIDA is still not able to push them to run on the actual FPGA board.
Session 1B: Optimizing ML Communication
Unfortunately I could not attend this parallel session, but I listed two papers that may be interesting. One of them received the best paper award.
[Best Paper] Centauri: Enabling Efficient Scheduling for Communication-Computation Overlap in Large Model Training via Communication Partitioning
Chang Chen, Xiuhong Li, and Qianchao Zhu (Peking University); Jiangfei Duan (Chinese University of Hong Kong); Peng Sun and Xingcheng Zhang (Shanghai AI Lab); Chao Yang (Peking University)
It seems the idea is similar to this ASPLOS’23 paper that decomposes the communication into small steps, so that the computation can be better overlapped with the communication.
Two-Face: Combining Collective and One-Sided Communication for Efficient Distributed SpMM
Charles Block, Gerasimos Gerogiannis, and Charith Mendis (University of Illinois at Urbana-Champaign); Ariful Azad (Indiana University); Josep Torrellas (University of Illinois at Urbana-Champaign)
Session 2D: ML Inference Systems
The sessions related to MLSys always have lots of people to attend.
SpecInfer: Accelerating Large Language Model Serving with Tree-based Speculative Inference and Verification
Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, and Zeyu Wang (Carnegie Mellon University); Zhengxin Zhang (Tsinghua University); Rae Ying Yee Wong (Stanford University); Alan Zhu and Lijie Yang (Carnegie Mellon University); Xiaoxiang Shi (Shanghai Jiao Tong University); Chunan Shi (Peking University); Zhuoming Chen and Daiyaan Arfeen (Carnegie Mellon University); Reyna Abhyankar (University of California San Diego); Zhihao Jia (Carnegie Mellon University)
“A key insight behind SpecInfer is to simultaneously consider a diversity of speculation candidates (instead of just one as in existing approaches) to maximize speculative performance. These candidates are organized as a token tree, whose nodes each represents a sequence of speculated tokens. The correctness of all candidate token sequences is verified against the LLM in parallel, which allows SpecInfer to significantly increase the number of generated tokens in an LLM decoding step.”

Proteus: A High-Throughput Inference-Serving System with Accuracy Scaling
Sohaib Ahmad and Hui Guan (University of Massachusetts Amherst); Brian D. Friedman and Thomas Williams (Nokia Bell Labs); Ramesh K. Sitaraman (University of Massachusetts Amherst); Thomas Woo (Nokia Bell Labs)
They proposed accuracy scaling, where the system adapts its performance based on demand. During periods of low demand, it utilizes a high-accuracy model, while in times of high demand, it switches to a lower-accuracy model. This approach trades off accuracy for increased throughput. However, such a strategy might not be practical in real-world applications where consistent accuracy is critical.
[Distinguished AE Award] SpotServe: Serving Generative Large Language Models on Preemptible Instances
Xupeng Miao (Carnegie Mellon University); Chunan Shi (Peking University); Jiangfei Duan (The Chinese University of Hong Kong); Xiaoli Xi (Carnegie Mellon University); Dahua Lin (Chinese University of Hong Kong and Sensetime Research); Bin Cui (Peking University);Zhihao Jia (Carnegie Mellon University)
Spot instances are cost-effective computing resources that can be preempted at any time. The core strategy discussed here involves using these preemptible instances to host LLMs. Upon notification of impending shutdown during the grace period, the system dynamically adjusts the parallelism scheme and migrates the context (KV cache) to maintain continuity. This approach of altering the parallelism configuration is intriguing and demonstrates potential in simulations. However, the practicality of using spot instances for serving LLMs in real-world applications may be limited due to the unpredictability.

Session 3D: ML Quantization and Memory Optimizations
MAGIS: Memory Optimization via Coordinated Graph Transformation and Scheduling for DNN
Renze Chen (Peking University); Zijian Ding (University of California Los Angeles); Size Zheng and Chengrui Zhang (Peking University); Jingwen Leng (Shanghai Jiao Tong University); Xuanzhe Liu and Yun Liang (Peking University)
Use fission to reduce tensor shape and GPU memory usage, but it seems the experiments are only conducted on a single GPU.
![]()
8-bit Transformer Inference and Fine-tuning for Edge Accelerators
Jeffrey Yu, Kartik Prabhu, Yonatan Urman, Robert M. Radway, Eric Han, and Priyanka Raina (Stanford University)
A new data format - posit8, algorithm-hardware co-design.

Debate & WACI
These sessions were among the most engaging at ASPLOS, although I was only able to attend the first half of the debate before leaving for dinner (Yes, ASPLOS did not provide dinner that evening, yet scheduled two concurrent sessions after 6 PM). The initial personal statements were somewhat lackluster, but the session became more intriguing once it incorporated questions from the audience.


Day 2
Session 5A: Compiler and Optimization Techniques
BaCO: A Fast and Portable Bayesian Compiler Optimization Framework
Erik Orm Hellsten (Lund University);Artur Souza (Federal University of Minas Gerais); Johannes Lenfers (University of Münster); Rubens Lacouture and Olivia Hsu (Stanford University);Adel Ejjeh (University of Illinois at Urbana-Champaign); Fredrik Kjolstad (Stanford University); Michel Steuwer (University of Edinburgh); Kunle Olukotun (Stanford University); Luigi Nardi (Lund University and Stanford University)
It only views compiler as a black-box. More like OpenTuner that can be suitable for any tuning task. Have FPGA results on HPVM2FPGA. No comparison with Ansor, FlexTensor, etc.
[Best Paper] Automatic Generation of Vectorizing Compilers for Customizable Digital Signal Processors
Samuel Thomas and James Bornholt (University of Texas at Austin)
This paper is well-motivated and presents an easily understandable solution. The previous auto-vectorization effort, Diospuros, required manual definition of rewrite rules and used a monolithic egraph solver to construct vectorized code. While this approach mitigated the phase reordering problem by consolidating all rewrite rules, it often led to egraph explosion and sometimes failed to achieve saturation due to the cyclical application of opposing rules. To address these issues, this work introduces a higher level of abstraction by using the ISA to automatically generate rewrite rules. Utilizing Ruler[OOPSLA’21], the researchers generated a set of rewrite rules and organized them into three distinct phases: Expansion (scalar-to-scalar), Compilation (scalar-to-vector), and Optimization (vector-to-vector). They employed a cost function (based on actual hardware performance) $C$ as both a performance evaluator and a clustering function to categorize the rewrite rules into these phases. For instance, if the cost difference between the LHS and RHS of a rule exceeds a certain threshold, the rule is likely classified under the Compilation phase, where it can substantially enhance performance. This method of clustering is particularly clever, transforming a large, unwieldy compilation challenge into smaller, manageable problems.
Session 6C: Optimization of Tensor Programs
This session attracted the highest attendance of the conference, primarily due to the inclusion of tensor compilation topics, particularly PyTorch 2. The room was so packed that many attendees had to stand.
(PS: The session chair was Mangpo Phothilimthana. I just found she had so many well-known works in the PL community, including TpuGraphs, TenSAT and Chlorophyll, but I did not know her before.)
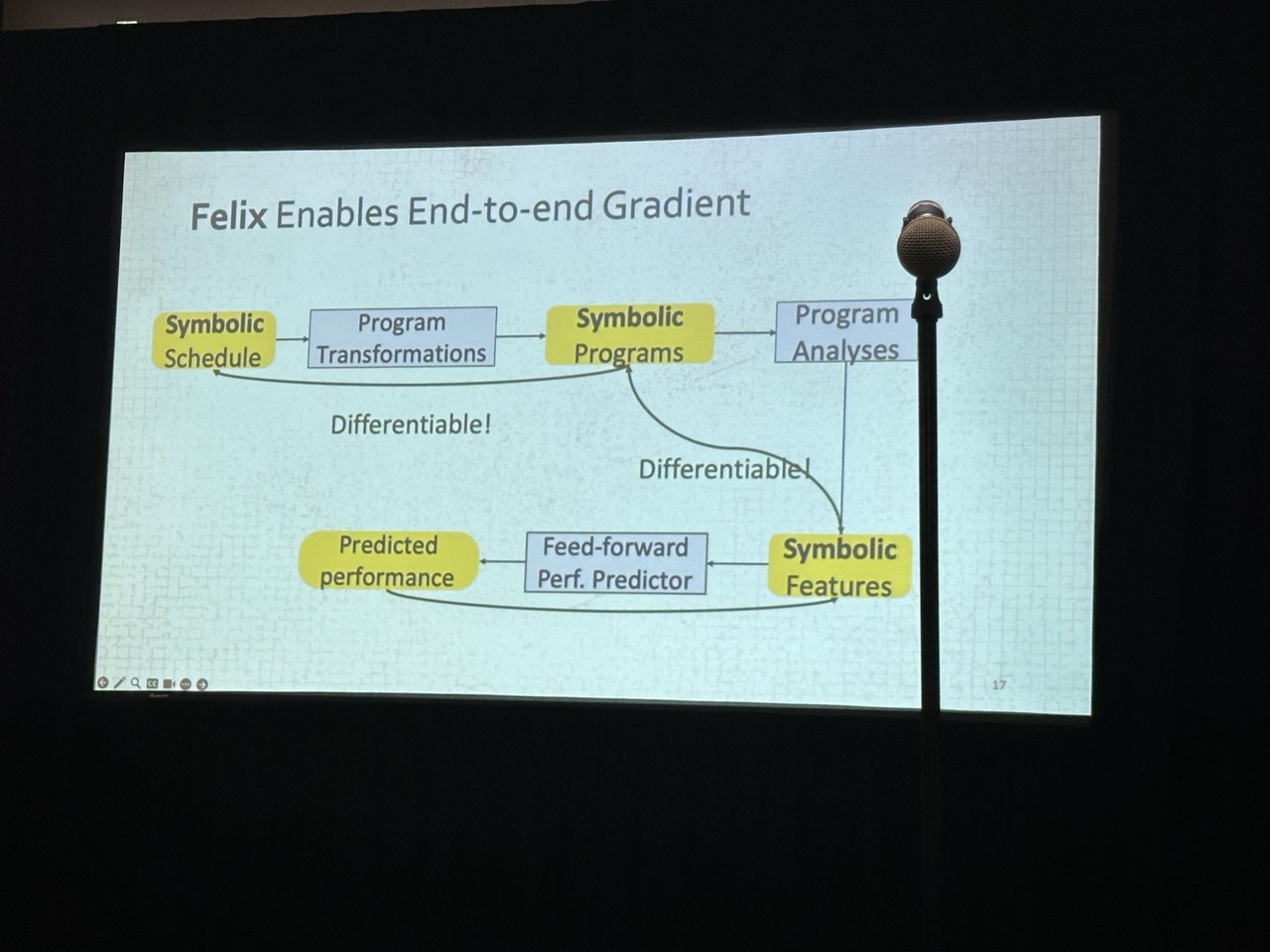
Felix: Optimizing Tensor Programs with Gradient Descent
The idea is to change the discrete variables (e.g., tiling factors) to continuous symbolic representations and use gradient descent to optimize. Felix uses the same template as Ansor, and only speed up the tuning time but does not improve the performance. It did not show why the search space is smooth and rounding does not harm performance (but actually not, some audiences pointed out the search space may have spikes which may change the performance significantly, considering TensorCore – multiplications lead to substantial performance gains).
PyTorch 2: Faster Machine Learning Through Dynamic Python Bytecode Transformation and Graph Compilation
Jason Ansel, Edward Yang, and Horace He (Meta); Natalia Gimelshein (OpenAI); Animesh Jain, Michael Voznesensky, Bin Bao, David Berard, Geeta Chauhan, Anjali Chourdia, Will Constable, Alban Desmaison, Zachary DeVito, Elias Ellison, and Will Feng (Meta); Jiong Gong (Intel); Michael Gschwind, Brian Hirsh, Sherlock Huang, Laurent Kirsch, Michael Lazos, Yanbo Liang, Jason Liang, Yinghai Lu, CK Luk, and Bert Maher (Meta); Yunjie Pan (University of Michigan); Christian Puhrsch, Matthias Reso, Mark Saroufim, Helen Suk, and Michael Suo (Meta); Phil Tillet (OpenAI); Eikan Wang (Intel); Xiaodong Wang, William Wen, Shunting Zhang, and Xu Zhao (Meta); Keren Zhou (OpenAI); Richard Zou, Ajit Mathews, Gregory Chanan, Peng Wu, and Soumith Chintala (Meta)
Most of the techniques have been mentioned in their tutorial.
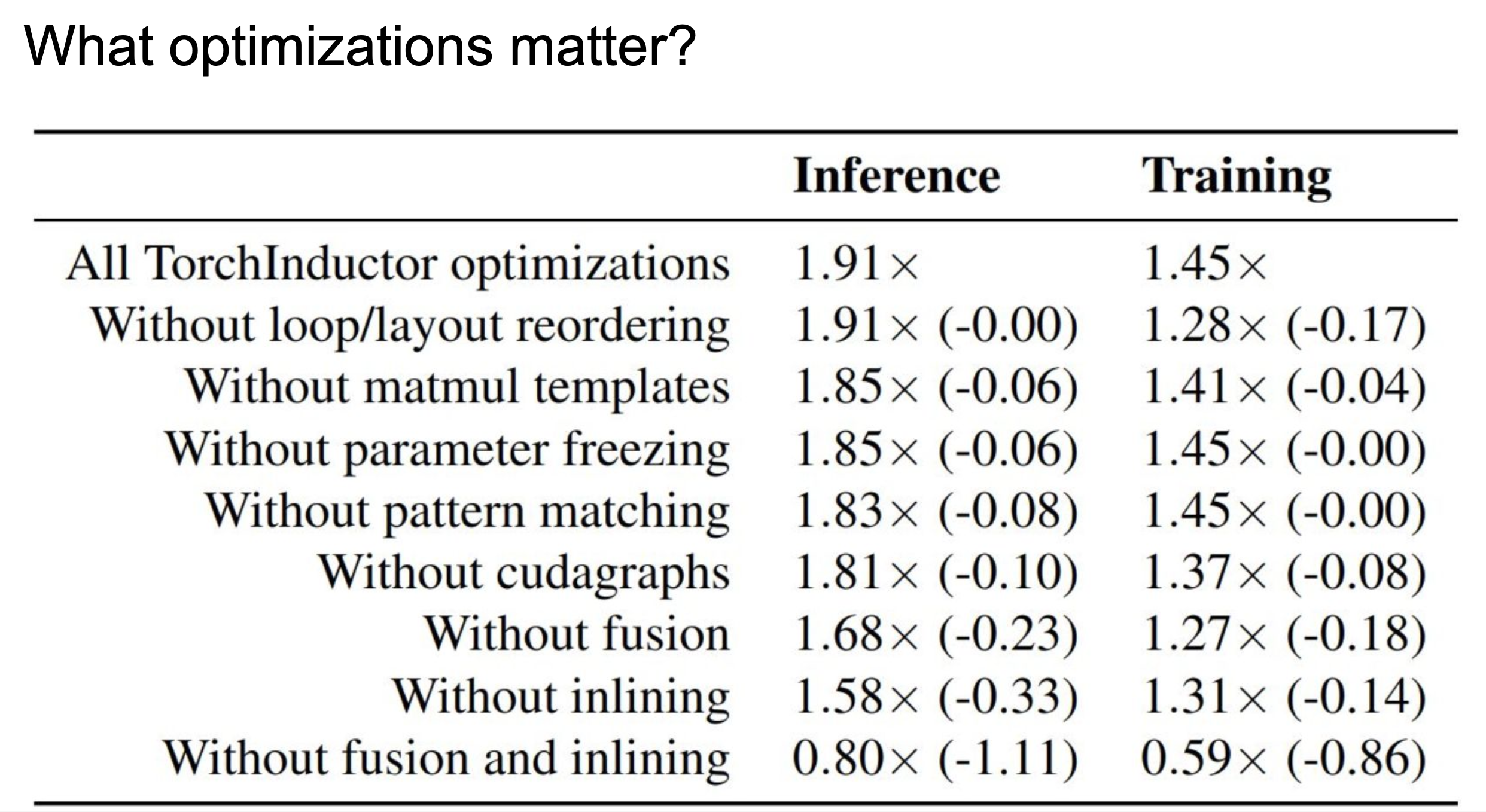
The following figure shows the ablation study of the optimizations performed in TorchInductor. We can clearly see that inling and fusion give the most performance improvement.

Optimal Kernel Orchestration for Tensor Programs with Korch
Muyan Hu (University of Illinois at Urbana-Champaign); Ashwin Venkatram (AMD); Shreyashri Biswas (Carnegie Mellon University); Balamurugan Marimuthu (Sambanova Systems); Bohan Hou and Gabriele Oliaro (Carnegie Mellon University); Haojie Wang and Liyan Zheng (Tsinghua University); Xupeng Miao (Carnegie Mellon University); Jidong Zhai (Tsinghua University); Zhihao Jia (Carnegie Mellon University)
The idea is to decompose NN operators into smaller ones. For example, softmax can be decomposed to reduction and exponentiation. Using the decomposed graph (they call it primitive graph), they can explore more operator fusion opportunities using TASO. They use binary linear programming (BLP) to search the solution, and it takes ~10s for each kernel. Actually decomposition just another kind of rewrite rules. It is not sure why they did not use egraph to solve the problem.
Also, their technique is backend-agnostic, so they can actually leverage the FlashAttention kernel as their backend operator implementation (after kernel fusion).
One unfortunate thing of this talk was that this presentation was arranged after the PyTorch 2 talk, so it was very stressful since their paper also compares with PyTorch 2. In the Q&A session, Jason (the first author of PyTorch 2) came up to ask why Korch performed much better than PyTorch 2, especially in some benchmarks, Korch is 6x faster. He also questioned about the artifact evaluation which does not contain the baseline (i.e., PyTorch) code, which made the talk very embarrassing. Considering Muyan published this paper when he was a undergrad student at UIUC, it was very challenging for him to answer the question.

Excursion and Banquet at USS Midway Museum
After the talks of the second day, ASPLOS arranged an excursion to the USS Midway Museum, which is a retired aircraft carrier. The museum is really big and has lots of aircraft and helicopters on the deck. The banquet was also held on the deck, and the view was really nice. It was a good chance to talk with other researchers and students.


This year selected 6 best paper awards, all of which are listed on the program website. The PC chairs also mentioned how to select the best paper. The process is very clear to all.

Finally three papers were selected as the influential papers, which are the papers that are published 10 years ago and have the most impact on the community. The three papers are:
- Tianshi Chen, Zidong Du, Ninghui Sun, Jia Wang, Chengyong Wu, Yunji Chen, Olivier Temam, DianNao: A Small-Footprint High-Throughput Accelerator for Ubiquitous Machine-Learning, ASPLOS, 2014
- Christina Delimitrou, Christos Kozyrakis, Paragon: QoS-Aware Scheduling for Heterogeneous Datacenters, ASPLOS, 2013
- Abel Gordon, Nadav Amit, Nadav Har’EL, Muli Ben-Yehuda, Alex Landau, Assaf Schuster, Dan Tsafrir, ELI: Bare-Metal Performance for I/O Virtualization, ASPLOS, 2012
It is remarkable that the DianNao series of neural network accelerators has reached its 10-year anniversary. Tianshi and Yunji were pioneers in neural network accelerator research, transitioning it from theory to practical application and ultimately founding the startup Cambrian Technologies.
I was also pleasantly surprised to see Christos Kozyraki in person at ASPLOS. Having read many of his group’s papers during my undergraduate studies, it was a delight to meet him. Additionally, it was a special moment to see him receive an award alongside Christina, a former Cornell professor.
Day 3
Session 10A: FPGAs and Reconfigurable Hardware
FPGA Technology Mapping Using Sketch-Guided Program Synthesis
Gus Henry Smith, Benjamin Kushigian, Vishal Canumalla, and Andrew Cheung (University of Washington); Steven Lyubomirsky (OctoAI); Sorawee Porncharoenwase, René Just, Gilbert Louis Bernstein, and Zachary Tatlock (University of Washington)
They have another workshop paper published in LATTE. Not sure why they did not use egraph for technology mapping in this work, which seems to be very intuitive.
TAPA-CS: Enabling Scalable Accelerator Design on Distributed HBM-FPGAs
Neha Prakriya, Yuze Chi, Suhail Basalama, Linghao Song, and Jason Cong (University of California Los Angeles)
They extend the TAPA framework to support distributed FPGAs. It is interesting to see Jason also started to submit papers to ASPLOS.
Zoomie: A Software-like Debugging Tool for FPGAs
Tianrui Wei and Kevin Laeufer (University of California Berkeley);Katie Lim (University of Washington);Jerry Zhao and Koushik Sen (UC Berkeley);Jonathan Balkind (University of California Santa Barbara);Krste Asanovic (University of California Berkeley)
This kind of tools should be very necessary and useful. Currently it is working at the RTL level. If in the future, we can have an HLS-level debugging tool, it will be even more useful.


Session 11C: ML Training Optimizations
PrimePar: Efficient Spatial-temporal Tensor Partitioning for Large Transformer Model Training
Haoran Wang, Lei Wang, Haobo Xu, Ying Wang, Yuming Li, and Yinhe Han (Chinese Academy of Sciences)
I heard that the techniques described in this paper are highly effective and can significantly enhance performance in distributed training. Unfortunately, the original authors were unable to attend the conference to present their work. Instead, the substitute presenter merely read through the text very quickly, making it difficult for the audience to follow or engage with the content being discussed.
[Distinguished Artifact Evaluation Award] EVT: Accelerating Deep Learning Training with Epilogue Visitor Tree
Zhaodong Chen (University of California Santa Barbara);Andrew Kerr, Richard Cai, Jack Kosaian, and Haicheng Wu (NVIDIA); Yufei Ding (University of California San Diego); Yuan Xie (The Hong Kong University of Science and Technology)
This paper also decompose large operators into smaller ones, and construct epilogue in cutlass to conduct operator fusion and optimize the performance. This work is cool in the way that it targets training instead of inference. The backward graph is also extracted from FX.

Slapo: A Schedule Language for Progressive Optimization of Large Deep Learning Model Training
Hongzheng Chen (Cornell University); Cody Hao Yu and Shuai Zheng (Boson AI); Zhen Zhang (Amazon Web Services); Zhiru Zhang (Cornell University); Yida Wang (Amazon Web Services)
Finally, it was time for my presentation. Despite being scheduled as the last talk in the final session, we still had around 30 attendees—thank you all for coming!
This work was completed during my internship at AWS in Fall 2022, just before ChatGPT was released. At that time, LLMs had not yet gained widespread use, and PyTorch 2.0 had not been released. Our project focused on balancing usability and efficiency in training large models. We aimed to enable users to easily integrate various optimization techniques—including high-performance library kernels and different parallelism schemes—without having to alter the model directly. This approach helps avoid future maintenance difficulties. To achieve this, we decoupled the optimizations from the model definition and encapsulated them within a set of schedule primitives. This design allows us to implement different parallelism schemes using native PyTorch, without the need to rewrite the model to incorporate Megatron modules.

It’s important to note that ASPLOS has a very long cycle nowadays; sometimes, it can take about a year from submission to presentation. Within this timeframe, significant changes can occur. For instance, last year, Megatron underwent major refactoring to enhance its modules, not only to support built-in models but also to facilitate their integration into other models. Meanwhile, PyTorch released version 2.0, further enabling users to leverage compiler techniques in their models.
Final Remarks
This year’s ASPLOS featured an extremely packed schedule. For future iterations, it may be beneficial for the program committee to consider a more balanced schedule. Extending the conference by an additional day could prevent sessions from running as late as 6:30 PM, which would likely improve the overall experience. Surprisingly, this year’s event did not include sponsor booths, which was also an unusual deviation from the norm.
Despite these quirks, the conference was highly successful, and I am eagerly anticipating next year’s ASPLOS.