Hongzheng Chen Blog
Allo:用软件方法论设计硬件加速器
May 27th, 2024 0从我写完上一篇 blog《剖析 FPGA 加速大模型推理的潜力》之后已经过了差不多半年,这半年我们看到了很多取代 Transformer 的尝试,也看到了各类 LLM 加速器层出不穷。我们在论文中所提倡的 model-specific spatial architecture 也确实有公司进行实操了,Groq 就用了他们几百张加速卡,做了一个纯 dataflow 的 in-SRAM 加速方案。虽然成本令人望而却步,但他们超高的性能也从侧面反映了最大程度减少内存访问的优势。
除了可行性的问题,我们收到的最多的就是关于开发成本的评论,FPGA / ASIC 固然好,但是开发周期非常长,所以哪怕我们论证了这种 model-specific acceleration 的可行性,如果不能方便快速地将新的模型综合成高效的硬件加速器,那也相当于没用。这个问题本质上是怎么提升程序员的生产力(productivity),这也是我 PhD 期间一直在探索的主线项目——希望重新塑造硬件的编程/设计方式,来让更多的人受益于最新的硬件。而 Allo 正是我们在加速器设计上做了很多年的工作的一个里程碑,也是我们对未来编程模型的一个展望。
这几年很火的一个概念是硬件彩票(hardware lottery)1——很多时候并不是因为某个软件算法或者模型设计得有多么好所以才取得了巨大的成功,而是因为恰好那个算法适配了特定硬件的架构所以才取得了成功。Efficient ML 里面大量的工作都是基于此开展的,包括各种 quantization / pruning 的方法(如利用 TensorCore 加速),还有 hardware-aware 的算法(如 FlashAttention),其实都是在让这些模型或算子更好地适配 GPU 的架构。这是大多数人选择的路径,那么反过来,有没办法让硬件去更好地适配模型呢?
这正是我们这个工作想要完成的内容——为每个领域的每个应用快速定制高性能的专用加速器。
除了现在正在风头的 LLM,这两年跟做生物、物理、金融各个方向的同学聊天,就会发现事实上每个领域都有它需要加速的应用,包括量子计算、脑机接口、高频交易、基因组学等等,这些领域都需要有专门的加速器,但是往往因为需求不够大没有办法直接流片。CPU 往往是串行的,GPU 又很难确保应用足够规整能够轻松实现大规模并行,那 FPGA 其实就是一个很好的 target。除了航空航天这种高精尖领域一定需要 RTL 进行精细控制,其他很多领域涉及到的问题其实都可以通过高层次的编程模型解决。你不能期望一个做生物或者物理的学生去学习怎么写 Verilog,所以有高层次的编程框架非常重要。
软件定义硬件(software-defined hardware)也并不是一个新鲜的概念,这些年我们也看到不少 RTL 层级以上的编程语言或编程框架,但我们实际使用它们进行硬件设计的时候就会发现,很多项目只能算是一个实验原型,不说到实际落地,仅仅是上板测试可能都有非常大的鸿沟。典型例子像 hls4ml2 宣称有很多欧洲的研究机构采用他们的框架,但是实际用下来就会发现其性能非常糟糕,一旦问题稍微大一点或者复杂一点就无法使用了。ScaleHLS3 算是这几年做得最好的高层次综合(High-Level Synthesis,HLS)框架了,对于单一 kernel 它的 DSE 引擎可以做得非常完美,但一旦考虑更大的神经网络,它生成出来的代码往往无法上板执行,因为资源利用已经远超板上可利用的资源。另外像 Filament4 和 Dahlia5 这些在之前 PLDI 发过的 paper,都 present 了非常好的idea,但是实际上针对的 benchmark 都非常小,很难看出其可扩展性。
因此我们希望重新设计一个新的加速器设计语言(Accelerator Design Language,ADL),能够真正解决硬件加速器快速实现与落地的问题。
设计原则
在重新设计编程语言的时候,我们列出了几点原则:
首先要拥抱Python原生生态(Pythonic),现在深度学习这么火爆,人均都会写 Python,因此拥抱Python 是最简单快捷能让其他领域的人也用起来的方式。之前的一些 ADL 如 Spatial6 嵌入在 Scala 里面需要另外学一门新的语言,同时生成 Chisel code。不仅要学习宿主语言,而且前后端都需要学习新的嵌入语言,相当于三种语言同时学,就算是硬件工程师我觉得也非常难学会并利用其设计出可用的加速器。而相对底层一些的 Chisel 还有 Calyx 这些新的硬件编程语言(Hardware Design Language,HDL)的确解决了 Verilog 一些语言特性上的问题,但它们本质上是为让硬件工程师更方便地设计硬件,而不是让写软件程序的人也能够参与进来设计他们领域的定制化加速器,所以并不合适。
第二个原则是可维护性(maintainability)。我们在实际用 HLS 搭建 LLM 加速器的时候就会发现,虽然用 C++ 来写算子已经比较方便了,但设计的空间太大,可以做的优化太多,每次改动都需要重新拷贝原有的代码进行修改,最后代码会被改得面目全非,这非常不利于后续的维护。我们设计的高层次语言也不希望用户在写了一个应用之后针对不同平台优化会把原来的代码大量改动,因此我们采用了跟 TVM / Halide 一样的方式,提出了调度语言(schedule language)来对算法和优化进行解耦(decoupling),从而实现单一算法实现多种平台优化。
最后一个原则是可组合性(composability),这也是我们认为设计硬件加速器一个非常重要但之前的工作都没有解决的问题。对于大型的硬件设计,更加推崇的方案应该是自底向上的设计模式,每个 team 可以设计自己的模块,在每个模块都优化验证没有问题后,再将这些优化好的模块组合起来。因此我们想要的语言,应该不仅仅是让调度原语(schedule primitive)之间可以相互组合,更重要是让多个模块的调度可以相互组合,同时也可以整合一些外部已经写好的高性能算子或者IP核。
综合上述三点,我们设计了一个新的加速器设计语言 Allo7,它接受Python写的kernel作为输入,通过自己的语法解释器(parser)和类型系统(type system)生成类型注解的抽象语法树(Typed AST)。中端我们选择接入 MLIR,我们实现了自己的 dialect,所有的调度原语在 MLIR 层面也都有对应,这可以更加方便地扩展不同的前端和后端;最后的代码生成我们主要针对 CPU 和 FPGA,CPU 这边走的是 LLVM JIT,而 FPGA 这边则是生成 HLS C++ 代码,然后调用 Vivado HLS 进行综合生成最终的加速器。
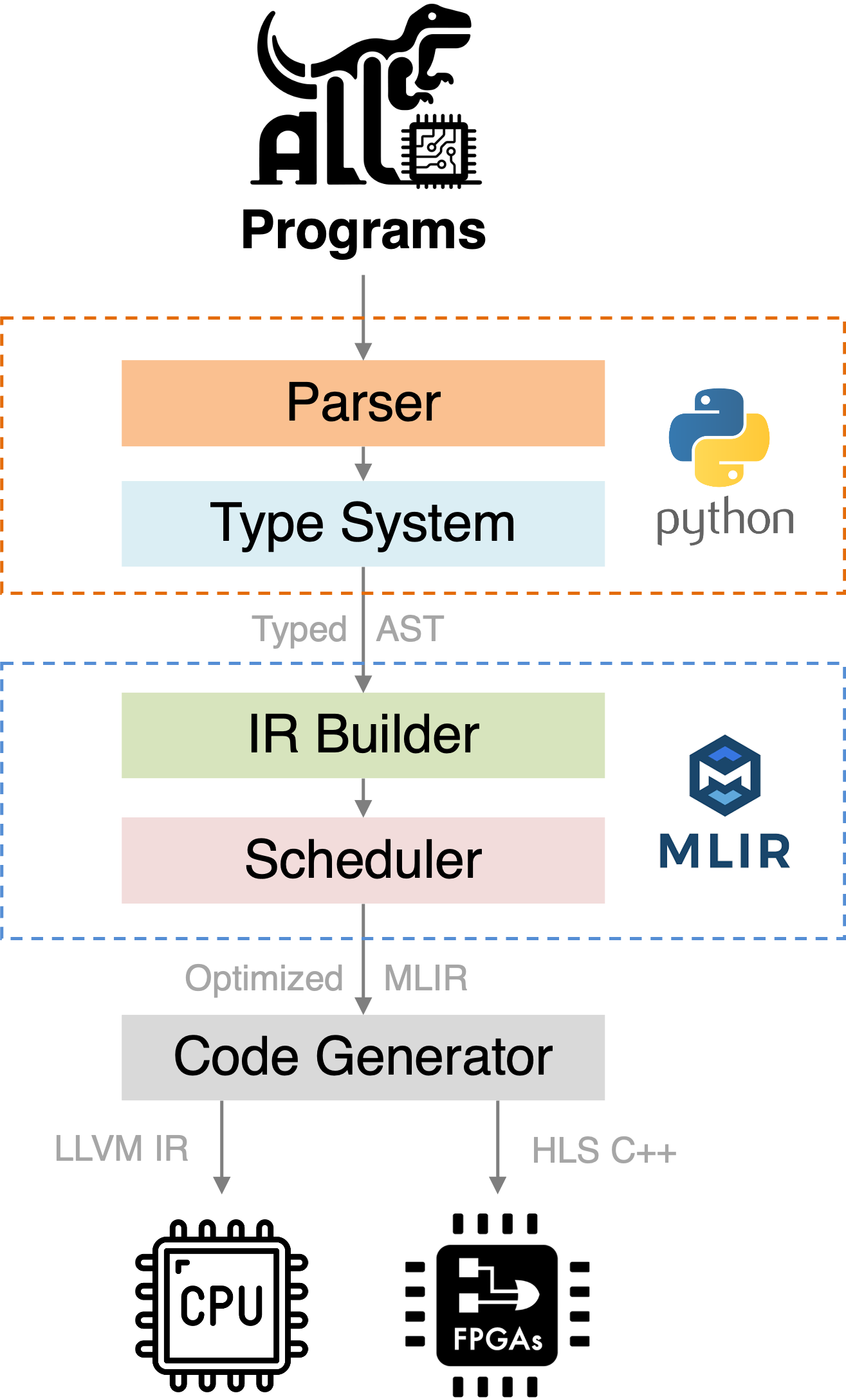
硬件优化解耦
接下来我们会具体看一下 Allo 的编程方式。现在的深度学习框架和编译器基本上都是基于 Python 的嵌入式编程语言(eDSL),但是以什么样的编程范式来定义算子也有不同的选择。早年 TVM8 用声明式(declarative)的写法去定义张量计算,但这种 Tensor Expression 的写法现在在 TVM 里也基本不怎么使用了,取而代之的是 TensorIR9 这种更偏命令式(imperative)的写法,究其原因就是命令式编程更容易对 TensorCore 这种硬件架构进行微操。类似的,之前我们在与 Intel 合作设计类似于 VTA 的指令集架构10时就会发现用原来的 TVM 编程模式是相当难描述控制流的。因此 Allo 从一开始就要支持各种不同的写法,而不仅仅是常见的张量程序。我们采用了跟 Mojo 类似的做法去支持原生的 Python 语法,但需要用户显式地提供类型信息。这样做的好处是用户有最大的灵活度,如果有些优化不好通过我们的编译器实现,那按照原来 Python 的写法也能够非常直接地将算法实现出来,哪怕将其作为一个 MLIR 的 Python frontend 也是很好的。同时我们也尽可能将各种编译器的设施包括类型系统、rewrite pass 的书写都放到 Python 层,这样出了什么问题用户也可以更加容易定位并 debug。下图展示了一段 Allo 实现的 GEMM 代码,可以看到其跟生成的 MLIR 代码是一一对应的,最后生成的 HLS C++ 代码也基本维持一样的结构。

正如前文提到的, Allo 同样采用了算法调度解耦的方式,但相对之前的工作在两个方面进行了提升:渐进优化(progressive optimization)和可验证调度(verifiable schedule)。
传统的 Halide / TVM 采用的是 monolithic lowering 的方式,需要等到所有的原语写完之后用一个 compiler pass 来对程序进行lowering;现在的调度语言比如新一代 TVM 基于的 TensorIR,以及MIT 提出的硬件编程语言 Exo11,每个优化原语(primitive)都可以单独作用,这样会更方便检查。因此 Allo 采用了类似的方案,每一步转换都进行的是 program rewrite,每一步操作之后的模块都可以被直接打印出来检查(每一步后面可以直接接print(s.module),然后就可以得到类似上图的 MLIR 代码)。
下图展示了一个用 Allo 将一个不加优化的 GEMM kernel 转化为脉动阵列(systolic array)的例子,这里我们会先在计算单元与片下内存之间建立一级 cache,将计算单元完全展开之后,再对内存进行划分(确保 memory bank 足够可以并行访问),最后再将 buffer 全部改成 FIFO 实现。如果之前有尝试过 HLS 或者 Verilog 脉动阵列的实现就会知道实现起来非常麻烦,会涉及到几百甚至上千行代码的优化,但是利用 Allo,我们用十行以内的调度代码就实现复杂的脉动阵列架构。同时注意到这里每一步变换都是合法的,意味着每一步后面都可以将 MLIR 模块打印出来并检查,同时每一步变换后的模块与原来不加优化的模块的功能是等价的。
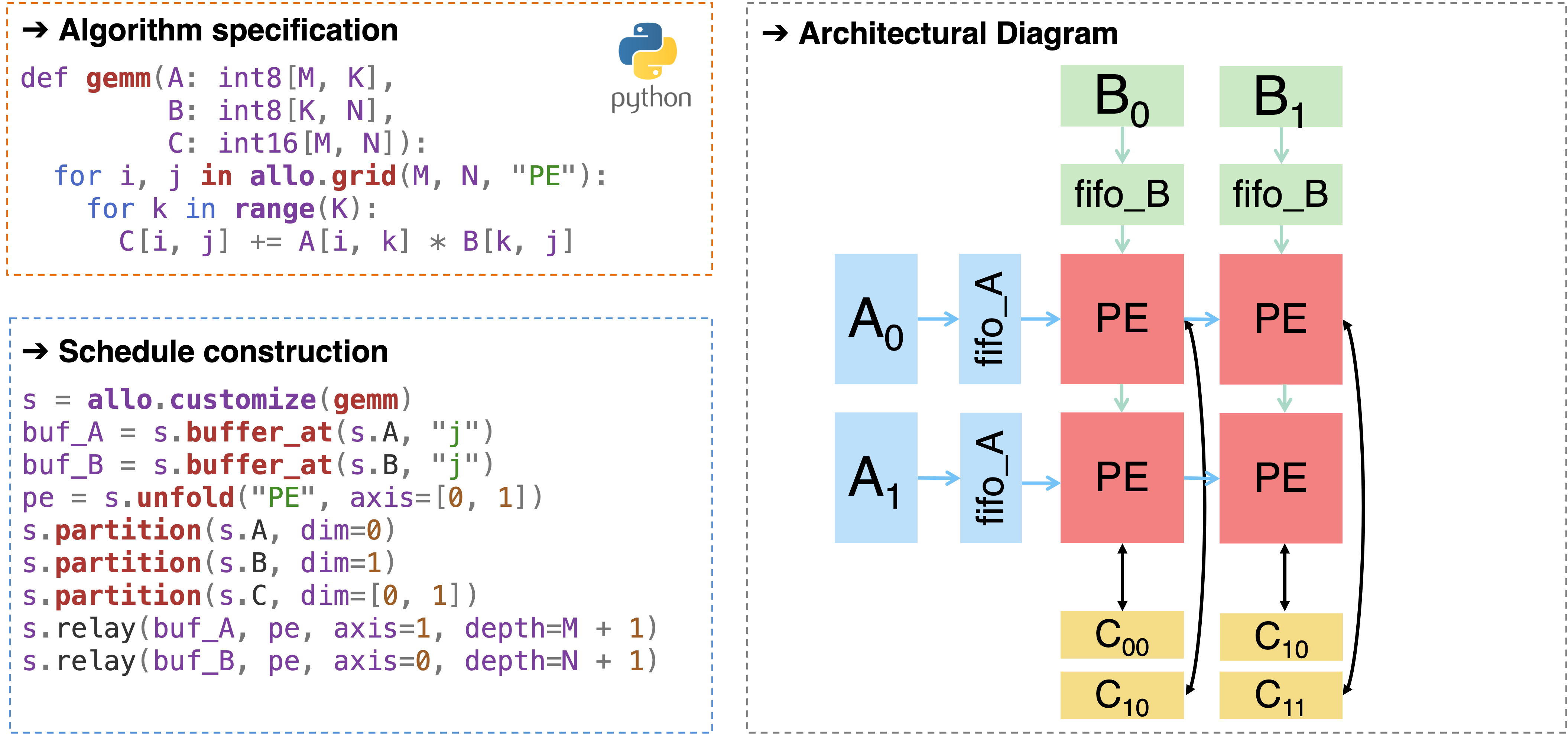
为了说明其等价性,我们比 TensorIR 更进一步,通过形式化验证的方式能够确保每一个原语做的变换都是正确的。这个 verifier 会对两个 C++ 程序构建计算图并判断图同构,其中我们做了大量优化从而实现对大型设计分钟级别的验证。这个工作12获得了 FPGA’24 的 Best Paper,我们也将其整合进了 Allo,对变换前后的调度分别生成 C++ 程序从而判断两者是否等价。
而将验证步骤从 RTL 级别上移到高级编程语言的好处是可以提前暴露硬件可能存在的问题,从而缩短硬件设计时间。现在的硬件设计迭代周期这么长很大一部分原因是后端的电子设计自动化(Electronic Design Automation,EDA)的部分太过耗时13,如果每次都需要下推到生成二进制流并上板才能知道一个设计是否正确的话那就太过麻烦了。但如果在更前端的部分已经能够验证结果并且得到高效的设计,那进行后面耗时的综合流程也只是一次性开销。
自底向上组合
除了单一算子的优化,对于大规模的硬件加速器,更加关键的问题是怎么将小的模块组合成大的模块,这是之前的工作都没有探讨过的问题,但是会直接影响到编程框架的可扩展性。这些模块可能会有不同的interface,当一个模块组合进来的时候可能会导致产生全局的影响(因为这个函数变量在不同地方都会有使用,同时函数也会有很深的嵌套),怎么确保全局函数签名(function signature)的一致性,这也是这个work 最有趣的地方。
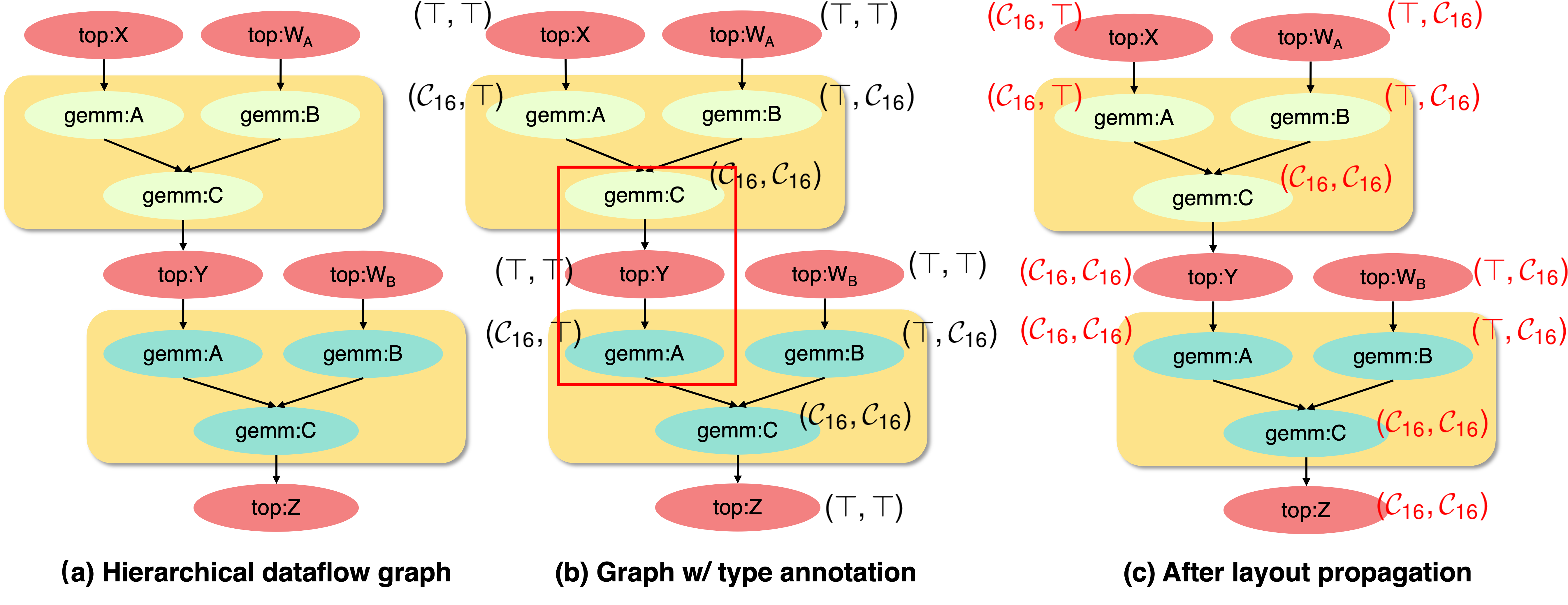
下面给了一个两层神经网络例子,这在现在的 Transformer 模型的 FFN 层非常常见。假设我们先前已经优化好了一个 GEMM kernel,采用的就是上面脉动阵列的优化模式,可以看到在 kernel 的定义中我们将输出矩阵C给完全划分了(s.partition(s.C, axis=[0,1])),对应到下图的代码则是矩阵Y。但是Y作为第二个 GEMM 的输入矩阵,只要求沿第一个方向进行了划分(s.partition(s.A, axis=0)),所以这里会产生一个冲突,在实际实现中一方面在 MLIR 层的类型标注会对应不上,另一方面也可能会导致可能的性能下降(我们的论文中给出了具体的例子),所以确保 caller 和 callee 的接口一致性是非常重要的。
def top(X: int8[M, K], W_A: int8[K, N],
W_B: int8[N, K], Y: int8[M, K]):
Y: int8[M, N] = 0
Z: int8[M, K] = 0
gemm(X, W_A, Y)
gemm(Y, W_B, Z)
return Z
本质上这就成了深度学习编译器中一个经典的 layout transformation 的问题,如果 layout 对得上那性能就会好,否则就会有转换开销,只不过这里的 memory layout 变成了固定的可被 partition 的几种形态。
而为了判断函数签名与实现是否一致,这不就是类型检查做的事情吗,所以我们完全可以为 memory layout 创建专门的类型系统!对于变量的每一个维度,我们可以定义
$\hat{\tau}:=\bot\mid \mathcal{C}_{\alpha}\mid \mathcal{B}_\alpha\mid \top$
其中 $\bot$ 代表这个维度的内存被完全划分(complete partition)了,$\top$ 代表这个维度的内存不被划分,$\mathcal{C}_\alpha$ 代表这个维度每 $\alpha$ 个元素采用循环划分(cyclic partition),$\mathcal{B}_\alpha$ 代表这个维度每 $\alpha$ 个元素采用分块划分(block partition)。同时我们可以建立两个子类型(subtyping)关系,
\[\begin{aligned} \bot<:\mathcal{C}\_\alpha<:\top\\ \bot<:\mathcal{B}\_\alpha<:\top \end{aligned}\]这个的直观理解是如果一个函数期望一个变量拥有至少 $\kappa$ 的内存并行度,那传入一个变量拥有比 $\kappa$ 更高的并行度必然也是可行的。比如一个函数只期望变量被循环划分16份,但是现在这个变量被完全划分了,也就是拥有更多的 memory bank,那原本可以执行的并行算法必然也可以执行(只是可能会有更大的存储开销)。
事实上这些 layout 可以构建成一个格(lattice),因为完全没有并行度那就是没有划分($\top$),而最高并行度即每个元素都是一个存储单元那就是完全划分($\top$),这两者都只有一种情况,而其他的循环划分及分块划分都可以与它们构成子类型关系。
那么我们想要做的“确保函数签名一致性”或者 layout propagation 实际上就等价于在这个类型系统里做类型推断。而遇到 type 不同的情况,我们会尝试去调和它们,比如一个变量的并行度是2,期望的并行度是3,那么将其调和的方式就是将并行度改成6,这样内部函数实现依然可以维持不变,也就是实现格上的“最小公倍数”(所谓的 meet 算子 $\sqcap$)。
下一步则是将类型信息进行全局传播。类型推断通常需要使用 SMT solver 来求解,但事实上我们的问题有着非常好的结构,所以我们可以换一种方式解决。为了更直观地表达函数变量类型的差异,我们提出了层次化的数据流图(hierarchical dataflow graph),保存了每个函数参数的信息,用<function>:<argument>这样的形式来区别每个变量定义的位置,那么在这上面做的类型推断就等同于静态程序分析的 Worklist 算法。再加上前面提到的格的性质,可以证明类型推断的时间复杂度是线性的,所以我们的组合是类型安全同时非常高效的。
在实际编程界面上,如果用户已经优化好了一个算子op,并且这个算子有对应的调度s_op,我们将其整合入顶层函数调度s_top的方法是
s_top.compose(s_op)
这个.compose()原语也可以作为 IP integrator 来整合外部优化好的 HLS 算子,其统一函数签名的方式也跟上述描述的方式一样。同样的传播算法也可以用在流类型(stream type)上来确保 FIFO 的一致性。
实验结果
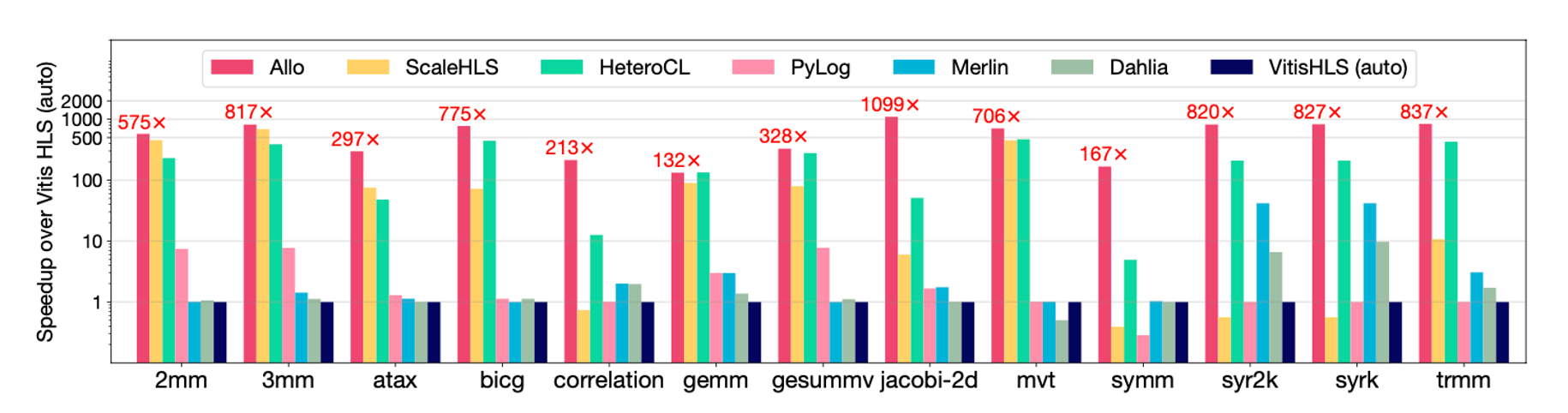
我们在 PolyBench 跟现有的 HLS 工具和其他的一些 ADL 进行比较,结果可以看到 Allo 都能在其中取得最好的性能。这里主要原因是其他很多 baseline 如 ScaleHLS 只是搜索了 compute customization 里的 hyperparameter,但很多的硬件优化其实都跟 memory 相关,因此如果没有创建良好的内存层级结构是没有办法真正实现高性能的。我们也开源了artifact,并且这些实验也能够被完全 reproduce,欢迎进行尝试。
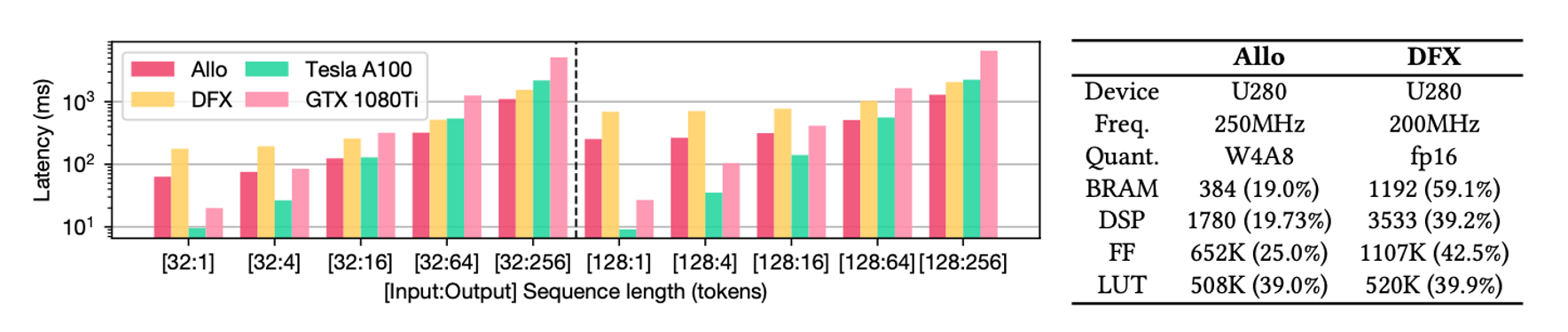
另外我们也实现了之前FCCM paper14中的一个设计点,用 Allo 重新设计了 GPT2 的加速器,然后也取得了类似的性能。关于这个加速器的具体细节可以参见之前的知乎文章。
讨论
当然调度语言不是万能的,实际上调度语言只是将编程的负担从写 optimization 转移到了写 schedule 上。从 TVM 这几年自动调度的发展来看,最开始 AutoTVM 是 template-based 的方案,然后 Ansor15 完全弃用,再到 MetaSchedule16 则是半自动的方案,用在 mlc-llm 里,其实一直都在寻求手工与自动之间的权衡。Allo 下一步要做的也是会提供更加自动化的方案,但是相比起 TVM 的方式,我们希望我们的调度能够做的更加透明,让用户可以在自动搜索调度基础上进行改动。我在 PLDI SRC 上也会提到另外一个 schedule reconstruction 的问题,从底层优化代码逆向工程出调度原语,这也会给之后的调度提供更有效的样例。
另外一方面,Allo 也会加入更多的后端,我们有些同学在做 Calyx 和 CIRCT 的 support,这会替换商用的 HLS toolchain;也有一些同学在看 PIM 和 ASIC 相关的 device,因此这将不仅仅是 FPGA,也会有更多有趣的东西。
最后我们也打算建立完整的 build system,HLS 是一个大而全的工具,但其实底层的信息可以不断暴露给上层从而实现更好的性能,参见 AutoBridge17,如果可以将 placement 的信息向上传递,那上层编译器能够探索优化的空间也就更大,同时也能够更好实现“设计上移”这个目标。
后记与致谢
这个工作从我入学开始就开始做,一直做了快三年时间,中间 TVM 已经发展了几代,而大量基于 MLIR 的编程框架也层出不穷,中间也无数次想要放弃这个项目,但好在有 Niansong(我们的共一作者)以及实验室很多的本科生小伙伴们一起努力,最终才将整个框架呈现出来。
Allo 的前身是 HeteroCL18,一个完全基于(古早版本)TVM 的硬件加速器编程框架。HeteroCL 最开始的愿景是好的,但是因为种种原因没有继续融入 TVM 的生态,最终也没有得到很好的发展。我们一开始也仅仅是在 HeteroCL 基础上进行改进,重写了整个 backend,将基于 TVM 的编译框架迁移到了 MLIR。但后来发现如果还是采用 TVM tensor expression 的写法,很多问题还是没有办法解决,因此我们又推翻整个frontend 进行重写。中间也跟叶老板@yzh讨论过多次 TVM 的问题,叶老板也很大程度上促进了我们对整个框架进行重写并提出自己的编程语言。Allo 或许不是从0到1的突破,很多 idea 也许并不 novel,但是我们真心希望能够以此实现敏捷加速器设计从1到100的跨越,我们也非常希望能让更多不同领域的人用起来。
虽然现在很多人可能已经不玩知乎了,但是不可否认,我的很多 PL 知识都是从知乎上学的,很难想象我利用在知乎现学现卖的知识居然发了 PLDI。@雾雨魔理沙 曾说过“PL的赞歌是组合的赞歌”,这几年做编程框架也愈发感受到组合性的重要性,如果没有办法将各种东西(e.g., 高性能算子、调度实现)方便地组合到一起,那编程框架很大程度上是闭塞的。南大的李樾和谭添老师@甜品专家 B站的课程也是启蒙我静态程序分析的一个重要来源,还有@陈天奇 老师的 TVM 和后续一系列工作也给予了我们大量的启发。
这次 PLDI 的投稿经历也是非常有趣可以载入史册了,实际论文可能只花了10天的时间完成,一开始还害怕20页的论文会太多,后来发现是内容太多根本塞不下。这10天时间里还大改了两版,把类型系统的部分重新理了一遍。Adrian在这其中也功不可没,虽然我们提前一周就将论文初稿发给他了,但他到最后一天才有时间看,以至于我们在截稿前一天还在大改类型系统的叙述和证明。PLDI 也是我近几年投的 conference 里面体验最好的,每个 reviewer 都非常负责。而且 PL 的 reviewer 都非常“学究”抠用词,比如评价我们某句话的表述非常 wishy-washy 因为用的词是“can”而不是“will”,还有纠正我们对“has become”和“has been”的错误用法等等。我们第一轮审核还在 borderline 附近徘徊,之后把 reviewer 的问题都 fix 之后,第二轮审核就直接到 strong accept 了,这也是非常难得的一次投稿就中的经历。
最后的最后,感谢阅读这么长的文章,欢迎大家一键三连,cite我们的工作:)
Hongzheng Chen, Niansong Zhang, Shaojie Xiang, Zhichen Zeng, Mengjia Dai, and Zhiru Zhang, Allo: A Programming Model for Composable Accelerator Design, ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI), Jun. 2024.
参考文献
-
Sara Hooker, “The Hardware Lottery”, https://hardwarelottery.github.io/ ↩
-
Farah Fahim et al., “hls4ml: An Open-Source Codesign Workflow to Empower Scientific Low-Power Machine Learning Devices”, TinyML, 2021. ↩
-
Hanchen Ye, Cong Hao, Jianyi Cheng, Hyunmin Jeong, Jack Huang, Stephen Neuendorffer, Deming Chen, “ScaleHLS: A New Scalable High-Level Synthesis Framework on Multi-Level Intermediate Representation”, HPCA, 2022. ↩
-
Rachit Nigam, Pedro Henrique Azevedo De Amorim, Adrian Sampson, “Modular Hardware Design with Timeline Types”, PLDI, 2023. ↩
-
Rachit Nigam, Sachille Atapattu, Samuel Thomas, Zhijing Li, Theodore Bauer, Yuwei Ye, Apurva Koti, Adrian Sampson, Zhiru Zhang, “Predictable Accelerator Design with Time-Sensitive Affine Types”, PLDI, 2020. ↩
-
David Koeplinger, Matthew Feldman, Raghu Prabhakar, Yaqi Zhang, Stefan Hadjis, Ruben Fiszel, Tian Zhao, Luigi Nardi, Ardavan Pedram, Christos Kozyrakis, Kunle Olukotun, “Spatial: A Language and Compiler for Application Accelerators”, PLDI, 2018. ↩
-
取这个名字是因为老板觉得 allosaurus 很有趣,所以取了其前缀,代表不同的硬件。 ↩
-
Tianqi Chen, Thierry Moreau, Ziheng Jiang, Lianmin Zheng, Eddie Yan, Meghan Cowan, Haichen Shen, Leyuan Wang, Yuwei Hu, Luis Ceze, Carlos Guestrin, Arvind Krishnamurth, “TVM: An Automated End-to-End Optimizing Compiler for Deep Learning”, OSDI, 2018. ↩
-
Siyuan Feng, Bohan Hou, Hongyi Jin, Wuwei Lin, Junru Shao, Ruihang Lai, Zihao Ye, Lianmin Zheng, Cody Hao Yu, Yong Yu, Tianqi Chen, “TensorIR: An Abstraction for Automatic Tensorized Program Optimization”, ASPLOS, 2023. ↩
-
Debjit Pal, Yi-Hsiang Lai, Shaojie Xiang, Niansong Zhang, Hongzheng Chen, Jeremy Casas, Pasquale Cocchini, Zhenkun Yang, Jin Yang, Louis-Noël Pouchet, Zhiru Zhang, “Invited: Accelerator Design with Decoupled Hardware Customizations: Benefits and Challenges”, DAC, 2022. ↩
-
Yuka Ikarashi, Gilbert Louis Bernstein, Alex Reinking, Hasan Genc, Jonathan Ragan-Kelley, “Exocompilation for productive programming of hardware accelerators”, PLDI, 2022. ↩
-
Louis-Noël Pouchet, Emily Tucker, Niansong Zhang, Hongzheng Chen, Debjit Pal, Gabriel Rodríguez, Zhiru Zhang, “Formal Verification of Source-to-Source Transformations for HLS”, FPGA, 2024. ↩
-
这也不是一个容易解决的问题,后端EDA涉及的流程实在太多,每个阶段的优化都够一个 PhD 吃五年了,而且还涉及到每家硬件厂的专利,所以硬件敏捷迭代目前的最优解只有将所有设计流程上移,尽可能减少后端迭代的次数。 ↩
-
Hongzheng Chen, Jiahao Zhang, Yixiao Du, Shaojie Xiang, Zichao Yue, Niansong Zhang, Yaohui Cai, Zhiru Zhang, “Understanding the Potential of FPGA-Based Spatial Acceleration for Large Language Model Inference”, ACM Transactions on Reconfigurable Technology and Systems (TRETS), 2024. (FCCM’24 journal track) ↩
-
Lianmin Zheng, Chengfan Jia, Minmin Sun, Zhao Wu, Cody Hao Yu, Ameer Haj-Ali, Yida Wang, Jun Yang, Danyang Zhuo, Koushik Sen, Joseph E. Gonzalez, Ion Stoica, “Ansor: Generating High-Performance Tensor Programs for Deep Learning”, OSDI, 2020. ↩
-
Junru Shao, Xiyou Zhou, Siyuan Feng, Bohan Hou, Ruihang Lai, Hongyi Jin, Wuwei Lin, Masahiro Masuda, Cody Hao Yu, Tianqi Chen, “Tensor Program Optimization with Probabilistic Programs”, NeurIPS, 2022. ↩
-
Licheng Guo, Yuze Chi, Jie Wang, Jason Lau, Weikang Qiao, Ecenur Ustun, Zhiru Zhang, Jason Cong, “AutoBridge: Coupling Coarse-Grained Floorplanning and Pipelining for High-Frequency HLS Design on Multi-Die FPGAs”, FPGA, 2021. ↩
-
Yi-Hsiang Lai, Yuze Chi, Yuwei Hu, Jie Wang, Cody Hao Yu, Yuan Zhou, Jason Cong, Zhiru Zhang, “HeteroCL: A Multi-Paradigm Programming Infrastructure for Software-Defined Reconfigurable Computing”, FPGA, 2019. ↩