Hongzheng Chen Blog
从一到万的屠龙魔法书(2):Dato:面向数据流架构的Task编程模型
Jan 20th, 2026 0记得23年我们第一次推 PD 分离 + dataflow 架构,很多公司联系过我们但最后都觉得太 aggressive 而不了了之。两年多后,PD 分离已经成了工业界的事实标准;NVIDIA 花了目前最大手笔收编 Groq,随即 OpenAI 宣布跟 Cerebras 合作,则是直接印证 dataflow 就是未来趋势。
之所以要用 dataflow,核心原因还是 LLM 的瓶颈并不是计算本身,而是访存(最近存储芯片价格暴涨也是一个原因)——如何高效地在不同计算单元间搬移数据,决定了系统的最终性能。如果可以把更多的数据流动放在片上,那就可以做到更好的算存 overlapping 从而减少片外的数据搬运和能耗。
- TLDR: 我们提出了 Dato1,一个将数据通信和分片作为一等类型的 Task 编程模型,在 AMD NPU 上首次实现了高性能的 FlashAttention,并在 FPGA 上生成了接近理论峰值的脉动阵列。
- 论文链接:https://arxiv.org/abs/2509.06794
- 代码链接:https://github.com/cornell-zhang/allo (Dato 其实是 Allo v2,希望大家多多支持关注!)
- 测试链接:https://github.com/cornell-zhang/allo/tree/main/tests/dataflow
- 原文链接:https://chhzh123.github.io/blogs/2026-01-20-dato/
数据流加速器(如 Google TPU、AMD Ryzen AI NPU、Cerebras WSE)通过硬件 FIFO、片上网络(NoC)和分布式计算单元,让数据像流水一样在计算单元间直接流动,从而大幅降低对片外带宽的依赖。然而,现有对这些加速器的编程接口大致可以分成两大类:
- 底层的编程模型如 IRON(相当于 NPU 版的 CUDA),需要手动管理 FIFO 和 DMA,写简单的 GEMM 都极其复杂;调度语言像 Exo 和 Allo 有一些调度的原语,但前端依然需要用 array 的编程模式,导致映射到数据流硬件上的 FIFO 会产生不匹配。
- 高层的编程模型如 Triton 和 ARIES(NPU 版 Triton),隐藏了通信细节,难以表达跨核、跨任务的数据流,导致性能没有办法打满(这也是后来 Triton 要推 Gluon 的一个很大原因)。
为了解决这两种编程模型各自的问题,Dato 的核心思想很直接:我们把数据流架构中最关键的 “数据怎么流” 和 “数据怎么摆” 都变成编程语言里的一等类型。这样一来,开发者既能像写普通 Python 一样描述计算,又能通过类型系统直接声明数据如何在硬件上流动与分布,编译器则负责把这种“虚拟映射”转化为高效的物理布局。
数据流架构基础
现在大厂自己设计的加速器如 Google TPU、AWS Trainium 其实都是基于同样的脉动阵列(systolic array)的架构,大量的数据在片上不同处理单元(PE)之间流动,从而形成数据流。事实上正如上篇 blog 所说,NVIDIA的GPU也在往数据流的方向发展,Hopper 和 Blackwell 就是明显的趋势。
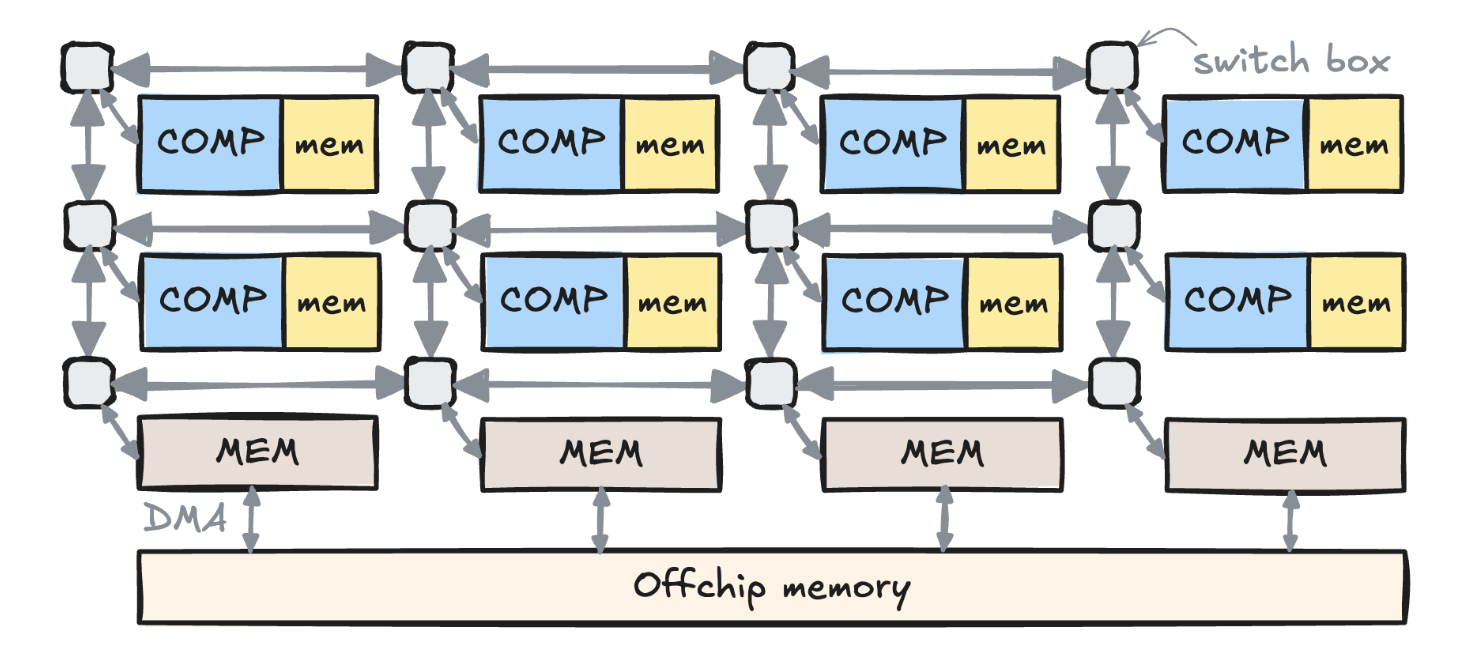
而在我们这个工作中更加关心可重构(reconfigurable)的数据流架构,比如AMD AI Engine、Cerebras WSE 还有 Sambanova RDU,这些架构里面的数据通路都是可以在编译时控制的,比如可以明确指出某个PE需要跟另外其他一个 PE 进行通信。以下图 AMD NPU 为例(里面其实就是 AI Engine),它分成 memory tile(等价于 L2 memory) 和 compute tile,而 compute tile 上面有局部内存,不同的 compute tile 之间可以通过片上的交换盒(switch box)传输数据,一般是在相邻 PE 之间传输,而非相邻 PE 之间的数据传输则需要绕几个交换盒才能到达。
Dato 的编程模型
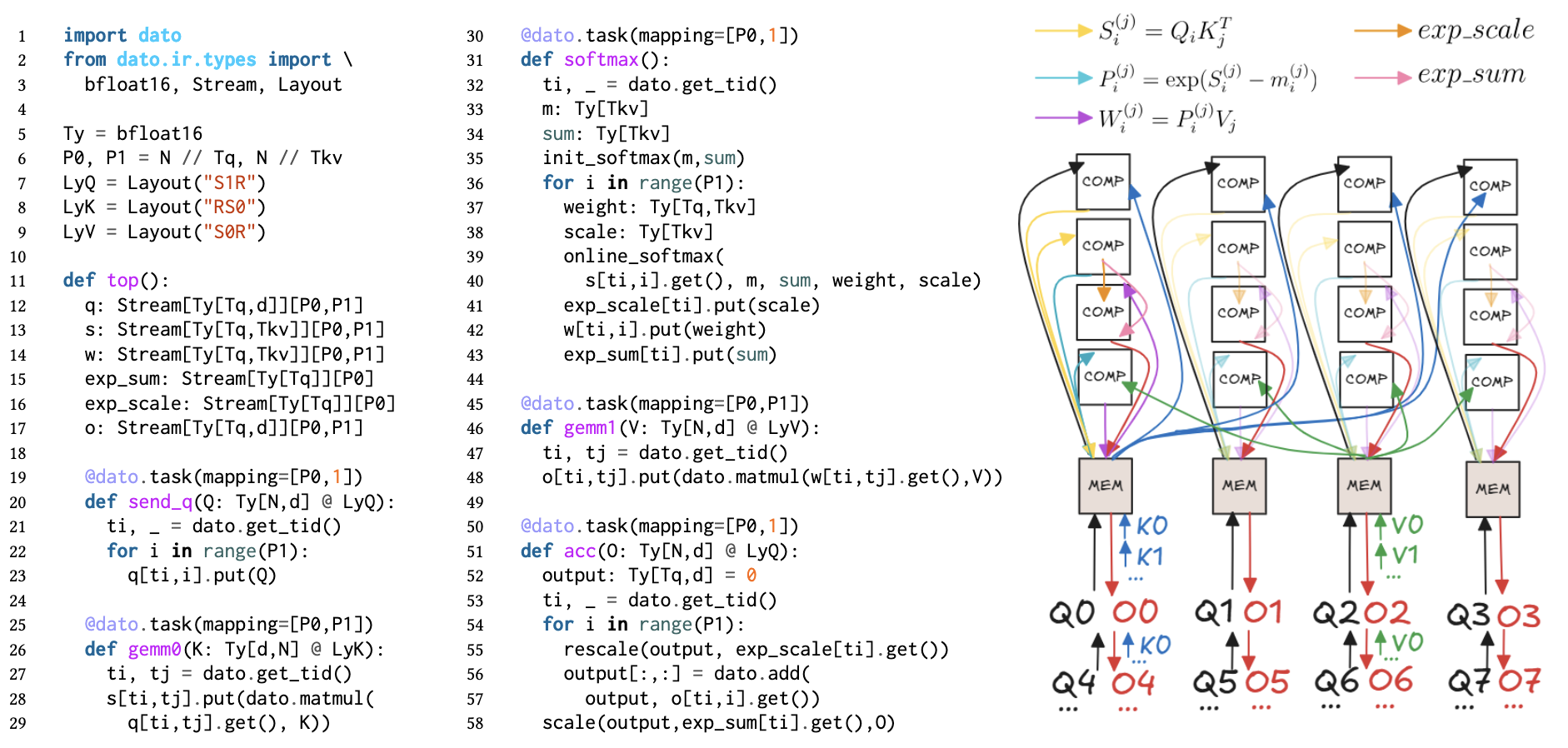
让我们回顾一下 Allo v1 的编程模型是怎么写的,如下面图(b)所示,我们希望实现多个 producer 和多个 consumer 的 pattern,我们会去给每个函数都定义一遍计算,然后手动分片后计算索引偏移并调用这些函数,最后再用.relay()原语(primitive)来构建数据流的连接。但很明显这里有几个问题:首先是函数定义其实差不多会有大量的重复代码;其次人工划分数据的逻辑其实非常规整,我们不需要手工计算每个函数所需要取的数据;最后从数组转到 FIFO 的过程也没有什么必要,如果我们一开始就已经知道某个连接就是 FIFO 的话,那为什么不直接对其进行定义呢?

基于上面三点考量,所以就有了 Dato 的写法,如图(c)所示,我们引入了Stream来表示数据流,用Layout来表示数据布局,然后用@task(mapping=...)来构建虚拟映射,用户在写程序时只需要定义一个 task 内部的执行逻辑,从而在保留语义的同时大幅减少代码量。
两个一等类型公民:Stream 与 Layout
为了描述 PE 和 PE 之间的通信,我们需要一个能够传输数据的对象,所以很直接地我们可以想到用一个定长数组去描述 FIFO,但同时我们又希望这个对象能够在编译时就进行一些检查,所以我们就干脆将其类型化,做成一个Stream类型,将其和其他 Allo 的基类型同等对待。而描述通信最简单的算子就是 send 和 recv,这里我们则是复用了 Tawa 里的写法用.put()和.get()来描述数据的写入和读取,但和 Tawa 不同的是,Dato 里我们直接描述的是整个 FIFO 的读写,并且直接暴露给前端用户去编程;而 Tawa 只是针对单一元素进行 aref 的构造,并且只是作为编译器内部的一个实现。
有了这个类型定义,进一步我们就可以通过线性类型系统(linear typing)保证通信的安全性——不会溢出、不会死锁,编译时就能检查出来(但这个类型检查是有局限性的,只能用在非常简单的程序上面),具体的 typing 规则可以见下图

简单来讲这里保证的是读写次数一致(通过Used和Free token 的数目保证),并且不会先读后写的情况。
解决了数据怎么流的问题,另一个问题则是数据怎么摆。因为大部分情况对不同 PE 内执行程序是同构的,即每个 PE 内的计算逻辑是一样的,不同的只是获取的数据,即所谓的 SPMD(Single Program Multiple Data),所以我们可以用一个非常规整的方案去分发数据。根据分布式编程的经验,最关键的其实是一个 tensor 在某个维度上是否有被分片(sharded),如果没有分片那就是重复的(replicated)。那么同样的,我们也可以用一个Layout类型来对数据划分进行包装,从而描述数据在不同 PE 之间的分布方式,比如可以指定某个维度在某个 PE 上进行分片,或者某个维度在所有 PE 上进行复制(R)。如下图的例子,这里我们复用 Alpa 的标记方式,用 S 描述分片,并用 R 描述复制,例如 “S1R” 表示第 0 维在设备轴 1 上分片,第 1 维复制。
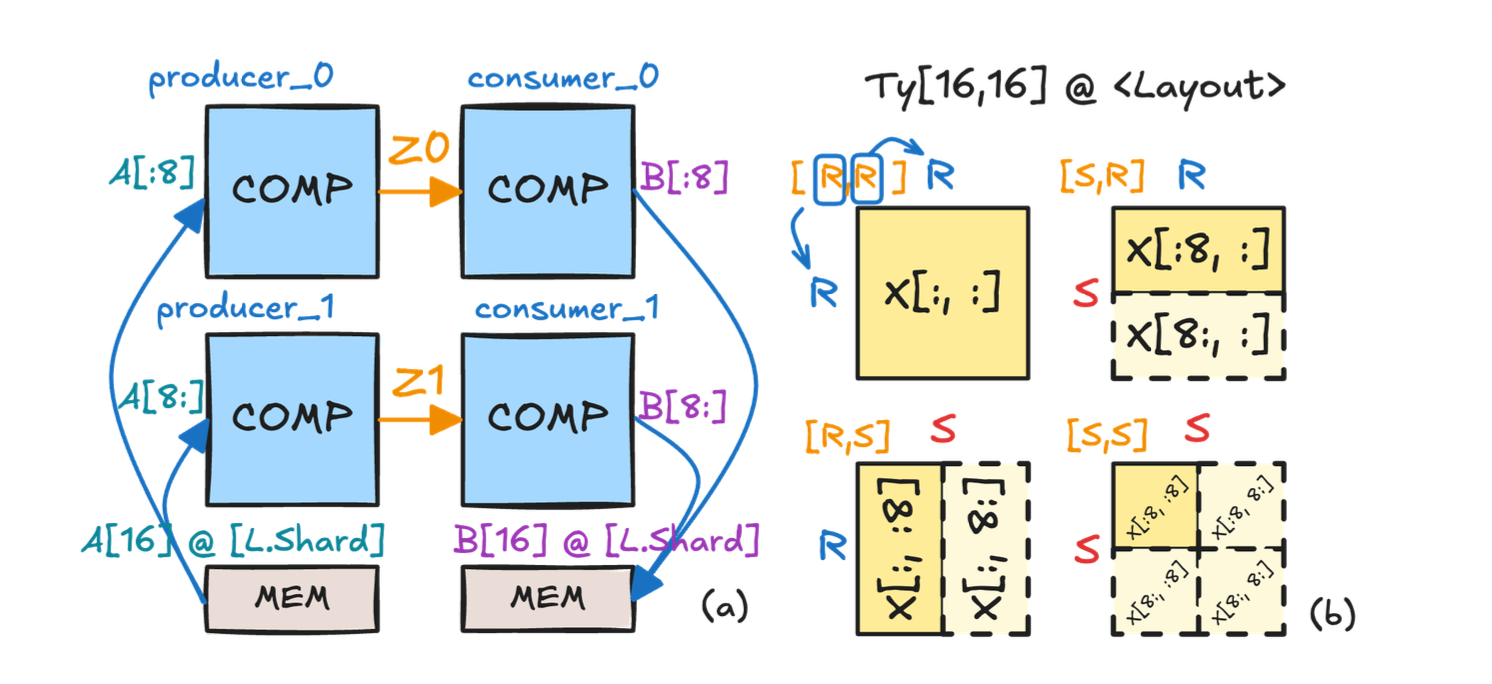
这里比较有意思的点是,我们将 layout 做成了原本 tensor 的一个 refinement type。这本质上是说,如果我们没有这个 refinement,那么这个 tensor 将会是最 general 的情况,即所有的 task 都拿到完整的整个 tensor;而如果标记了 S 的 layout,那意味着每个 kernel 拿到的就只是原本大 tensor 其中的一小部分了。把 layout 当成类型一等公民的好处也是显而易见的,我们很容易可以建立起一套类型推断的规则(如下图所示),然后进行更好的通信优化。这跟 Shardy 或者 PartIR 的想法很类似,但我们还是希望这个 layout 能够暴露给用户,这样用户能够更好地控制不同类型的数据排布。

虚拟映射到物理映射
有了前端的程序之后我们就可以考虑如何将其映射到实际的物理硬件上,但通常实际硬件通常会有更多的限制,比如物理 PE 的数量、端口数、内存带宽等,并没有办法保证用户开了多少 task 就都能一对一映射过去,所以我们就需要一个能够将虚拟映射(virtual mapping)映射到物理映射(physical mapping)的方案。
这里我们以下图(a)的 GEMM 程序为例,他做的事情其实是生成一个 3D mapping,每个 PE 上面都是做乘加,然后在第 2 个硬件轴上面对部分结果进行累加(allreduce),所以我们可以得到图(b)的虚拟映射及数据划分方式。
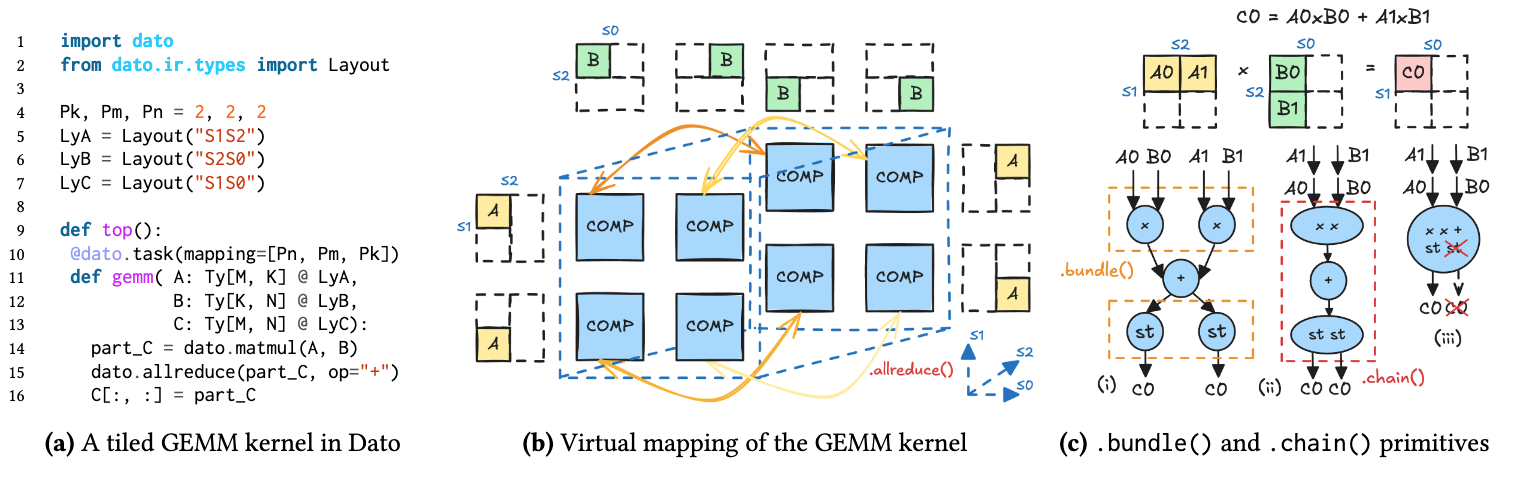
基于这个前端程序,我们可以进一步构建出一个虚拟映射图(Virtual Mapping Graph,VMG),图里的每个结点是一个 task,而每条边则定义了一个生产者-消费者的关系,而allreduce则会导致所有参与 reduce 的 task 结点都参与连接,所以针对这个程序我们可以得到图(c.i)的VMG。
这里我们引入了两个原语,.bundle()和.chain(),前者将多个同构的任务结点合并成一个分时复用的结点(相当于水平融合),后者将生产者-消费者节点融合成一个顺序执行的结点(相当于纵向融合)。
有了这两个原语的定义,我们就可以利用其对原本的 VMG 一步步进行折叠,直到最终结点的数目能够小于实际物理 PE 的数目,并且满足所有的通信限制,那我们就可以将这个折叠后的图里每个结点直接放到每个 PE 上进行执行。
而定义这些原语的好处还在于给用户充分的控制权去实现不同的 mapping 算法,通过这些原语理论上可以实现任意一种 mapping 方案,同时我们也可以很方便定义这个搜索空间,并交由编译器自动搜索最优折叠序列(论文中给出了一种暴力搜索的方案),在满足端口、内存等硬件约束的前提下,最大化利用计算资源。
为了进一步优化硬件性能,我们还专门针对 NPU 做了额外的一些优化,包括
- 内核注入:直接调用厂商提供的手调 C++ 向量内核
- 布局规范化:将一系列布局变换建模为代数运算,合并、消去冗余步骤,最小化格式转换开销
- DMA数据传输的优化:将能在 DMA 引擎中执行的布局操作,如打包、转置等,hoist 到 DMA 描述符中,在数据传输的同时完成格式变换
实验结果
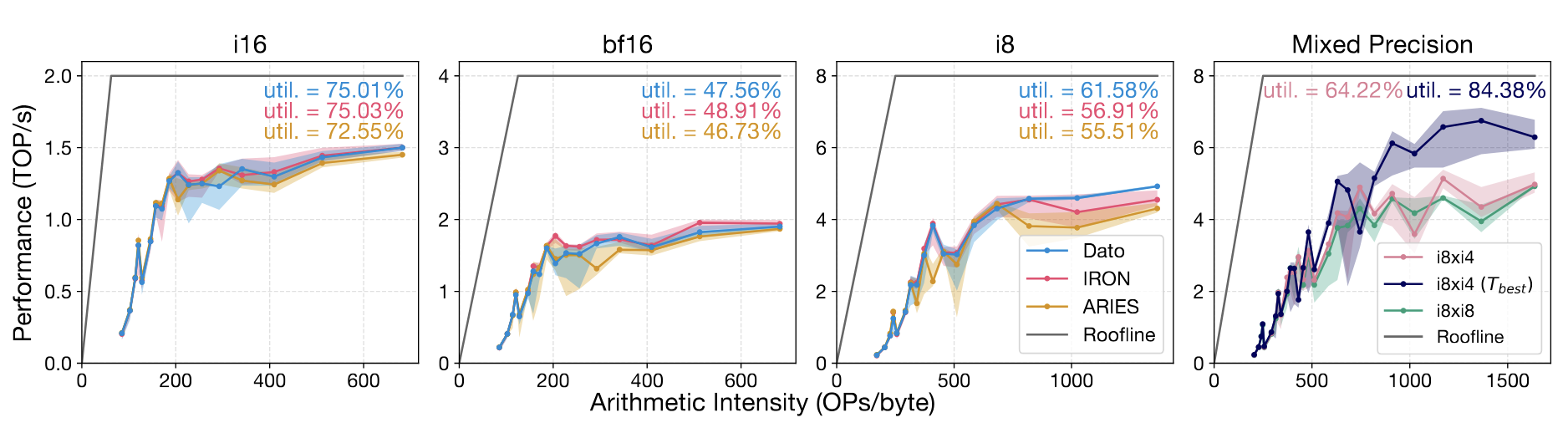
我们在 AMD Ryzen AI NPU(XDNA1)进行实验,从下面的图中可以看出,我们的性能基本跟手写 GEMM 性能是持平的(IRON 是基于 MLIR-AIE 的 Python wrapper),在正常精度下可以达到75%的硬件利用率,在混合精度下面的优势会更加明显(目前的 NPU 框架都没有办法做混合精度)。
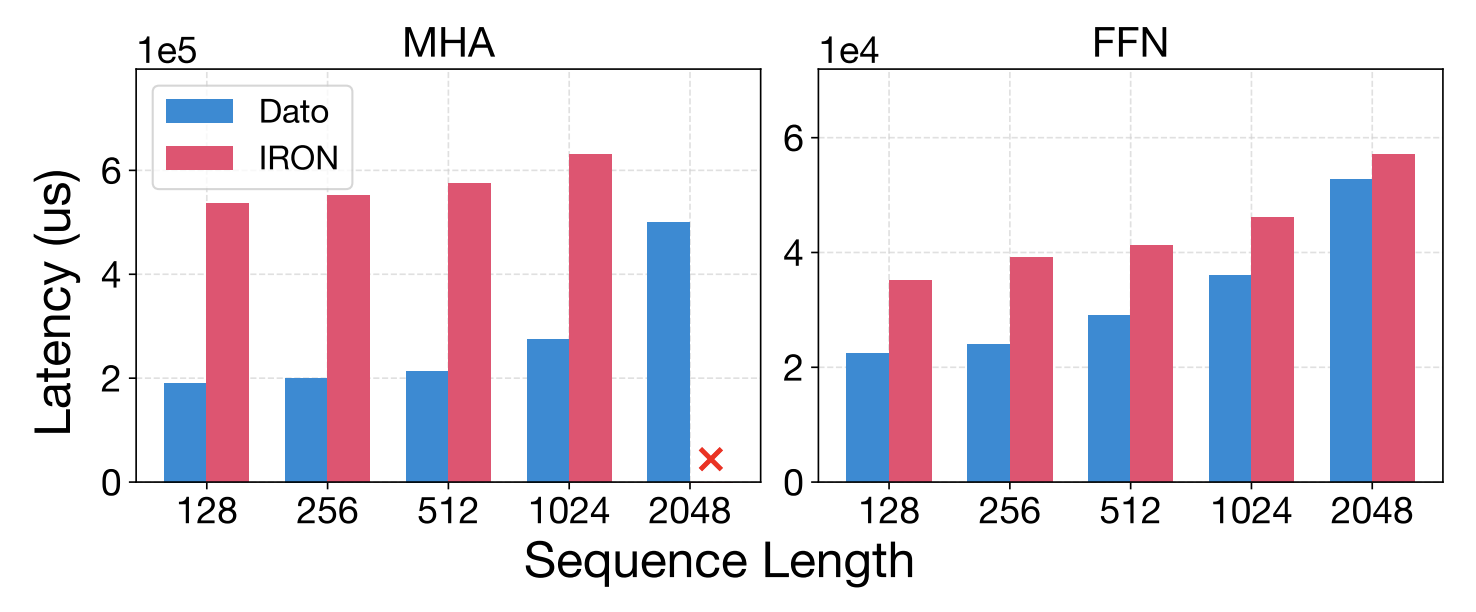
我们进一步在 NPU 上实现了 FlashAttention,这应该是第一次在 AMD NPU 上实现类似FlashAttention-3的 dataflow 架构。从下面的图中可以看出,我们的性能相比 IRON 提升 2.81 倍,同时代码量比 IRON 少 5倍(只需50行左右代码即可实现)。
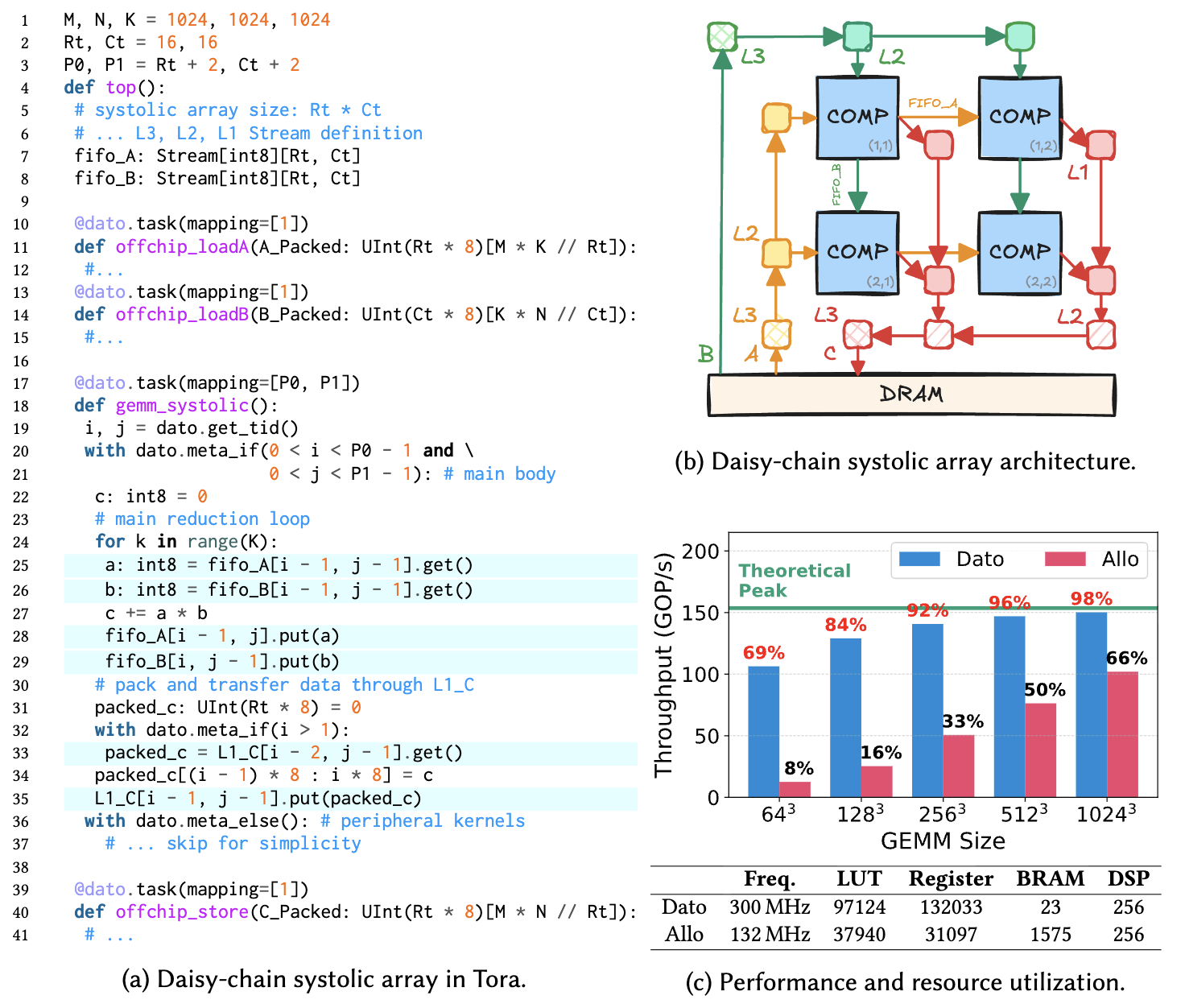
除了 NPU 之外,我们也验证了这套编程模型同样在硬件生成上面非常有效,我们利用 Dato 生成了一个 16×16 i8 daisy-chain 脉动阵列,运行在 300MHz,最终达到 98% 的理论峰值性能(150 GOP/s),比 Allo 快 8.2倍,且布线(routing)后仍满足时序。下图展示了代码片段以及最后的综合结果,可以看到我们依然还是可以用同样的 task 去描述每个 PE 上的计算,并且通过 Stream 建立连接,唯一的区别是面向硬件生成的 mapping 都直接是物理 PE,所以不再需要进行虚拟映射这一步操作。
讨论与未来展望
Dato 将“通信与布局作为类型一等公民”的编程模型给数据流架构提供了一种新的方案,让开发者能够更加方便地描述各种 communication 和 mapping 的模式。它不仅仅是一个编译器优化,更是一种编程范式的转变——让开发者用更符合硬件语义的方式描述计算,但又能同时享受高层语言的简洁与安全。其实现在可以看到无论是 Gluon 或者是 Pallas 等算子描述语言都在往这方面发展,与其让编译器自动做完所有优化,不如让用户更加方便地描述不同的优化方案。
目前 Dato 更多还是单一算子上的优化,而在我们挂出这篇论文没多久,AMD 官方就引用了我们的论文并指明通过更好的 tiling 方式我们是有办法进一步提升硬件利用率的。未来我们会进一步考虑全局图层面的优化,比如考虑多个算子之间怎么更好地进行时空域(spatial-temporal)的划分,从而实现更好的 mapping。另一方面则是支持更多数据流架构,包括接入 Tawa 实现对 GPU 的支持,同时面向 Cerebras WSE 等更大规模的数据流架构进行优化;以及利用这种 SPMD 模式针对硬件生成其实也有很多有意思的问题还可以继续探索。
致谢
我在25年上半年做了基本前端的语法定义和后端 NPU 的原型实现之后就去实习了,本来没想到这个项目会这么快收尾,暑假基本都是 Shihan 在 lead,她一个人重写了整个 NPU 后端,并且在 Allo 里面做了大量的优化最终达到跟手写 GEMM 一样的性能,而且这都在两三个月时间里就完成了,属实功不可没。另外也要感谢另外几位实习生 Han/Adrian/Weiran 在实验上的大力辅助,这个 project 才能完美收尾。
-
小彩蛋是我老板给我三个 project 都起了恐龙名字的缩写,Allo、Tawa 和 Dato 正好对应着我 PhD 期间做的三种异构设备(FPGA、GPU、NPU)的优化,属实是侏罗纪公园三部曲了 :) ↩