Hongzheng Chen Blog
图表示学习(3)- 图神经网络系统
Mar 4th, 2020 0这是图表示学习(representation learning)的第三部分——图神经网络系统,主要涉及2019-2020年顶会上面的工作。(更新于2020年12月)
Pytorch Geometric (PyG)1
从前一节介绍的GNN可以发现,GNN实际上都是一个邻居聚合或消息传递的过程,用下式表达
\[\mathbf{v}_i^{(k+1)}=\gamma\left(\mathbf{v}_i^{(k)},\mathop{Agg}_{j\in\mathcal{N}_i}\phi(\mathbf{v}_i^{(k)},\mathbf{v}_j^{(k)},\mathbf{e}_{j,i}^{(k)})\right)\]其中$Agg$是一个可微、置换不变的函数(求和、求平均、求最值),$\gamma$和$\phi$则是可微函数(如MLP)。
PyG在PyTorch上实现,最核心的类是torch_geometric.nn.MessagePassing,用户只需定义消息传递$\phi$(message())、更新函数$\gamma$(update())和聚合函数$Agg$即可。
GCN的传播规则用向量可表成
\[\mathbf{x}_i^{(k)} = \sum_{j \in \mathcal{N}(i) \cup \{ i \}} \frac{1}{\sqrt{\deg(i)} \cdot \sqrt{\deg(j)}} \cdot \left( \mathbf{\Theta} \cdot \mathbf{x}_j^{(k-1)} \right)\]进而可表示成gather和scatter的两个过程。

因此可以对照着实现代码
import torch
import torch.nn.functional as F
from torch_geometric.nn import MessagePassing
from torch_geometric.utils import add_self_loops, degree
class GCNConv(MessagePassing):
def __init__(self, in_channels, out_channels):
super(GCNConv, self).__init__(aggr='add') # "Add" aggregation.
self.lin = torch.nn.Linear(in_channels, out_channels)
def forward(self, x, edge_index):
# x has shape [N, in_channels]
# edge_index has shape [2, E]
# Step 1: Add self-loops to the adjacency matrix.
edge_index, _ = add_self_loops(edge_index, num_nodes=x.size(0))
# Step 2: Linearly transform node feature matrix.
x = self.lin(x)
# Step 3-5: Start propagating messages.
return self.propagate(edge_index, size=(x.size(0), x.size(0)), x=x)
def message(self, x_j, edge_index, size):
# x_j has shape [E, out_channels]
# Step 3: Normalize node features.
row, col = edge_index
deg = degree(row, size[0], dtype=x_j.dtype)
deg_inv_sqrt = deg.pow(-0.5)
norm = deg_inv_sqrt[row] * deg_inv_sqrt[col]
return norm.view(-1, 1) * x_j
def update(self, aggr_out):
# aggr_out has shape [N, out_channels]
# Step 5: Return new node embeddings.
return aggr_out
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = GCNConv(dataset.num_features, 16)
self.conv2 = GCNConv(16, dataset.num_classes)
def forward(self):
x, edge_index, edge_weight = data.x, data.edge_index, data.edge_attr
x = F.relu(self.conv1(x, edge_index, edge_weight))
x = F.dropout(x, training=self.training)
x = self.conv2(x, edge_index, edge_weight)
return F.log_softmax(x, dim=1)
但很明显由于抽象的问题,权重矩阵被大量重复计算了(Step 2),如果是先聚合再进行变换则权重矩阵只需计算一次,可以对照着上一节GCN的公式看。
目前PyG最新发布版本为v1.4.2 (Feb 18, 2020),从源码来看似乎全部程序都是用Python写的,所以某种程度上造成了效率不高。但是原作者还在Github上发布了其他几个相关的库,包括torch-scatter、torch-sparse、torch-spline-conv、torch-cluster等,所以可能优化工作都在这几个库里完成了(确实CUDA和C++代码都在这些附加库里…)。
相关资料可以在下面链接找到:
- 源代码:https://github.com/rusty1s/pytorch_geometric
- Tutorial:https://pytorch-geometric.readthedocs.io/en/latest/notes/create_gnn.html
- 文档:https://pytorch-geometric.readthedocs.io/
- 论文:https://arxiv.org/abs/1903.02428
Deep Graph Library (DGL)[^2]
DGL和PyG都是目前运用得最广泛的图神经网络库,它们的思想都差不多,但各有优劣。比如DGL是无关平台(platform-agnostic)的,只要底层是深度学习库,都可以灵活支持;且支持随机游走和随机采样。
DGL将消息传递的式子拆分成对边应用(edge-wise)和对结点应用(node-wise)
\[\begin{cases} \mathbf{m}_i^{(k+1)} = \phi^e\left(\mathbf{v}_i^{(k)},\mathbf{v}_j^{(k)},\mathbf{e}_{j,i}^{(k)}\right)\\\\ \mathbf{v}_i^{(k+1)} = \phi^v\left(\mathbf{v}_i^{(k)},\mathop{Agg}_{j\in\mathcal{N}_i}\mathbf{m}_i^{(k+1)}\right) \end{cases}\]其中$\phi^e$是消息函数,$\phi^v$是更新函数。
先前的库都需要用户用稀疏矩阵(CSR/COO)来存储图,稠密张量来存储特征,大量的底层设施会暴露给用户;而DGL选择不这么干,底层设施都交由运行时系统进行管理。
还是经典的GCN例子:
import dgl
import dgl.function as fn
import torch.nn as nn
import torch.nn.functional as F
class GCNLayer(nn.Module):
def __init__(self, in_feats, out_feats, dropout=False, norm=True):
super(GCNLayer, self).__init__()
# https://pytorch.org/docs/stable/nn.html#torch.nn.Linear
# x A^T + b
self.linear = nn.Linear(in_feats, out_feats)
self.dropout = dropout
if self.dropout:
self.dropout = nn.Dropout(p=0.5) # need more time!
self.norm = norm
def forward(self, g, h):
# hat_D hat_A H W hat_D
# g is the graph and the inputs is the input node features
# first set the node features
if self.dropout:
h = self.dropout(h)
h = self.linear(h)
if self.norm:
g.ndata['h'] = g.ndata['norm'] * h
else:
g.ndata['h'] = h
# trigger message passing on all edges
# Edge UDF: EdgeBatch -> dict, notice it acts on a batch of nodes
# g.edges() indicates sending along all the edges
g.update_all(
message_func=fn.copy_src(src='h', out='m'),
# {'m': edges.src['h']}
reduce_func=fn.sum(msg='m', out='h')
# {'h': torch.sum(nodes.mailbox['m'], dim=1)}
)
# get the result node features
h = g.ndata.pop('h')
if self.norm:
h = h * g.ndata['norm']
# perform linear transformation
return h
class GNN(nn.Module):
def __init__(self, in_feats, hidden_size, num_classes):
super(GNN, self).__init__()
self.gcn1 = GCNLayer(in_feats, hidden_size, False, False)
self.gcn2 = GCNLayer(hidden_size, num_classes, False, False)
def forward(self, g, inputs):
h = self.gcn1(g, inputs)
h = torch.relu(h)
h = self.gcn2(g, h)
return h
实验平台是单Tesla V100 GPU和8块CPU (AWS EC2 p3.2xlarge实例)。最大的图是Reddit,232K个结点、114M条边。
在实验部分稍微提及使用了kernel fusion和NUMA架构(MXNET版)。可能是会议的原因,这两篇投在ICLR上的文章基本上就介绍了一个抽象,做了些实验就结束了,也搞不清楚为什么能得到这么高的加速比;相比之下系统会议的论文真的会详细很多。
(不过复现了GCN的论文,确实是可以近似匹配到官方论文的结果,而且用我电脑跑CPU的速度似乎比GCN原始论文TensorFlow用GPU跑还要快?从侧面似乎说明DGL的速度非常快…)
相关资料见下:(Apache License,陈天奇参与了开源;因为人手众多,所以感觉比PyG要维护得好一些)
- 源代码:https://github.com/dmlc/dgl
- 官网:http://dgl.ai/
- 文档:https://docs.dgl.ai/
- Tutorial:https://docs.dgl.ai/tutorials/basics/1_first.html (这个教程比PyG的要友好很多,直接用Zachary’s Karate Club作为例子)
DGL运行时系统采用的技术:
- 核融合:https://www.dgl.ai/blog/2019/05/04/kernel.html
- 虚拟机:https://discuss.dgl.ai/t/runtime-documentation/552
Euler[^3]
Alibaba基于TensorFlow开发的图系统,提供了Python和C++接口,并开源在Github上,未有相关论文,但是功能比较齐全。
NeuGraph[^4]
深度学习系统最大问题在于没有办法高效表示图数据,而图系统最大的问题在于没法自动微分!
现有用得最广泛的框架是前面两个框架DGL和PyG,但(早期版本的)DGL和PyG只是提供了一个编程框架(面向图的消息传递模型),并没有深度解决计算的问题(这很大程度也是GCN很难火起来的原因,因为无法做到很高的可扩展性)。在GCN的原作实现和GraphSAGE的原作实现中,都使用了TensorFlow进行编程,但是他们所采用的方法都是简单暴力的矩阵乘,这样其实很大程度忽略了图计算框架这些年取得的成果。因此NeuGraph的出现也正是为了弥合这两者,将图计算与深度学习有机地融合起来。(某种意义上,这也是matrix-based和matrix-free两种方法的对碰。)
(之前以为腾讯的Plato作为企业级图系统,应该可以支持GNN的计算,然而Plato只是将Gemini和KnightKing套了个壳,所以目前也只支持这两个框架所支持的算法,即传统的图算法以及随机游走。)
NeuGraph把常见的GNN分为三类:图卷积、图循环、图注意力网络。 进而提出了SAGA-NN (Scatter-ApplyEdge-Gather-ApplyVertex with Neural Networks)编程模型,其中SAGA部分属于图计算的消息传递,而两个A则是深度学习神经网络的应用。

由于GCN相比起传统的图算法来说(在图计算层面上)要简单很多,就是对全图不断进行遍历,因此Scatter和Gather是确定的,而两个Apply阶段则是用户自定义的函数。(所以似乎NeuGraph没法实现GraphSAGE,因为GraphSAGE的邻居是由一定策略采样出来的,而不是取全部邻居)。
GPU Execution
目前的深度学习框架都很难处理大图,因为GPU的内存无法存储这么大规模的图,因此NeuGraph在数据流抽象的基础上进行了图划分。
(关于计算硬件,这里是值得考虑的。GPU在稠密矩阵计算上具有先天优势,但如果换成稀疏阵优势是否还存在呢。图处理框架的发展证明了CPU集群有办法承担大规模的图计算任务,从这种角度来看的话是否CPU在GNN的处理上也更存在优势呢?或者更加激进地,利用FPGA实现这样既能高效遍历又能高效算矩阵的架构是否有办法呢?)
简而言之,按边划分为chunk(准确来说是把邻接阵按列划分),然后送到不同的GPU上进行计算,下面补充了几点文中提到的优化方法(streaming out of GPU core):
- 使用selective scheduling,先用CPU筛一遍有用的边,再把这些边送去GPU算
- 为了确保足够的局部性,采用了Kernighan-Lin算法进行图划分(METIS包),确保同一个chunk中的大部分边都连向同一个节点
- 用pipeline scheduling最大程度重叠IO和计算时间
Experiments
NeuGraph在TensorFlow上实现,包含5000行的C++代码和3000行的Python代码。实验服务器2*28核CPU+512G内存+8块NVIDIA Tesla P100 GPU(单机多卡)。最大的数据集为Amazon,8.6M的顶点和231.6M的边,特征96,类别22。
比较对象包括TensorFlow、GraphSAGE、DGL,提速比在2.5倍到8.1倍之间(单GPU),但没有办法跟多GPU的Tensorflow比,因为直接爆内存了。而不加优化的多GPU版TF-SAGA大概比NerGraph慢2.4到4.9倍,这一部分才比较客观地表明提出的优化方法的高效性。
AliGraph[^5]
AliGraph是Alibaba内部的图计算系统,已经是商用在淘宝各种预测任务上,并且取得了很好的效果。这篇文章则是从算法到底层系统逐一分析的集大成者。(注意是在CPU上跑)
它提出目前GNN面临着四个问题:大规模、异构、属性、动态图。
关于GNN的抽象,AliGraph就比NeuGraph要做得更好一些,因为他们考虑到了采样过程。

而整体的系统架构从上到下包括应用层、算法层、算子层、采样层和存储层,如下图。
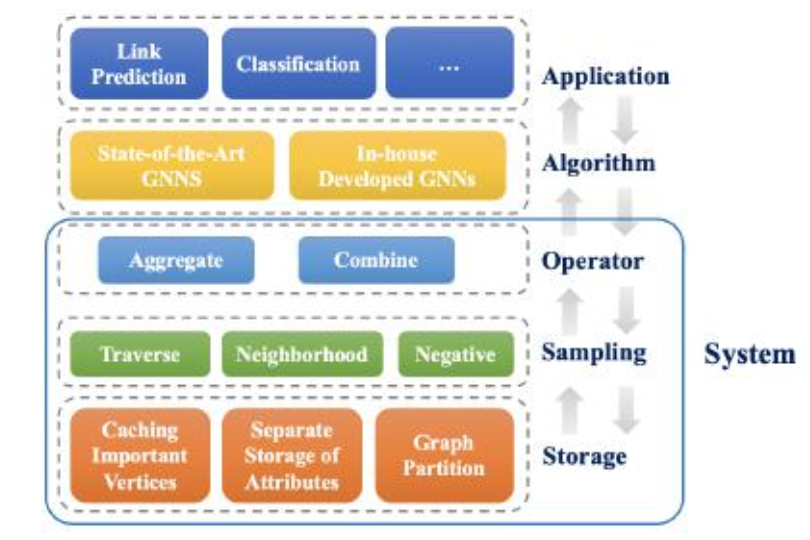
Storage Level
- 图划分:采用了四种方法(METIS、顶点/边割、2D划分、流式划分),由用户自行选择
- 图属性存储:很棒,AliGraph考虑到了图结构(structure)和图属性(attribute)的存储方式(解耦了!),见下图,以索引方式并分开两个表存,这就很数据库了(确保第二范式)。也许会牺牲一定的计算时间,但是考虑到数据量过大,同时属性信息千奇百怪,因此这样存储可能是比较合适的。论文作者也考虑到访问时间的问题,因此加了两个cache在这,用LRU策略。
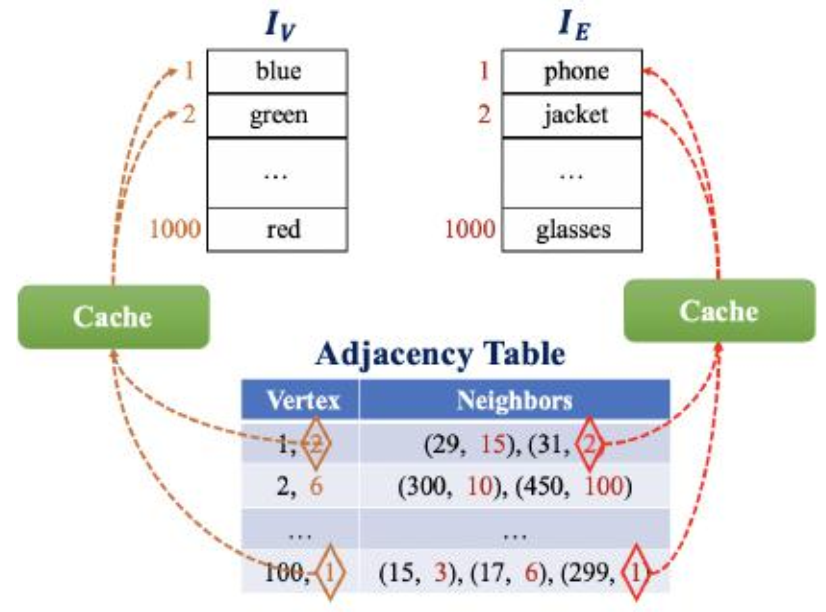
- 缓存邻居结点:通过计算一个指标来衡量(结点的$k$跳入度除以$k$跳出度),选指标最大的那些进行缓存
Sampling Level
考虑三种采样方式:Traverse、Neighborhood、Negative,都是直接调用别人的库。
Operator Level
包括Aggreate和Combine两种方式,对应的就是不同种类的GNN。
Conclusions
这篇文章有种虎头蛇尾的感觉,实验部分连实验平台都没有提,也没有提AliGraph是怎么实现的(当时去参加CNCC’19印象中是他们直接在TensorFlow上搭建),更多是像在推销自家提出来的几种GNN有多强。说实话没有太多系统层面的优化,都是直接套用别人的东西,然后融合为几个层就结束了,更没有考虑层与层之间的交互。也许本文当成综述性的文章更为合适,不过它也确实提到了现在这些互联网大厂在关心什么问题,以及他们的解决思路。
PBG [^6]
PyTorch-BigGraph是一个图嵌入系统,其中提到参数服务器的三个问题:
- 消耗大量网络带宽
- 限制单机执行的模型
- 可能有收敛性问题
改进负采样方法,减少内存访问,分布式执行,但只对比了传统的图嵌入方法如DeepWalk,而没有对比GNN。
无法针对属性图。
ROC [^7]
这份工作是很典型的ML for ML system的文章,ROC没有采用子图采样的方法,而是用全图训练,通过划分来支持分布式多GPU
- 图划分:online linear regression model -> maximize coalesced accesses to GPU device memor
- 内存管理:用动态规划确定GPU上要cache哪些中间结果
PaGraph [^8]
基于采样的GNN
- partition
- cache
AGL [^9]
FeatGraph [^10]
编译器TVM
Reference
Matthias Fey, Jan E. Lenssen (Dortmund)
ICLR workshop on Representation Learning on Graphs and Manifolds, 2019, Code
[^2]: Deep Graph Library: Towards Efficient and Scalable Deep Learning on Graphs
Minjie Wang (NYU), Lingfan Yu, Da Zheng, Quan Gan, Yu Gai, Zihao Ye, Mufei Li, Jinjing Zhou, Qi Huang, Chao Ma, Ziyue Huang, Qipeng Guo, Hao Zhang, Haibin Lin, Junbo Zhao, Jinyang Li, Alexander Smola, Zheng Zhang
ICLR, 2019, Code
[^3]: Euler
Alibaba
[^4]: NeuGraph: Parallel Deep Neural Network Computation on Large Graphs
Lingxiao Ma, Zhi Yang, Youshan Miao, Jilong Xue, Ming Wu, Lidong Zhou (MSRA), Yafei Dai (PKU)
ATC, 2019
[^5]: AliGraph: A Comprehensive Graph Neural Network Platform
Rong Zhu, Kun Zhao, Hongxia Yang, Wei Lin, Chang Zhou, Baole Ai, Yong Li, Jingren Zhou (Alibaba)
VLDB, 2019, Code
[^6]: Pytorch-BigGraph: A Large Scale Graph Embedding System
Adam Lerer, Ledell Wu, Jiajun Shen, Timothee Lacroix, Luca Wehrstedt, Abhijit Bose, Alex Peysakhovich (Facebook AI Research)
MLSys, 2019, Code
[^7]: Improving the Accuracy, Scalability, and Performance of Graph Neural Networks with Roc
Zhihao Jia, Sina Lin, Mingyu Gao, Matei Zaharia, and Alex Aiken (Stanford)
MLSys, 2020, Code
[^8]: PaGraph: Scaling GNN Training on Large Graphs via Computation-Aware Caching
Zhiqi Lin, Cheng Li, Youshan Miao, Yunxin Liu, and Yinlong Xu (USTC)
SoCC, 2020
[^9]: AGL: A Scalable System for Industrial-Purpose Graph Machine Learning
Dalong Zhang, Xin Huang, Ziqi Liu, Jun Zhou, Zhiyang Hu, Xianzheng Song, Zhibang Ge, Lin Wang, Zhiqiang Zhang, and Yuan Qi (Ant Financial Services Group)
VLDB, 2020
[^10]: FeatGraph: A Flexible and Efficient Backend for Graph Neural Network Systems
Yuwei Hu (Cornell), Zihao Ye, Minjie Wang, Jiali Yu, Da Zheng, Mu Li, Zheng Zhang, Zhiru Zhang, and Yida Wang (Amazon)
SC, 2020, Code
[^11]: G3: When Graph Neural Networks Meet Parallel Graph Processing Systems on GPUs
Husong Liu, Shengliang Lu, Xinyu Chen, Bingsheng He (National University of Singapore)
SIGKDD Demo, 2020, Code
[^12]: Reducing communication in graph neural network training
Alok Tripathy, Katherine Yelick, and Aydın Buluç (UCB)
SC, 2020, Code
[^13]: GE-SpMM: general-purpose sparse matrix-matrix multiplication on GPUs for graph neural networks
Guyue Huang, Guohao Dai, Yu Wang, Huazhong Yang (Tsinghua)
SC, 2020, Code
[^14]: Understanding and Bridging the Gaps in Current GNN
Kezhao Huang, Jidong Zhai (Tsinghua)
PPoPP, 2021
[^15]: GraphScope: A System for Interactive Analysis on Distributed Graphs Using a High-Level Language
Zhengping Qian, Chengqiang Min, Longbin Lai, Yong Fang, Gaofeng Li, Youyang Yao, Bingqing Lyu, Zhimin Chen, Jingren Zhou (Alibaba)
NSDI, 2021, Code